1. 项目需求
我们取有一份学生五门课程的期末考试成绩数据,现在我们希望统计每个学生的总成绩和平均成绩。 样本数据如下所示,每行数据的数据格式为:学号、姓名、语文成绩、数学成绩、英语成绩、物理成绩、化学成绩。
19020090040 秦心芯 123 131 100 95 100
19020090006 李磊 99 92 100 90 100
19020090017 唐一建 90 99 100 89 95
19020090031 曾丽丽 100 99 97 79 96
19020090013 罗开俊 105 115 94 45 100
19020090039 周世海 114 116 93 31 97
19020090020 王正伟 109 98 88 47 99
19020090025 谢瑞彬 94 120 100 50 73
19020090007 于微 89 78 100 66 99
19020090012 刘小利 87 82 89 71 99
下面我们需要编写程序,实现自定义输入并求出每个学生的总成绩和平均成绩。
2. 项目实现
第一步:为了便于每个学生学习成绩的计算,这里我们需要自定义一个 ScoreWritable 类实现 WritableComparable 接口,将学生各门成绩封装起来。
/**
*
*/
package com.hadoop.InputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* @author Zimo
* 编写学习成绩读写自定义类ScoreWritable,实现WritableComparable接口中的方法
* 数据格式参考:19020090017 name 90 99 100 89 95
*
*/
public class ScoreWritable implements WritableComparable<Object>{
private float Chinese;
private float Math;
private float English;
private float Physics;
private float Chemistry;
//无参构造器
public ScoreWritable() {}
//重载构造函数
public ScoreWritable(float Chinese,float Math,float English,float Physics,float Chemistry) {
this.Chinese = Chinese;
this.Math = Math;
this.English = English;
this.Physics = Physics;
this.Chemistry = Chemistry;
}
// set/get方法
public float getChinese() {
return Chinese;
}
public void setChinese(float chinese) {
Chinese = chinese;
}
public float getMath() {
return Math;
}
public void setMath(float math) {
Math = math;
}
public float getEnglish() {
return English;
}
public void setEnglish(float english) {
English = english;
}
public float getPhysics() {
return Physics;
}
public void setPhysics(float physics) {
Physics = physics;
}
public float getChemistry() {
return Chemistry;
}
public void setChemistry(float chemistry) {
Chemistry = chemistry;
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
Chinese = in.readFloat();
Math = in.readFloat();
English = in.readFloat();
Physics = in.readFloat();
Chemistry = in.readFloat();
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeFloat(Chinese);
out.writeFloat(Math);
out.writeFloat(English);
out.writeFloat(Physics);
out.writeFloat(Chemistry);
}
@Override
public int compareTo(Object arg0) {
// TODO Auto-generated method stub
return 0;
}
}
第二步:自定义输入格式 ScoreInputFormat 类,首先继承 FileInputFormat,然后分别重写 isSplitable() 方法和 createRecordReader() 方法。 需要注意的是,重写createRecord Reader()方法,其实也就是重写其返回的对象ScoreRecordReader。ScoreRecordReader 类继承 RecordReader,实现数据的读取。
/**
*
*/
