YARN框架&MapReduce框架
MapReduce实例:一个wordcount程序
统计一个相当大的数据文件中,每个单词出现的个数。
分析map和reduce的工作
map:
- 切分单词
- 遍历单词数据输出
reduce:
对从map中得到的数据的valuelist遍历累加,得到一个单词的总次数
代码
WordCountMapper(继承Mapper)
重写Mapper类的map方法。
mapreduce框架每读一行数据就调用一次该方法,map的具体业务逻辑就写在这个方法体中。
- map和reduce的数据输入输出都是以key-value对的形式封装的
- 4个泛型中,前两个(KEYIN, VALUEIN)指定mapper输入数据的类型, 后两个(KEYOUT, VALUEOUT)指定输出数据的类型
- 默认情况下,框架传递给mapper的输入数据中,key是要处理的文本中一行的起始偏移量,value是这行的内容
- 由于输入输出在结点中通过网络传递,数据需要序列化,但JDK自带的序列化机制会有附加信息冗余,对于大量数据传输不合适,因此
- 业务中要处理的数据已经作为参数key-value被传递进来了,处理后的输出是调用context.write()写入到context
package cn.thousfeet.hadoop.mapreduce.wordcount;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] words = StringUtils.split(line," "); //切分单词
for(String word : words) //遍历 输出为key-value( <word,1> )
{
context.write(new Text(word), new LongWritable(1));
}
}
}
WordCountReducer(继承Reducer)
重写Reducer类的reduce方法。
框架在map处理完成后,将所有的key-value对缓存起来进行分组,然后传递到一个组 <key,values{}>(对于wordcount程序,拿到的就是类似<hello,{1,1,1,1...}>),然后调用一次reduce方法。
package cn.thousfeet.hadoop.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> valueList,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long count = 0;
for(LongWritable value : valueList) //遍历value list累加求和
{
count += value.get();
}
context.write(key, new LongWritable(count)); //输出这一个单词的统计结果
}
}
WordCountRunner
用于描述job。
比如,该作业使用哪个类作为逻辑处理中的map,哪个作为reduce。还可以指定该作业要处理的数据所在的路径,和输出的结果放到哪个路径。
package cn.thousfeet.hadoop.mapreduce.wordcount;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
