第十一章 变量名的力量(续)
11.5 标准前缀
标准前缀由UDT(用户自定义类型)缩写与语义前缀构成。
> UDT缩写
用很短的、标准化的缩写表示对象和变量的类型,通常不会表示编程语言提供的预制数据类型。如,scr屏幕区域,wn表示窗体。
对应的变量名的例子:scrUserWorkspace,wnMain。
> 语义前缀
用于描述变量的用途、作用域等。如first, min, max, g (global)。可以与UDT缩写共同使用。
如:firstPaActive,first为语义前缀,Pa (page)为UDT缩写。
标准前缀的优点:可以更精确地描述变量的性质、用途,并减少需要记忆的变量名。由于标准前缀常为缩写,可以使变量名更为紧凑。同时,标准前缀更具备可读性,便于检查代码中可能的类型错误、引用错误。
11.6 具备可读性的短命字
在必须采用短名字的情况下(如汇编、Basic、Fortran),也需要保证名字有可读性。
在一般的高级语言(如java, cpp, python)中,并不存在这种限制,但是仍然可以学习一些技术,将冗余的长名字变得简洁。
> 缩写方法:
- 使用标准的、常见的缩写。
- 去掉非前置元音。如:computer -> cmptr, screen -> scrn, apple -> appl, integer -> intgr
- 去掉虚词,如and, or, the
- 使用每个单词的第一个或前几个字母。
- 统一在所有单词的前一个、两个或三个处截断。如果截取单词太短,容易造成混淆。
- 保留每个单词的第一个和最后一个字母。
- 使用名字中的每一个重要单词,但最多不超过三个。
- 去除无用的后缀,如ing, ed, s
- 保留音节中最突出的发音。
- 不要改变变量含义。
> 语音缩写:如将skating缩写为sk8ing,before -> b4。这样容易造成混淆。
但个人以为,可以采用一些常用的语音缩写,如将to缩写为2,包括p2p (point to point), b2b等
> 注意:
- 不要仅为了删除一个字符而改变常用的缩写、名字,如将June写作Jun
- 缩写要保持一致。
- 创建能够拼读的名字。这意味着除非是非常常用的缩写,如destination -> dst, pointer -> ptr,不能将所有非前置元音去掉。
- 避免容易看错、读错、写错的缩写。
- 如果不同单词缩写时发生冲突,可以尝试在词典中寻找不冲突的同义词。
- 用对照表、文档解释所有的缩写。这样可以增加阅读代码的方便性,并减少同一个单词有多个不同缩写的可能性。
11.7 应该避免的名字
这里单独用一个小章节强调了不应该使用的变量名:
- 令人误解的变量名,如Fig and Almond Season缩写为FALSE
- 避免同一作用域中使用数个意义相仿的变量名,如recordNum和numRecord。如果两个变量功能迥异却名字相仿,应该考虑更换缩写策略或者采用形式不同的近义词。
- 避免使用读音相近的名字。
- 尽量不要在变量中使用数字,因为数字可读性很差,容易造成含义的混淆。假如要采用一连串变量,可以使用数组。假如要使用数个功能、含义不同的变量,就应该更明确地定义该变量。
- 不要在名字中拼错单词,也尽量不要使用容易拼错的单词。
- 不要仅用大小写区分变量名。
- 不要混用多种语言,甚至是英式英语与美式英语。(但是作为一个英语不好的中国人,我有时候难以区分英式英语和美式英语)
- 避免使用标准类型、变量和子程序的名字。在java cpp中保留名是不可以使用的,但如cpp中string array cout这些名字,只要没有引入标准库中的名字,是可以使用的。而在python中,甚至可以使用str之类的类型名给变量命名。这样很容易引起困惑,应该避免。
- 不要使用和变量含义完全无关的名字。
- 避免使用容易混淆的字符,如小写L、数字1、大写i,数字0和大写o等。
第十二章 基本数据类型
这一章讲述了使用基本数据类型的要点。
12.1 数值概论
> 不要将数值硬编码进入代码,而应该用具名常量。以cpp为例,应使用宏定义或(更好)const。优点在于提高可读性与可修改性。尤其,在条件判断结构中,硬编码数值会非常晦涩。
不过在需要的情况下,可以将0、1硬编码,如for(int i = 0; i < SIZE; i++){ 代码 },total = total + 1;,在这些情况下,0和1可读性很好,而且这些功能中涵盖的0、1两个数值不容易被修改。
> 使用除法的时候,始终考虑是否会除零。
> 采用显式类型转换。避免将不同的类型进行比较、运算。
> 注意编译器给的warning。
12.2 整型
- 注意整数除法结果同样为整数。如果要让结果为浮点数,应该显式类型转换。
