目录
1.1基本功能
1.2设计实现
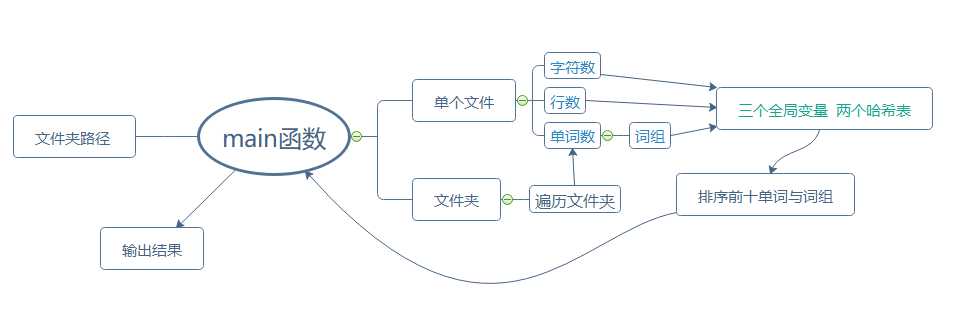
1.3代码结构
1.4测试运行
1.5性能分析
1.6项目总结
1.7 PSP展示
1.1 基本功能
1. 统计文件的字符数(只需要统计Ascii码,汉字不用考虑,换行符不用考虑,‘\0‘不用考虑)(ascii码大小在[32,126]之间)
2. 统计文件的单词总数
3. 统计文件的总行数(任何字符构成的行,都需要统计)(不要只看换行符的数量,要小心最后一行没有换行符的情形)(空行算一行)
4. 统计文件中各单词的出现次数,输出频率最高的10个。
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
7. 在Linux系统下,进行性能分析,过程写到blog中(附加题)
关于字符、行数与单词的统计规则详情请见:http://www.cnblogs.com/denghp83/p/8627840.html
1.2 设计实现
1.2.1 解题思路
1. 用命令行参数输入文件路径,判断其是单个文件还是文件夹。
若为单个文件则直接打开,统计字符、单词与行数;若为文件夹,则递归遍历该文件夹下的所有文件进行统计。
之前用文件操作用得较少,所以对遍历文件夹的操作不熟悉,在网上找了点资料。
(学习笔记:
1)存储文件各种信息的结构体中:unsigned attrib表示文件的属性,_A_SUBDIR表示文件夹属性。
2)_findfirst函数
long _findfirst( char*filespec,struct _finddata_t *fileinfo );
返回值:如果查找成功的话,将返回一个long型的唯一的查找用的句柄(就是一个唯一编号)。这个句柄将在_findnext函数中被使用。若失败,则返回-1。
fileinfo :这里就是用来存放文件信息的结构体的指针。这个结构体必须在调用此函数前声明,不过不用初始化,只要分配了内存空间就可以了。函数成功后,函数会把找到的文件的信息放入这个结构体中。
3)_findnext函数
int _findnext( long handle, struct_finddata_t *fileinfo );
返回值:若成功返回0,否则返回-1。
参数:handle:即由_findfirst函数返回回来的句柄。
fileinfo:文件信息结构体的指针。找到文件后,函数将该文件信息放入此结构体中。
