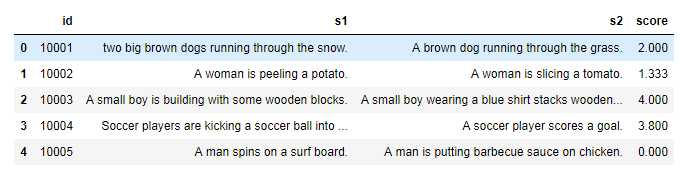
本次项目提供一系列的英文句子对,每个句子对的两个句子,在语义上具有一定的相似性;每个句子对,获得一个在0-5之间的分值来衡量两个句子的语义相似性,打分越高说明两者的语义越相近。
如:
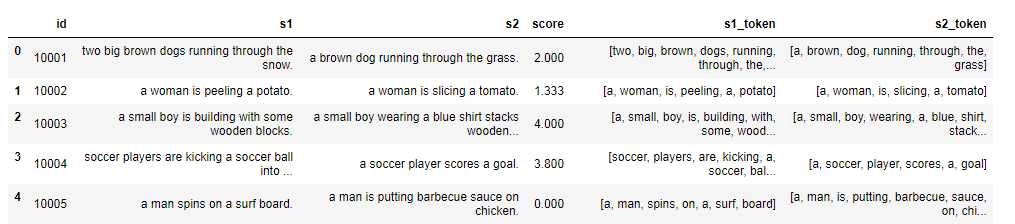
(2)去停用词:停用词是一些完全没有用或者没有意义的词,例如助词、语气词等。stopword就是类似 a/an/and/are/then 的这类高频词,高频词会对基于词频的算分公式产生极大的干扰,所以需要过滤
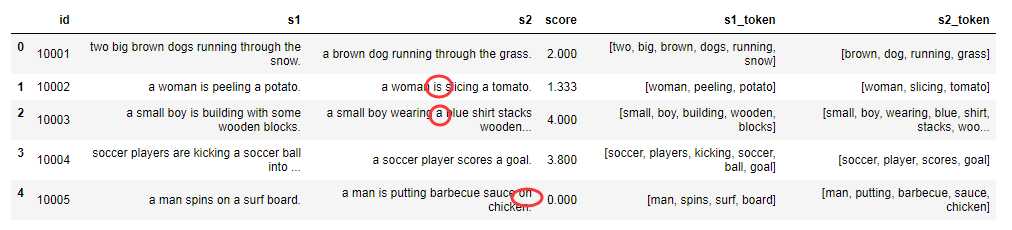
(3)词行还原:词干提取( Stemming ) 这是西方语言特有的处理,比如说英文单词有 单数复数的变形,-ing和-ed的变形,但是在计算相关性的时候,应该当做同一个单词。比如 apple和apples,doing和done是同一个词,提取词干的目的就是要合并这些变态
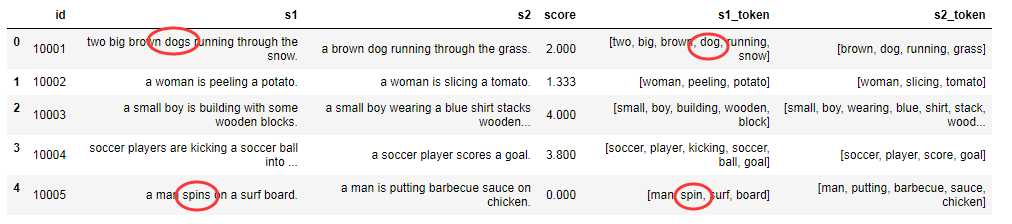
(4)词干化:
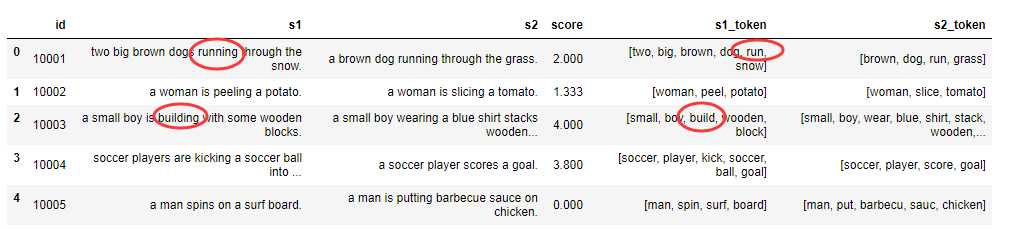
其中上述过程的代码如下:
def data_cleaning(data): data["s1"] = data["s1"].str.lower() data["s2"] = data["s2"].str.lower() # 分词 tokenizer = RegexpTokenizer(r‘[a-zA-Z]+‘) data["s1_token"] = data["s1"].apply(tokenizer.tokenize) data["s2_token"] = data["s2"].apply(tokenizer.tokenize) # 去停用词 stop_words = stopwords.words(‘english‘) def word_clean_stopword(word_list): words = [word for word in word_list if word not in stop_words] return words data["s1_token"] = data["s1_token"].apply(word_clean_stopword) data["s2_token"] = data["s2_token"].apply(word_clean_stopword) # 词形还原 lemmatizer=WordNetLemmatizer() def word_reduction(word_list): words = [lemmatizer.lemmatize(word) for word in word_list] return words data["s1_token"] = data["s1_token"].apply(word_reduction) data["s2_token"] = data["s2_token"].apply(word_reduction) # 词干化 stemmer = nltk.stem.SnowballStemmer(‘english‘) def word_stemming(word_list): words = [stemmer.stem(word) for word in word_list] return words data["s1_token"] = data["s1_token"].apply(word_stemming) data["s2_token"] = data["s2_token"].apply(word_stemming) return data
2.2 传统方法的使用:
(1)bag of words:其中具体的描述可以在这里看到:bag of words详解
# bag of words from sklearn.feature_extraction.text import CountVectorizer def count_vector(words): count_vectorizer = CountVectorizer() emb = count_vectorizer.fit_transform(words) return emb, count_vectorizer bow_data = data bow_data["words_bow"] = bow_data["s1"] + bow_data["s2"] bow_test = bow_data[bow_data.score.isnull()] bow_train = bow_data[~bow_data.score.isnull()] list_test = bow_test["words_bow"].tolist() list_train = bow_train["words_bow"].tolist() list_labels = bow_train["score"].tolist() from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(list_train, list_labels, test_size=0.2, random_state=42) X_train_counts, count_vectorizer = count_vector(X_train) X_test_counts = count_vectorizer.transform(X_test) test_counts = count_vectorizer.transform(list_test) # print(X_train_counts.shape, X_test_counts.shape, test_counts.shape)
(2) TF-IDF:其中具体的描述可以在这里看到:TF-IDF详解