- 检查溢出,特别中间结果溢出。
12.3 浮点数
浮点数的一系列问题来源于浮点数只能表示有限个有效数字,精确性有限。要点:
- 避免数量级相差巨大的运算,如1e12 + 1e-4、5000000000000.3 - 5000000000000.1。一个方法是从最小的数值开始运算,但这不能根本解决问题。
- 不要用等量判断,采用一个小误差判断两个浮点数是否相等。
- 舍入误差,如 1 / 3 * 3因为舍入误差被表示为0.99999999。一般而言这个问题并不严重,但假如需要高精度运算,可以:使用高精度浮点数,使用BCD码,使用整型变量。
- 检查语言和函数库对特定数据类型的支持,比如python支持高精度运算。
12.4 字符和字符串
- 类似数值,不要使用硬编码。
- 避免越界。
- 了解语言对于Unicode编码的支持。
- 尽早决定使用多语言还是单一语言。如果使用单一英语,采用iso 8859,它对ascii进行了拓展。如果使用多语言,采用unicode。
- 尽量采取一致的字符串处理策略。
> C中的字符串:
注意字符串与字符数组之间的差异。(虽然实际上字符数组并不常用。)具体表现在:警惕赋值语句,用命名规则区分两者。
- 将c风格的字符串长度声明为CONSTANT + 1,以避免可能的越界。虽然实际上,我经常将长度声明为CONSTANT + 2。
- 一定要在字符串末尾加0。假如是定义的变量,要将其初始化。假如是malloc的变量,至少要将第一位标为0。在增长、截断已有字符串时,也要记得末尾补0。
- 表示字符串时,除非内存限制急迫,否则使用数组而非指针。这样可以避免一些玄学错误,编译器也更能发现可能的错误。
- 采用strncpy, strncmp等取代strcpy, strcmp。
幸运的是,只要使用cpp,这一切问题都可以通过stl string避免。
12.5 布尔变量
> 布尔表达式往往缺乏可读性。可以用布尔变量来增强可读性,简化复杂的、多层的判断。
> 一些语言,如java cpp有内置的布尔类型,但另一些语言,如c,没有。可以自定义布尔类型。
12.6 枚举类型
> 在表示同一个属性的不同“选项”的情境下,枚举类型可以用于避免硬编码的数值、常量,从而增加代码可读性、可修改性。类似于符号常量。
而相比起符号常量,枚举类型作用域更小,而且具有类型检查,因此更加安全。
同时,枚举类型抽象性更强,更符合封装原则。
> 一些可能的用途:
- 用来拓展布尔常量。如某个函数的返回值为运行状态,而状态可能不仅有true和false两种,而是有success, warning, error等多种状态。
- 在switch或if-else中检查非法数值。
- 关于枚举类型的遍历:
- 定义枚举类型的边界,方便枚举循环。如在VB中作如下定义:
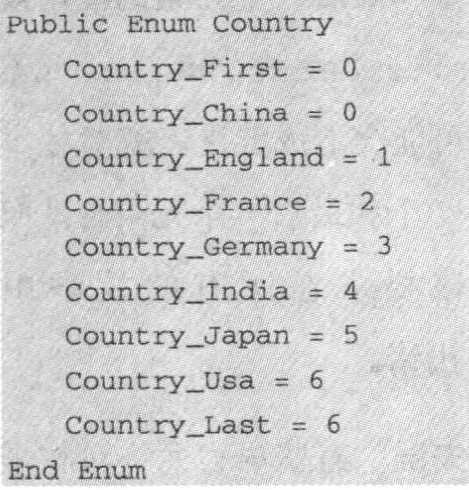
- 便可以将Country_First和Country_Last作为循环边界。如果采用这种技巧,一定要明确定义。
- 警惕明确赋值带来的错误,如某几个特定的值没有对应的枚举项,遍历时会出错。
- 问题在于有的语言不允许为多个枚举项定义同一数值,且有的语言为枚举类型提供了遍历功能。
- 需要的话,把枚举类型中的0值设定为非法值,因为0被转化为布尔值为false,更有利于捕捉错误。
12.7 具名常量
硬编码的缺点和具名常量的优点在上面已经一而再再而三地重复过,在此不再赘述。
注意:不要在一些地方使用具名常量,在另一些地方使用硬编码。这甚至比不用具名常量还要糟糕,因为会让人忘记修改硬编码的数值。
12.8 数组
> 数组很容易发生越界的错误。一些要点:
- 使用下标时确认没有越界。
- 尽量使用封装良好的容器类,减少数组的随机存取。
- 检查数组的边界。
- 如果数组为多维数组,注意不要把下标顺序弄反。
- 如果使用嵌套循环,注意不要把不同循环变量弄反。采用更好的命名规则可以减少这个问题。
- 结合length, size之类的函数或宏防止数组越界。
12.9 创建自己的类型
利用typedef或自定义class增加代码的可读性、可修改性和信息隐藏性。一些原则:
- 给所取类型取功能导向的名字,如Currency, Age。避免可能的预定义类型名,如BigInteger。
- 如果某类变量类型还有可能改变,应该避免使用预定义类型名。
- 不要重定义已经typedef后的类型名字。
- 可以要为标准类型定义替代类型,如INT32,以便于增加可移植性。
- 除非功能单一,考虑使用class而非typedef。
第十三章 不常见的数据类型
13.1 结构体
在c中提供了struct,Microsoft VB中提供了Structure。在java cpp中,有时类的行为类似结构体。一些用途:
- 明确数据关系,尤其是那些并不复杂的数据关系。复杂的关系和行为常常需要类。
- 简化对一组数据的操作。
- 简化对一组数据修改、增加、减少数据项的工作,增加可维护性。
- 简化参数列表。
总得来说,结构体用于方便对一组并列的、功能内聚的,而且具体数据项有可能被修改的数据项的操作与维护。
13.2 指针
指针指向内存中的一个区域,该区域中数据应该符合指针的基类型。
指针操作非常容易出错,而且很容易很危险。
> 一些通用技巧:
- 将指针封装在子程序或类中,保证在尽可能少的位置直接对指针进行操作。
- 在定义时就为指针赋初值,或至少要把指针置为空值,以免被引用错误的内存。
- 在与指针分配相同的层次、作用域中释放指针。
- 使用指针之前先检查。
- 使用tag field,即:
- 在结构体中加入一个仅用来检测错误的字段,其值应该始终为某个定值。
- 假如使用结构体,尤其释放结构体指针时检查到该字段被修改,则说明可能发生错误。
- 在释放指针时应该破坏这个字段,从而检查被释放的内存是否还在被使用。
- 另一种方法是使用冗余字段,将特定字段重复两次,如果发现两字段值不同便说明发生了错误。这个方法问题在于可能自己会操作错误,更改一个值的时候忘记更改另一个值。
- 不要用同一指针用于多种用途!!!这一原则对于指针尤为重要,因为指针指向的内存不会被自动清理,因此很有可能造成申请的空间没有被释放或者double free。
- 简化指针表达式。
- 按照正确的顺序释放指针,如释放结构体指针前先释放结构体中的指针指向的内存。
- 分配一块后备内存区域,以保证如果内存耗尽,可以保存工作、清理现场、体面退出。
- 释放指针前,先检查指针合法性(不过很少有语言支持这一点)。释放前将被释放的空间填满垃圾数据,释放后将指针变量置空。
- 跟踪指针的分配情况,维护一份指针分配表。
- 在一份代码中尽量采取统一策略,如自定义SAFE_NEW, SAFE_DELETE函数。
> c++中的指针:
- 指针与引用:指针可以为空,引用必须指向一个对象;指针指向的内存可以改变,而引用所引用的对象赋值后不能改变。
- 可以将指针用于按引用传参,而将const引用用于按值传参。
- 不过我并不理解为什么要用指针按引用传参。用指针确实比用引用更少引起误解,但个人觉得引用大大方便了传参和编码的方便性,大部分情况下都没必要舍弃。
- const引用局限性在于const有传播性,使用库函数可能会有障碍。
- 使用auto_ptr
- 使用智能指针
> c中的指针:
- 使用显式指针类型,方便编译器纠错。
- 避免指针强制类型转换。
- 如果用指针实现按引用传参,记得加星号。不过不加星号一般会出现error或warning的。
- 使用sizeof确认内存大小。
13.3 全局变量
全局变量增大了耦合度,可能带来风险。可能的问题可以归结为下列几个:
- 无意修改全局变量的数据。
- 重名问题。
- 全局变量被作为参数带来的别名问题。
- 不利于多线程。
- 阻碍代码复用。
- 如果一个文件中的全局变量的初始化引用了另一个文件中的全局变量,初始化会变得复杂。
- 破坏了模块化。
而在另一些场合,全局变量是有用的:
- 保存全局数值,如程序运行模式等。
- 在没有具名常量的语言中,模拟剧名常量。
- 在没有枚举类型的语言中,模拟枚举类型。
- 假如有的数据真的会被几乎所有类、方法引用,则可以设定为全局变量,而不用在不同的类、方法之间传递来传递去。但这种情况很罕见。
- 消除流浪数据,即将一个数据传递给一个类或方法,仅仅是为了该类或方法将这个数据传给另一个类或方法。
- 个人补充一点,c cpp中全局变量在静态区,储存空间较大。如果需要的储存空间大于堆、栈的容量,可以考虑使用全局变量。
仅在万不得已的情况下才能使用全局变量。如:
> 应该先将数据设为局部,尽在需要时修改为全局。
> 可以使用访问器子程序。对常见操作进行封装,并只使用访问器子程序引用数据,如将栈的出入栈操作进行封装。
好处:
- 数据隐藏的普遍好处
- 获取了对数据的集中控制,方便修改维护。
- 避免了可能的数据误操作。
- 抽象度更高。
使用访问器子程序的技巧:
- 一定要仅用访问器子程序访问数据。
- 不要将全局数据写到一块,想想能不能用类封装。
- 用锁定标志防止并发访问。
- 提供抽象的功能,如increment,而不是addOne。
- 使对同一数据的访问发生在同一抽象层上。
为了降低全局变量的风险,可以采纳的方案:
- 用命名规则突出全局变量。
- 为全部的全局变量制作清单。
- 不要用全局变量存放计算中间结果。
- 不要用四处传递一个大类型来掩盖用了全局数据的事实。如果真的非用全局数据不可,就显式地用,至少让人更容易警觉。