https://blog.csdn.net/aoshilang2249/article/details/37819159)
2. 对于字符、行数与单词数统计,将字符数、行数与单词数作为全局变量,一开始最简单的想法是分三次读取文件,后来想想真的太费时间了。
最后的方案是每读一个文件,就把字符、行数与单词数统计好。
3. 对于单词和词组频率的统计:创建两个哈希表,使用ELFHASH哈希算法计算索引值,使用拉链法处理冲突。
对词组频率的统计一开始没有什么头绪,后来翻看了其他同学的博客,通过操作前后两个单词的结构体指针来实现词组在哈希表中的存储,才大概有了点头绪。
4. 输出频率前十的单词和词组:通过遍历哈希表实现。
1.2.2 实现细节
单词和词组的结构体:
typedef struct wordnode { int times; char word[MAX];//单词原型 char wordhash[MAX];//去掉最末尾数字且字母全为小写 struct wordnode *next; }wordnode, *wordlist; typedef struct phrasenode { int times; wordlist wordpre;//前一个单词 wordlist wordaft;//后一个单词 struct phrasenode *next; }phrasenode, *phraselist;
1. 字符数统计:ASCII码值在32-126之间的字符,则字符数加一。
2. 行数统计:扫描到‘\n‘,则行数加一。每个文件扫描结束,行数再加一。(自我感觉这个统计方法有点不太靠谱。)
3. 单词数统计:当扫描到分隔符后的第一个字母或数字时,开始将该字符存储到缓冲数组,直到遇到下一个分隔符。
再对缓冲数组中的字符串做分析,如果长度(不含末尾‘\0‘)大于等于4并且前四个字符都为字母,则单词数加一。
为了便于计算哈希算法的键值和处理冲突,将字符串做一些处理,去掉最末尾的数字并将剩下的均转化为小写。
根据键值与字符串的大小比较在哈希表中查找,若查找失败,则创建一个新结点;若查找成功,则次数加一。
4. 词组数统计:按上述方法记录一下每一个单词的结构体指针。
若不是该文件的第一个单词,将它与上一个单词合在一起生成一个哈希键值,用与统计词频相似的方法处理哈希表。