# TF-IDF from sklearn.feature_extraction.text import TfidfVectorizer import scipy as sc def tfidf(data): tfidf_vectorizer = TfidfVectorizer() train = tfidf_vectorizer.fit_transform(data) return train, tfidf_vectorizer tf_data = data tf_data["words_tf"] = tf_data["s1"] + tf_data["s2"] tf_test = tf_data[tf_data.score.isnull()] tf_train = tf_data[~tf_data.score.isnull()] list_tf_test = tf_test["words_tf"].tolist() list_tf_train = tf_train["words_tf"].tolist() list_tf_labels = tf_train["score"].tolist() X_train, X_test, y_train, y_test = train_test_split(list_tf_train, list_tf_labels, test_size=0.2, random_state=42) X_train_tfidf, tfidf_vectorizer = tfidf(X_train) X_test_tfidf = tfidf_vectorizer.transform(X_test) test_tfidf = tfidf_vectorizer.transform(list_test)
然后通过一些基本的回归算法,进行训练和预测即可;
3
3.1 使用Word2Vec模型的训练:
通过给定的语料库,来训练一个词向量的模型,用于后期对句子进行词向量的表示:并且使用余弦相似度对句子相似度进行打分,不同于前面的是,通过word2vec方法所进行的是无监督学习,因此对于元数据中给的score并没有使用;
(1)这里首先给出所使用的语料:


path_data = "text_small" path_train_lab = "train_ai-lab.txt" path_test_lab = "test_ai-lab.txt" path_other_lab = "sicktest" def get_sentences(): """ 获取文件中句子作为语料库使用 :return: """ sentences = [] with open(path_train_lab) as file: for line in file: item = line.split(‘\t‘) sentences.append(prep_sentence(item[1])) sentences.append(prep_sentence(item[2])) with open(path_test_lab) as file: for line in file: item = line.split(‘\t‘) sentences.append(prep_sentence(item[1])) sentences.append(prep_sentence(item[2])) # # 添加额外语料 # with open(path_other_lab) as file: # for line in file: # item = line.split(‘\t‘) # sentences.append(prep_sentence(item[0])) # sentences.append(prep_sentence(item[1])) # sentences += word2vec.Text8Corpus(path_data) return sentences
(2)训练模型:
def train_w2v_model(sentences): """ 训练w2v模型 :param sentences: 语料 :return: """ # logging.basicConfig(format=‘%(asctime)s : %(levelname)s : %(message)s‘, level=logging.INFO) model = Word2Vec(sentences, size=200, min_count=1, iter=2000, window=10) model.save("w2v.mod")
(1)基于余弦距离直接计算句子相似度:
通过直接对句子中所有词向量加和求均值,作为句向量,直接计算两个句向量的余弦距离,作为最终的结果,发现在不做额外处理的情况下基本可以到达0.7左右的分值。
def get_w2v_result(): """ 通过w2v后根据余弦相似度预测句子相似度打分 :return: 输出 测试机的id 训练集的预测结果, 对测试集的预测结果, 训练集的标签 """ model_loaded = Word2Vec.load(‘w2v.mod‘) x_train = [] y_train = [] x_test = [] with open(path_train_lab) as file: for line in file: item = line.split(‘\t‘) score = model_loaded.n_similarity(prep_sentence(item[1]), prep_sentence(item[2])) x_train.append(float(round(score * 5, 2))) y_train.append(float(item[3])) idx = [] with open(path_test_lab) as file: for line in file: item = line.split(‘\t‘) score = model_loaded.n_similarity(prep_sentence(item[1]), prep_sentence(item[2])) x_test.append(float(round(score * 5, 2))) idx.append(item[0]) # 计算预测结果 r, p = pearsonr(x_train, y_train) print(‘Result w2v:r‘, r) return idx, x_train, x_test, y_train