package com.hadoop.InputFormat;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.LineReader;
/**
* @author Zimo
* 自定义学生成绩读写类InputFormat,继承自FileInputFormat接口,并实现其中的方法
*
*/
public class ScoreInputFormat extends FileInputFormat<Text, ScoreWritable> {
@Override
public RecordReader<Text, ScoreWritable> createRecordReader(InputSplit arg0, TaskAttemptContext arg1)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
return new ScoreRecordreader();//RecordReader 中的两个参数分别填写我们期望返回的key/value类型,我们期望key为Text类型,
//value为ScoreWritable类型封装学生所有成绩
}
public static class ScoreRecordreader extends RecordReader<Text, ScoreWritable> {
public LineReader in;//行读取器
public Text key;//自定义key类型
public ScoreWritable value;//自定义value类型
public Text line;//每行数据类型
@Override
public void close() throws IOException {
// TODO Auto-generated method stub
if (in != null) {
in.close();
}
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return key;
}
@Override
public ScoreWritable getCurrentValue() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return 0;
}
@Override
public void initialize(InputSplit input, TaskAttemptContext context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
FileSplit split = (FileSplit)input;
Configuration job = context.getConfiguration();
Path file = split.getPath();
FileSystem fs = file.getFileSystem(job);
FSDataInputStream filein = fs.open(file);
in = new LineReader(filein, job);
line = new Text();
key = new Text();
value = new ScoreWritable();
}
//此方法读取每行数据,完成自定义的key和value
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
// TODO Auto-generated method stub
int linesize = in.readLine(line);
if (linesize == 0) {
return false;
}
String[] pieces = line.toString().split("\\s+");//解析每行数据,根据空格划分
if (pieces.length != 7) {
throw new IOException("Invalid record received");
}
//将学生的每门成绩转换为 float 类型
float a, b, c, d, e;
try{
a = Float.parseFloat(pieces[2].trim());
b = Float.parseFloat(pieces[3].trim());
c = Float.parseFloat(pieces[4].trim());
d = Float.parseFloat(pieces[5].trim());
e = Float.parseFloat(pieces[6].trim());
} catch(NumberFormatException exception) {
throw new IOException("Error parsing floating poing value in record");
}
key.set(pieces[0] + "\t" + pieces[1]);//完成自定义key数据
//封装自定义value数据
value.setChinese(a);
value.setMath(b);
value.setEnglish(c);
value.setPhysics(d);
value.setChemistry(e);
return true;
}
}
}
在上述类中,我们只需根据自己的需求,重点编写nextKeyValue()方法即可,其它的方法比较固定,仿造着编码就可以了。
第三步:编写 MapReduce 程序,统计学生总成绩和平均成绩。这里 MapReduce 程序仿造前面模板编写就可以了,很简单。