public class WordCountRunner {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//设置整个job所用的那些类在哪个jar包
job.setJarByClass(WordCountRunner.class);
//指定job使用的mapper和reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//指定reduce和mapper的输出数据key-value类型
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指定mapper的输出数据key-value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//指定原始输入数据的存放路径
FileInputFormat.setInputPaths(job, new Path("/wordcount/srcdata/"));
//指定处理结果数据的存放路径
FileOutputFormat.setOutputPath(job, new Path("/wordcount/output/"));
//将job提交给集群运行 参数为true时会打印运行进度
job.waitForCompletion(true);
}
}
上传到集群中运行
export成一个jar包,上传到虚拟机上。
分发到集群运行:hadoop jar wordcount.jar cn.thousfeet.hadoop.mapreduce.wordcount.WordCountRunner
查看输出结果:
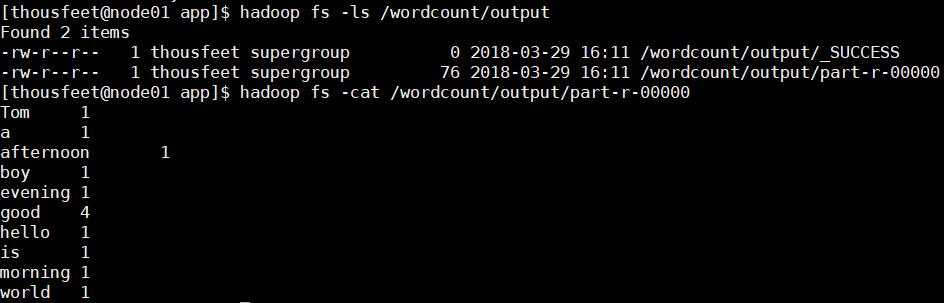
(可以看到按key的字典序升序排序)
如需方便在本地debug,可以直接run main方法(直接在本机的JVM运行),但要把输入输出路径改为hdfs全路径(或用在windows本地目录下的数据也行,MapReduce程序的运行和数据来源在哪无关),并且在eclipse的设置 Run Configurations->arguments->vm arguments ,添加-DHADOOP_USER_NAME=对应用户
yarn框架的运行机制
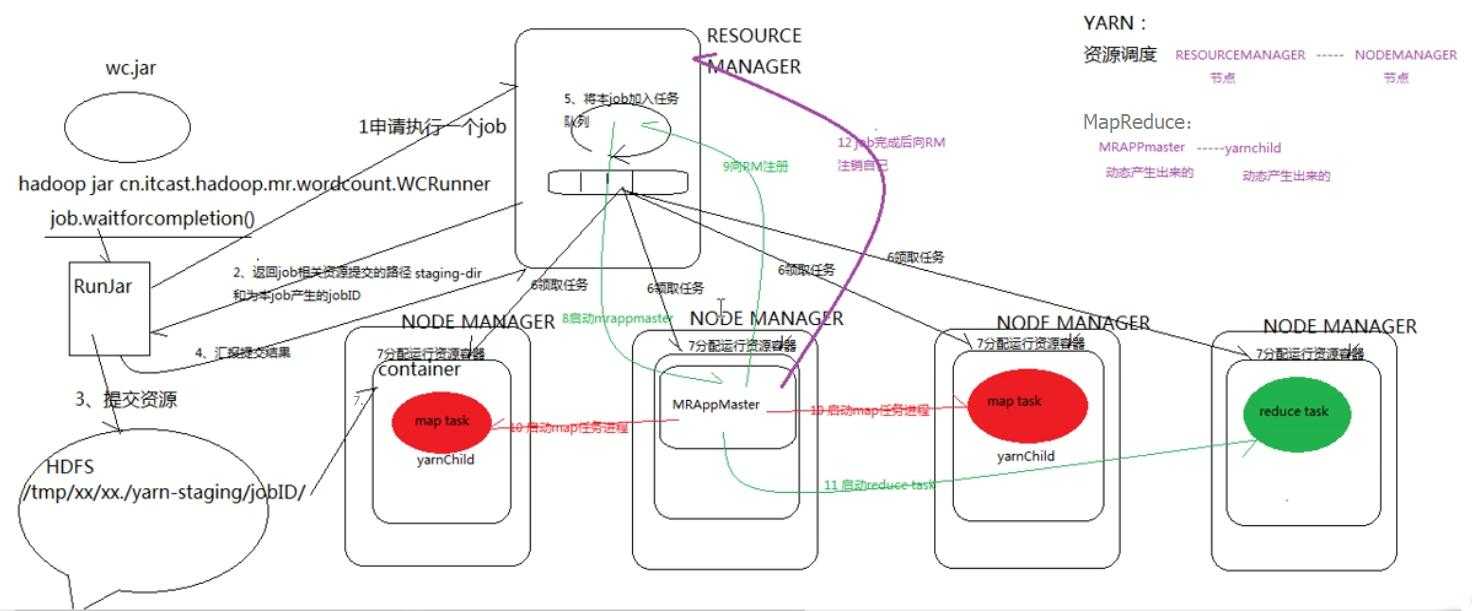
坑点
org.apache.hadoop.security.AccessControlException
运行程序后查看output文件夹能看到运行成功了,但是cat查看part-r-00000的时候报错
error creating legacy BlockReaderLocal. Disabling legacy local reads.
org.apache.hadoop.security.AccessControlException: Can‘t continue with getBlockLocalPathInfo() authorization. The user thousfeet is not configured in dfs.block.local-path-access.user
解决方法是hdfs-site.xml中的配置项dfs.client.read.shortcircuit=false
woc,这个参数其实原本默认就是false...突然想起这不是上次配置出错的时候病急乱投医加上的吗,果然乱跟教程害死人orzz