(2)基于岭回归的方案:
考虑题目中所给出的训练数据是有标签的,而上述所使用的方法是完全非监督的,因此我们这里将使用余弦相似度的方法换成通过对句向量及其标签进行岭回归,同时观察结果,发现此类方法较上述方法稍有提升。
def get_LR_result(dataCounter): """ 通过词向量处理后使用岭回归进行监督预测 :return: 输出 测试机的id 训练集的预测结果, 对测试集的预测结果, 训练集的标签 """ model_loaded = Word2Vec.load(‘w2v.mod‘) x_train = [] y_train = [] # 使用训练数据训练模型 with open(path_train_lab) as file: for line in file: item = line.split(‘\t‘) matr1 = get_weighted_sent(dataCounter, prep_sentence(item[1]), model_loaded) matr2 = get_weighted_sent(dataCounter, prep_sentence(item[2]), model_loaded) data1 = matutils.unitvec(np.array(matr1).mean(axis=0)) data2 = matutils.unitvec(np.array(matr2).mean(axis=0)) data = [abs(num) for num in data1 - data2] # 计算词向量均值差作为特征 x_train.append(data) y_train.append(float(item[3])) idx = [] x_test = [] with open(path_test_lab) as file: for line in file: item = line.split(‘\t‘) matr1 = get_weighted_sent(dataCounter, prep_sentence(item[1]), model_loaded) matr2 = get_weighted_sent(dataCounter, prep_sentence(item[2]), model_loaded) data1 = matutils.unitvec(np.array(matr1).mean(axis=0)) data2 = matutils.unitvec(np.array(matr2).mean(axis=0)) data = [abs(num) for num in data1 - data2] # 计算词向量均值差作为特征 x_test.append(data) idx.append(item[0]) x_train, x_test = LR(x_train, y_train, x_test) return idx, x_train, x_test, y_train def LR(x_train, y_train, x_test): """ 使用岭回归训练模型进行监督学习 :param x_train: 训练集 训练数据 :param y_train: 训练集 打分 :param x_test: 测试集 测试数据 :return: """ clf = linear_model.Ridge() alpha_can = np.logspace(-3, 2, 10) clf = GridSearchCV(clf, param_grid={‘alpha‘: alpha_can}, cv=5) # 交叉验证 clf.fit(x_train, y_train) pred_x_train = clf.predict(x_train) pred_x_test = clf.predict(x_test) r, p = pearsonr(pred_x_train, y_train) # 直接结果输出 print(‘Result LR:‘, r) return pred_x_train, pred_x_test
(3)基于加权词向量的方案:
最后通过阅读论文,我们发现ICLR2017 A simple but tough-to-beat baseline for sentence embedding中恰好有考虑了对词向量进行加权的研究,其重要思路为通过词频对词向量重要程度进行衡量,并在句向量形成过程中进行加权,再通过除去数据中PCA的第一主成分,达到非常好的效果,因此我们队该方案进行了复现,并且用于对本次项目的预测,但是奇怪的是我们的实验结果并且有达到想象中那么好,仅比方案(2)高了一点点,甚至不如上述两种结果。
def get_PCA_result(dataCounter): """ ICLR2017论文算法 根据词频特征加权词向量,并使用PCA方法抽取第一主成分,从句向量中减去第一主成分进行余弦相似度计算 :return: 输出 测试机的id 训练集的预测结果, 对测试集的预测结果, 训练集的标签 """ model_loaded = Word2Vec.load(‘w2v.mod‘) y_train = [] # 使用训练数据训练模型 all_train = [] with open(path_train_lab) as file: for line in file: item = line.split(‘\t‘) matr1 = get_weighted_sent(dataCounter, prep_sentence(item[1]), model_loaded) matr2 = get_weighted_sent(dataCounter, prep_sentence(item[2]), model_loaded) data1 = matutils.unitvec(np.array(matr1).mean(axis=0)) data2 = matutils.unitvec(np.array(matr2).mean(axis=0)) all_train.append(data1) all_train.append(data2) y_train.append(float(item[3])) idx = [] all_test = [] with open(path_test_lab) as file: for line in file: item = line.split(‘\t‘) matr1 = get_weighted_sent(dataCounter, prep_sentence(item[1]), model_loaded) matr2 = get_weighted_sent(dataCounter, prep_sentence(item[2]), model_loaded) data1 = matutils.unitvec(np.array(matr1).mean(axis=0)) data2 = matutils.unitvec(np.array(matr2).mean(axis=0)) all_test.append(data1) all_test.append(data2) idx.append(item[0]) all_train = PCA_prep(all_train) all_test = PCA_prep(all_test) x_train = [] # 计算相似度 for i in range(len(all_train)): if i % 2 == 0: sim = cosine_similarity([all_train[i]], [all_train[i + 1]]) x_train.append(sim[0][0] * 5) x_test = [] for i in range(len(all_test)): if i % 2 == 0: sim = cosine_similarity([all_test[i]], [all_test[i + 1]]) x_test.append(sim[0][0] * 5) r, p = pearsonr(x_train, y_train) # 直接结果输出 print(‘Result PCA :‘, r) return idx, x_train, x_test, y_train
def get_freq(sentences): """ 获得语料库词频统计字典 :param sentences: :return: """ dataCounter = [] for sent in sentences: dataCounter += sent word_len = len(dataCounter) dataCounter = collections.Counter(dataCounter) for key in dataCounter: dataCounter[key] = dataCounter[key] / word_len # print(dataCounter) # print(1e-3) return dataCounter def get_weighted_sent(dataCounter, word_list, model_loaded): """ 基于词权重加权处理句向量 :param dataCounter: 词频率字典 :param word_list: 句子词列表 :param model_loaded: 词向量模型 :return: """ a = 1e-3 / 4 v_word_list = [] for word in word_list: count = dataCounter[word] # print(model_loaded.wv[word]) # print(a / (a + count) * model_loaded.wv[word]) v_word_list.append(a / (a + count) * model_loaded.wv[word]) return v_word_list
def stacking_result(w2v_x_train, LR_x_train,PCA_x_train, w2v_x_test, LR_x_test,PCA_x_test, label): """ stacking 方法对结果的集成 :param w2v_x_train: :param LR_x_train: :param w2v_x_test: :param LR_x_test: :param label: :return: """ x_train = [[w2v_score, LR_score, PCA_score] for w2v_score, LR_score, PCA_score in zip(w2v_x_train, LR_x_train, PCA_x_train)] x_test = [[w2v_score, LR_score, PCA_score] for w2v_score, LR_score, PCA_score in zip(w2v_x_test, LR_x_test, PCA_x_test)] model = LinearRegression() model.fit(x_train, label) predicted_train = model.predict(x_train) predicted_test = model.predict(x_test) r, p = pearsonr(predicted_train, label) # 直接结果输出 print(‘Result stacking:raw‘, r) return predicted_test
结果:
Result w2v: 0.770842157582 Result LR: 0.761403048811 Result PCA : 0.728098131446 Result stacking: 0.820756499196 end...