for (i = 0; ((ch >= ‘a‘&&ch <= ‘z‘) || (ch >= ‘A‘&&ch <= ‘Z‘) || (ch >= ‘0‘&&ch <= ‘9‘)) && ch != EOF; i++) { charactercount++; buffer[i] = ch; ch = fgetc(fp); } charactercount--; buffer[i] = ‘\0‘; if (i >= 4 && ((buffer[0] >= ‘a‘&&buffer[0] <= ‘z‘) || (buffer[0] >= ‘A‘&&buffer[0] <= ‘Z‘)) && ((buffer[1] >= ‘a‘&&buffer[1] <= ‘z‘) || (buffer[1] >= ‘A‘&&buffer[1] <= ‘Z‘)) && ((buffer[2] >= ‘a‘&&buffer[2] <= ‘z‘) || (buffer[2] >= ‘A‘&&buffer[2] <= ‘Z‘)) && ((buffer[3] >= ‘a‘&&buffer[3] <= ‘z‘) || (buffer[3] >= ‘A‘&&buffer[3] <= ‘Z‘))) { wordtotal++;//此时i即为单词原始长度 for (k = i - 1; ; k--) { if ((buffer[k] >= ‘a‘&&buffer[k] <= ‘z‘) || (buffer[k] >= ‘A‘&&buffer[k] <= ‘Z‘)) break;//k represents the last location of a character } //my_strlwr(regular, buffer, k + 1); current = wordFrequency(buffer, k + 1); if (wordtotal > 0) { //不是第一个单词 phraseFrequency(last, current); } last = current; }
1.3 代码结构
详细代码地址:https://github.com/EstherXr/learngit/blob/master/homework1.cpp
1.4 测试运行
1. 助教给的测试集
上面为我的结果,下面为助教给的测试结果。

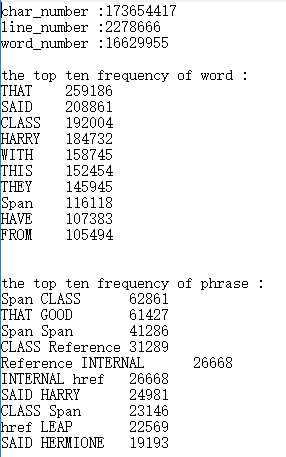
频率前十的单词和词组及频率与助教的结果相同,但是字符数、行数与单词数都有偏差。对于单词数,我觉得是各人的定义不同,比如ab123abcd中的abcd到底算不算单词。
2. 空文件:

3. 遍历文件夹测试一:

