1、Spark Core: 类似MapReduce 核心:RDD 2、Spark SQL: 类似Hive,支持SQL 3、Spark Streaming:类似Storm
=================== Spark Core =======================
一、什么是Spark?
1、什么是Spark?生态体系结构
Apache Spark? is a fast and general engine for large-scale data processing.
生态圈:
1、Spark Core
2、Spark SQL
3、Spark Streaming
4、Spark MLLib:机器学习
5、Spark GraphX:图计算
2、为什么要学习Spark?
复习:MapReduce的Shuffle过程
Spark的最大特点:基于内存
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
3、Spark的特点
(1)快:基于内存
同时也是缺点:没有对内存进行管理,把所有的内存管理都交给应用程序,容易出现OOM(outof memory 内存溢出)
如何分析Java内存溢出?? 工具:Java Heap Dump
https://www.cnblogs.com/JackDesperado/p/4798499.html
(2)易用:Java、Scala
(3)通用:不同的组件
Hive推荐使用Spark作为执行引擎 ------> 配置Hive On Spark非常麻烦,不成熟
提供文档:Hive On Spark
(4)兼容性:Hadoop的生态圈
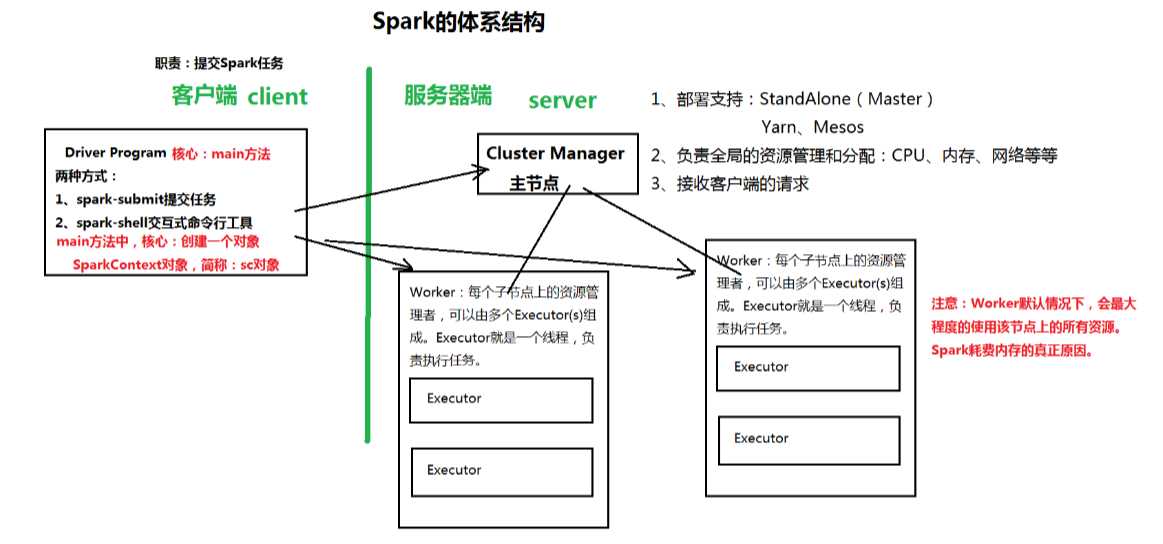
二、Spark的体系结构和安装配置
1、体系结构:Client-Server(主从模式) ----> 单点故障:HA(ZooKeeper)
http://spark.apache.org/docs/latest/cluster-overview.html
准备工作:安装Linux、JDK、主机名、免密码登录
2、安装和部署:standalone
tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz -C ~/training/
注意:hadoop和spark命令脚本有冲突,只能设置一个
核心配置文件:spark-env.sh
(*)伪分布模式: bigdata11机器
spark-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144 export SPARK_MASTER_HOST=bigdata11 export SPARK_MASTER_PORT=7077
slave文件:
bigdata11
启动:sbin/start-all.sh
Web Console: http://ip:8080 (内置了一个tomcat)
(*)全分布模式: bigdata12 bigdata13 bigdata14
(1)在主节点上进行安装
spark-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144 export SPARK_MASTER_HOST=bigdata12 export SPARK_MASTER_PORT=7077
slave文件:
bigdata13
bigdata14
(2) 复制到从节点上
scp -r spark-2.1.0-bin-hadoop2.7/ root@bigdata13:/root/training
scp -r spark-2.1.0-bin-hadoop2.7/ root@bigdata14:/root/training
(3) 在主节点上启动
启动:sbin/start-all.sh
Web Console: http://ip:8080 (内置了一个tomcat)
3、Spark的HA实现
(1)基于文件系统的单点故障恢复:只有一个主节点、只能用于开发测试
(*)特点:把Spark的运行信息写入到一个本地的恢复目录
如果Master死掉了,恢复master的时候从恢复目录上读取之前的信息
需要人为重启
(*)Spark的运行信息
Spark Application和Worker的注册信息
(*)配置:
(a)创建目录:mkdir /root/training/spark-2.1.0-bin-hadoop2.7/recovery
(b)参数:
spark.deploy.recoveryMode:取值:默认NONE--> 没有开启HA
FILESYSTEM ---> 基于文件系统的单点故障恢复
ZOOKEEPER ---> 基于ZooKeeper实现Standby的Master
spark.deploy.recoveryDirectory: 恢复目录
(c)修改spark-env.sh
增加:export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/root/training/spark-2.1.0-bin-hadoop2.7/recovery"
(*)测试:启动spark-shell
bin/spark-shell --master spark://bigdata12:7077
sbin/stop-master.sh
日志
scala> 18/02/09 00:40:42 WARN StandaloneAppClient$ClientEndpoint: Connection to bigdata12:7077 failed; waiting for master to reconnect...
18/02/09 00:40:42 WARN StandaloneSchedulerBackend: Disconnected from Spark cluster! Waiting for reconnection...
18/02/09 00:40:42 WARN StandaloneAppClient$ClientEndpoint: Connection to bigdata12:7077 failed; waiting for master to reconnect...
重新启动master
(2)基于ZooKeeper实现Standby的Master
(*)复习:相当于是一个“数据库”
角色:leader、follower
功能:选举、数据同步、分布式锁(秒杀功能)
(*)原理:类似Yarn
(*)参数
spark.deploy.recoveryMode 设置为ZOOKEEPER开启单点恢复功能,默认值:NONE
spark.deploy.zookeeper.url ZooKeeper集群的地址
spark.deploy.zookeeper.dir Spark信息在ZK中的保存目录,默认:/spark
(*)修改spark-env.sh
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata12:2181,bigdata13:2181,bigdata14:2181 -Dspark.deploy.zookeeper.dir=/spark"
(*)测试
bigdata12: sbin/start-all.sh
bigdata13(14):手动启动一个master
sbin/start-master.sh
worker信息注册到了13上。