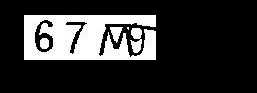今天学了下python的OCR识别,其中遇到好多坑,下面就一一阐述是如何破解的,本人用的是Windows 64位,IDE是VS2017。
- pip版本过低。
首先安装pytesseract这个库,pip install tessract。由于自己输错了,tessract前少了py两个字母,安装没有成功,抛出一个pip版本过低的问题,我就将pip升级到最新版9.0.3,以前是9.0.1。
输入python -m pip install --upgrade pip后提示没有访问权限,这里我就用管理员模式进到python目录下更新,这样就成功了。
- 找不到指定文件
在安装完pytessract后,还要去官网下载一个Tessract.exe文件安装配合使用。
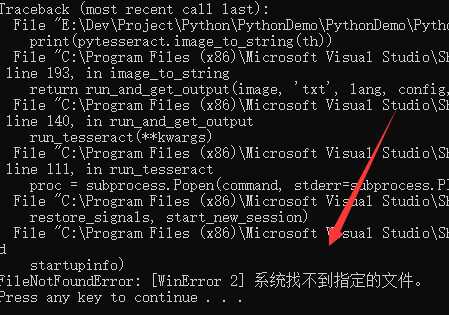
出现这个错误,想了一会儿没找到原因,搜了一下有说把要识别的图片放到pytessract的安装库下,试了一下没成功,而且个人认为这不是问题所在,因为把Image.open()的路径已经指定了也不行。
另一个方法是:
pytesseract.pytesseract.tesseract_cmd = r‘C:\Program Files (x86)\Microsoft Visual Studio\Shared\Python36_64\Tesseract-OCR\tesseract‘
试了一下,成功了。仔细一想瞬间就明白了:官方给的是pytessract和Tessract.exe配合使用(Windows系统下),那么IDE怎么知道你这个CMD在哪个文件下,所以在使用时要手动声明你的pytessract需要哪个CMD来执行识别的工作,文件路径就是你Tessract的安装路径里tessract.exe的路径。
最后说一点,Tessract这个识别率不高,4个字符识别出2个,还错一个。