4. 遍历文件夹测试二:
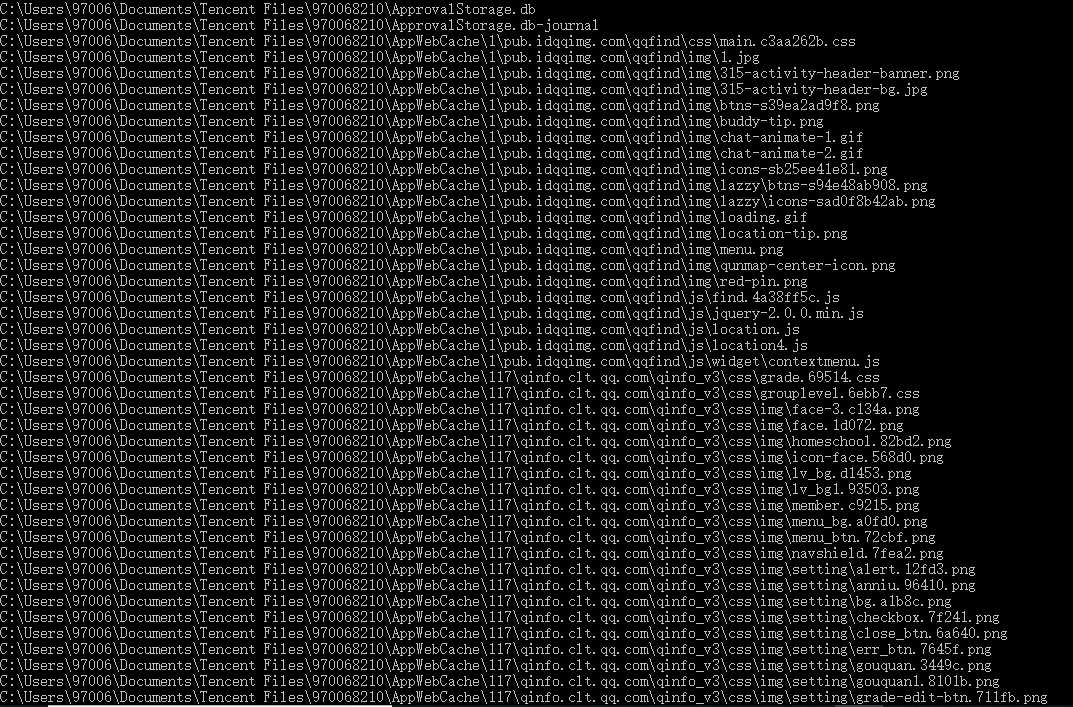
5. 单文件输出所有单词:

1.5 性能分析
CPU总使用情况
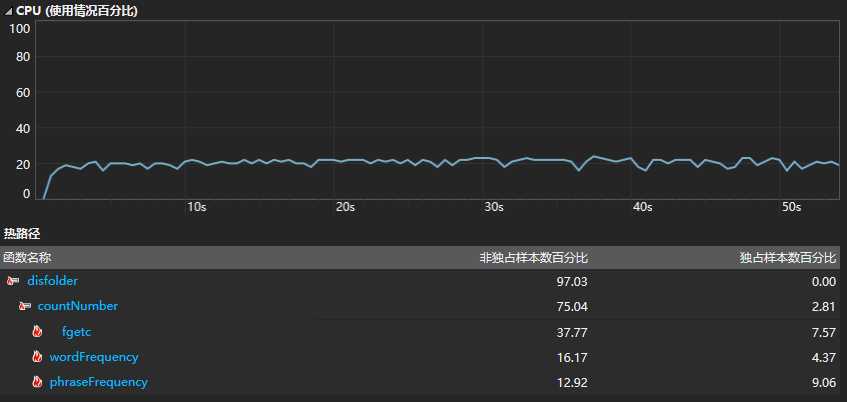
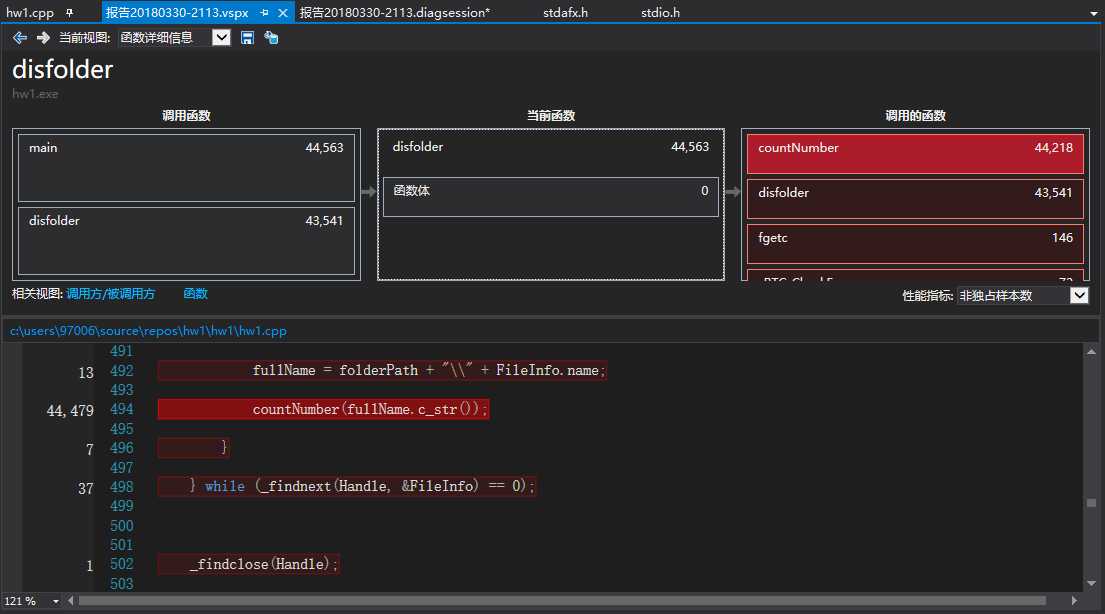
遍历文件夹函数:
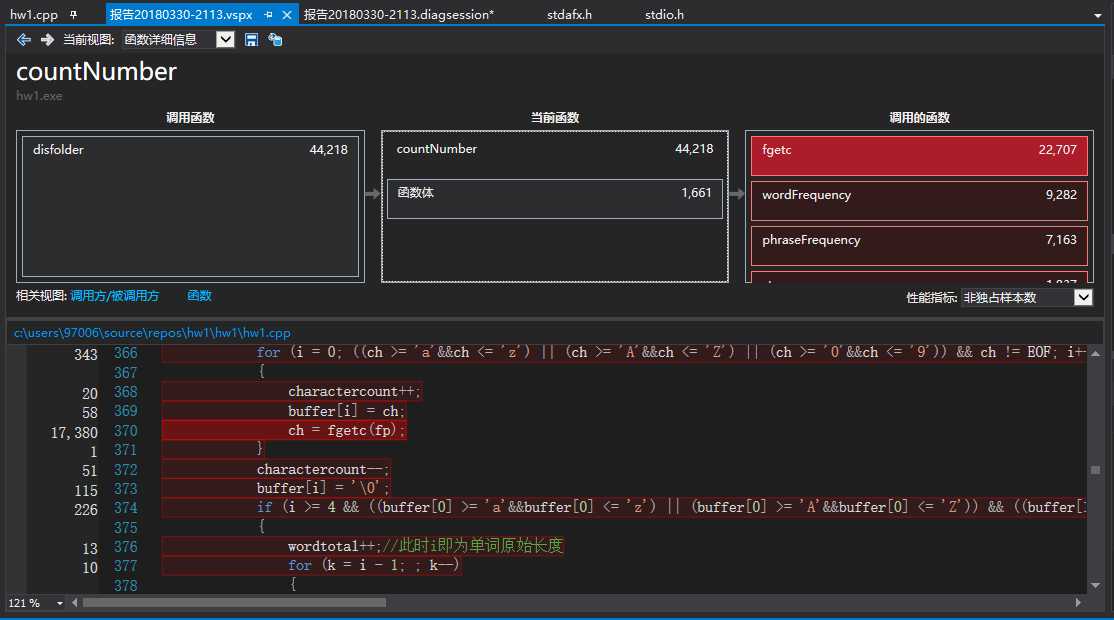
统计字符数、行数与单词数:
分析:
从函数的CPU使用情况来看,大部分时间都花费在遍历文件夹与统计函数上。
1.6 项目总结
到真正写代码和做东西的时候,就会发现自己会的东西真的太少了。(所以这次基本是用纯C写的)也因为之前写代码写得太少了,所以对自己能力的估计也很不准确,导致规划的效率很低。
在交代码的那天晚上才开始做移植,但是在Linux系统上测试一直有问题,所以最后只好交了一份没有移植的代码。之后要把这个问题搞明白,也要开始学习如何使用虚拟机。
以后做项目要多些文档,可以帮助自己梳理思路,更有条理。这也是这次作业不足的地方。
最后,一定要和身边的人多交流。
1.7 PSP展示
| 预估耗时/min | 实际耗时/min | ||
| Planning | 计划 | 30 | 45 |
| -Estimate | -估计这个任务需要多少时间 | 30 | 45 |
| Development | 开发 | 1220 | 1600 |
| -Analysis | -需求分析 | 120 | 60 |
| -Design Spec | -设计文档 | 90 | 60 |
| -Design Review | -设计复审 | 30 | 20 |
| -Coding Standard | -代码规范 | 20 | 20 |
| -Design | -具体设计 | 120 | 240 |
| -Coding | -具体编码 | 600 | 900 |
| -Code Review | -代码复审 | 60 | 60 |
| -Test | -测试 | 180 | 240 |
| Reporting | 报告 | 180 | 265 |
| -Test Report | -测试报告 | 90 | 180 |
| -Size Measurement | -计算工作量 | 60 | 40 |
| -Postmortem | -总结反思 | 30 | 45 |
| 1430 | 1910 |