/**
*
*/
package com.hadoop.InputFormat;
import java.io.IOException;
import org.apache.commons.collections.map.StaticBucketMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author Zimo
* 学生成绩统计Hadoop程序
*
*/
public class ScoreCount extends Configured implements Tool {
public static class ScoreMapper extends Mapper<Text, ScoreWritable, Text, ScoreWritable> {
@Override
protected void map(Text key, ScoreWritable value, Context context)throws IOException, InterruptedException
{
context.write(key, value);
}
}
public static class ScoreReduce extends Reducer<Text, ScoreWritable, Text, Text> {
private Text text = new Text();
protected void reduce(Text key, Iterable<ScoreWritable> Values, Context context) throws IOException, InterruptedException {
float totalScore = 0.0f;
float averageScore = 0.0f;
for(ScoreWritable ss:Values) {
totalScore = ss.getChinese() + ss.getMath() + ss.getEnglish() + ss.getPhysics() + ss.getChemistry();
averageScore += totalScore/5;
}
text.set(totalScore + "\t" + averageScore);
context.write(key, text);
}
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
String[] args0 =
{
"hdfs://Centpy:9000/score/score.txt",
"hdfs://Centpy:9000/score/out/"
};
int ec = ToolRunner.run(new Configuration(), new ScoreCount(), args0);
System.exit(ec);
}
@Override
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();//读取配置文件
//创建输出路径
Path myPath = new Path(args[1]);
FileSystem hdfs = myPath.getFileSystem(conf);
if (hdfs.isDirectory(myPath)) {
hdfs.delete(myPath, true);
}
Job job = new Job(conf, "ScoreCount");//新建任务
job.setJarByClass(ScoreCount.class);//设置主类
FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径
job.setMapperClass(ScoreMapper.class);// Mapper
job.setReducerClass(ScoreReduce.class);// Reducer
job.setMapOutputKeyClass(Text.class);// Mapper key输出类型
job.setMapOutputValueClass(ScoreWritable.class);// Mapper value输出类型
job.setInputFormatClass(ScoreInputFormat.class);//设置自定义输入格式
job.waitForCompletion(true);
return 0;
}
}
3. 项目测试
输入文件如下:
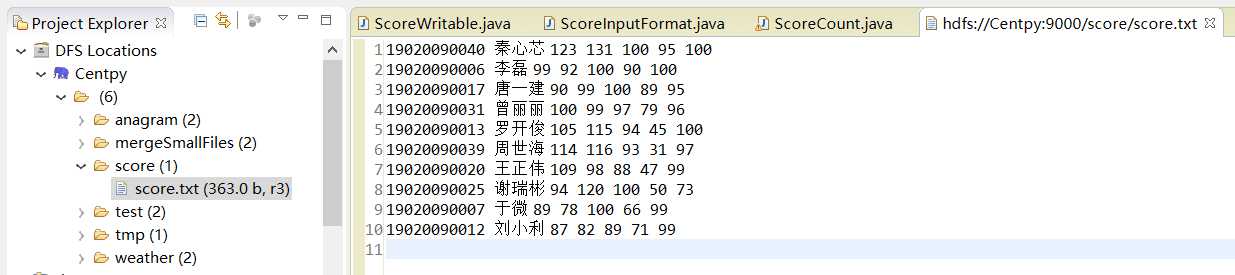
运行后结果如图:
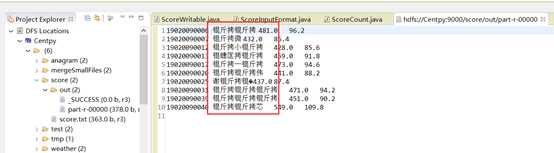
结果中出现了乱码!为什么会有这种情况呢?因为MapReduce采用的默认编码方式是UTF-8,而我上传的输入文件中有中文且不是采用UTF-8编码格式,所以会出现乱码。解决方法如下。
并且,为了保证编码格式一致,先检查eclipse编码格式是否为UTF-8,不是则修改eclipse编码格式为UTF-8。Windows -> Preferences。
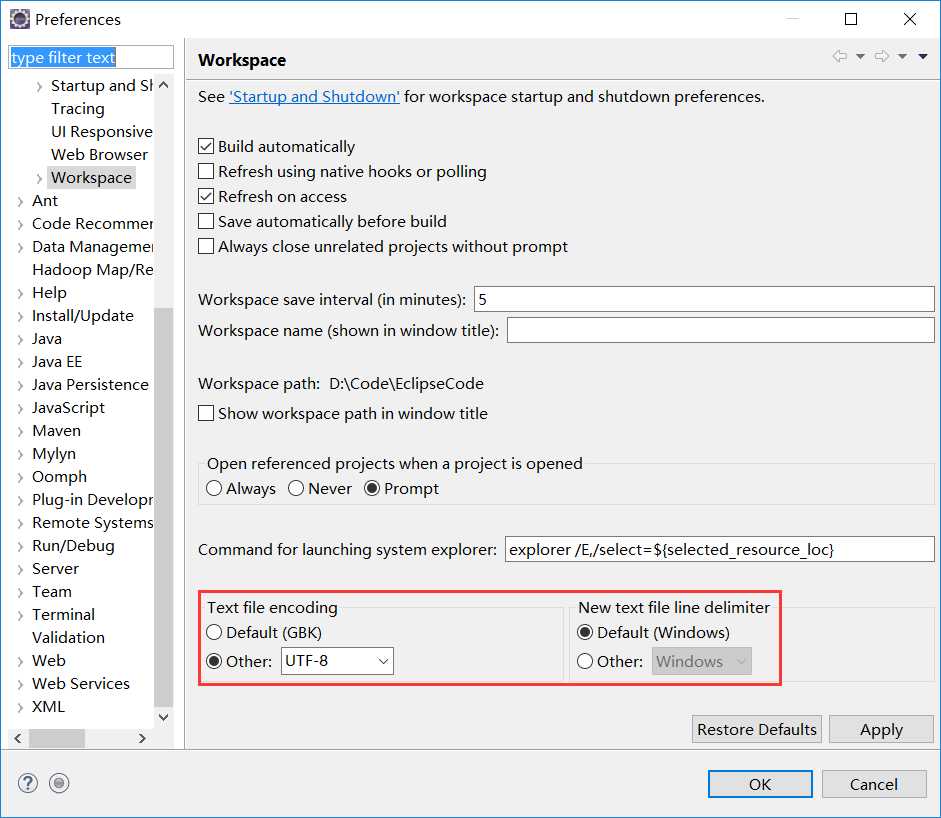
最后,重新运行一次,结果如下。
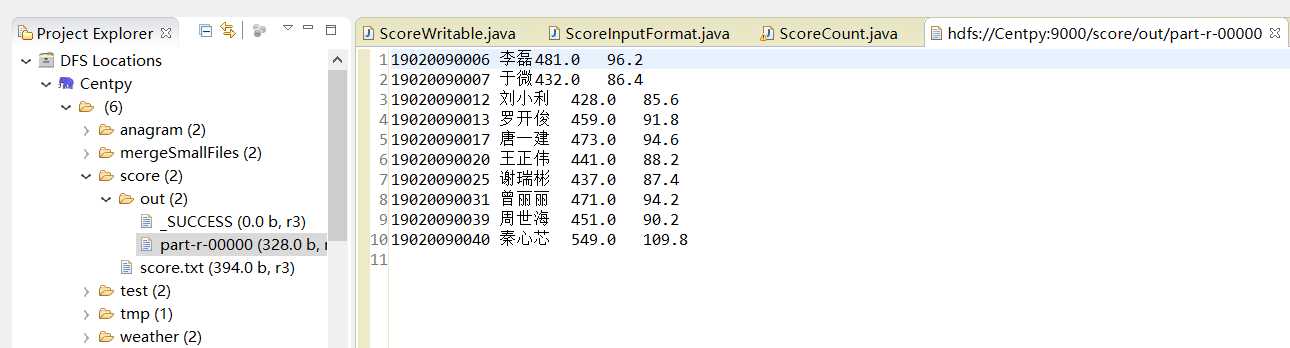
到此,项目就完美地结束了。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。