一、RDD算子分类
1. RDD算子分类及概述
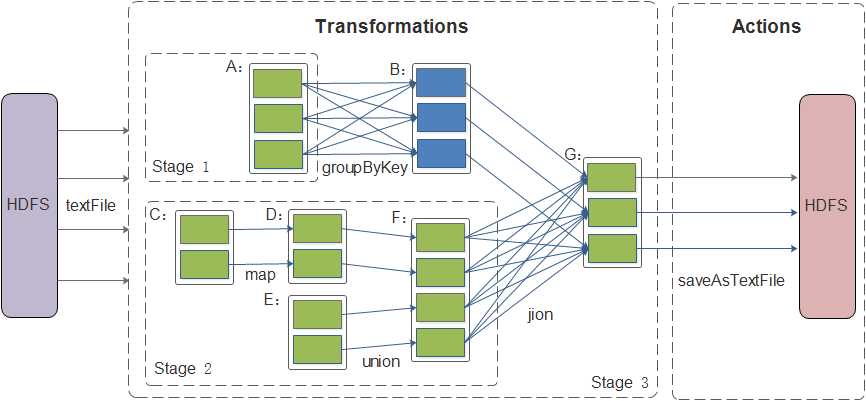
RDD的算子分为Transformation和Action两类,Transformation是延迟执行,Action是立即执行。Transformation和Action本质上的区别是,Transformation是从一个RDD到一个RDD,Action是从一个RDD到一个值。由下图可知,Spark的的转换算子与操作算子的执行流程。首先可以从HDFS中使用textFile方法将数据加载到内存,然后经过转换算子对RDD进行转换,最后再通过操作算子Actions,如saveAsTextFile,将结果存回HDFS中去。
2. 源码解读Transformation算子与Action算子的本质区别
- Transformation本质
//例如flatMap,应用在RDD上,结果是new MapPartitionsRDD,这个方法就结束了。 /** * Return a new RDD by first applying a function to all elements of this * RDD, and then flattening the results. */ def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope { val cleanF = sc.clean(f) new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF)) }
- Action本质
//例如reduce,应用在RDD上,结果是使用sc执行了runJob方法。 /** * Reduces the elements of this RDD using the specified commutative and * associative binary operator. */ def reduce(f: (T, T) => T): T = withScope { val cleanF = sc.clean(f) val reducePartition: Iterator[T] => Option[T] = iter => { if (iter.hasNext) { Some(iter.reduceLeft(cleanF)) } else { None } } var jobResult: Option[T] = None val mergeResult = (index: Int, taskResult: Option[T]) => { if (taskResult.isDefined) { jobResult = jobResult match { case Some(value) => Some(f(value, taskResult.get)) case None => taskResult } } } sc.runJob(this, reducePartition, mergeResult) // Get the final result out of our Option, or throw an exception if the RDD was empty jobResult.getOrElse(throw new UnsupportedOperationException("empty collection")) }
二、常用Transformations算子及释义
1. textFile
将文件加载到内存,抽象成一个RDD,是一个Transformation操作。
2. map
map(f:T=>U) : RDD[T]=>RDD[U]
map函数需要一个参数,此参数是一个匿名函数,在参数进来时使用f来接收。这个匿名函数需要的参数进来时是T类型,进过匿名函数转化之后变成U类型。这些算子都是操作在RDD上的,那么函数map(f:T=>U)的功能是把一个RDD[T],这RDD里面每个元素是类型的转成U类型。map函数实质上就是对RDD集合中的每个元素依次进行操作。
3. filter
filter(f:T=>Bool) : RDD[T]=>RDD[T]
filter函数,传一个匿名函数进来,参数为T,匿名函数转换后变成Boolean类型,如果参数是True就被保留下来,如果是False就被过滤掉。RDD[T]=>RDD[T],filter作用前后RDD中的元素都是T类型,只是把不符合的元素去除了。
4. flatmap
flatmap(f:T=>Seq[U]) : RDD[T]=>RDD[U]
一个flat+一个map,map是对集合的每个元素进行操作,flat英文直译是压扁,flatmap(f:T=>Seq[U])中的Seq是集合序列之意。例如,一个英文句子,进行分词可以按空格隔开,句子进来就是String类型,对每个元素进行分词就是一个个单词组成的String数组,这就是一个Seq集合;如果对于一个句子使用map的话出去的还是一个句子。因为map之后是一个数组,并没有打散成为一个个单词,所以flat的作用就在于此。
5. sample
sample(fraction:Float) : RDD[T]=>RDD[T](Deterministic sampling)
传入浮点数,采样。
6. groupByKey
groupByKey() : RDD[(K,V)]=>RDD[(K,Seq[V])]
按Key进行分组,必须运用于一个元素为键值对形式的RDD,可以按照Key进行分组,把相同Key的值放到一个集合中去。
7. reduceByKey
reduceByKey(f:(V,V)=>V) : RDD[(K,V)]=>RDD[(K,V)]
reduceByKey=一个groupByKey()+一个reduce。先groupByKey(),把相同的Key的value放到一个序列中;然后进行reduce操作,例如:_+_就是把每一个元素依次进行操作。RDD进来时的每一个元素是(K,V),这里的Key可能重复;出去的RDD的元素也是(K,V),但是这里的Key无重复,因为有groupByKey()操作。
8. union
union() : (RDD[T], RDD[T])=>RDD[T]
union意为联合,把两个相同元素类型的RDD,转化到一起去。
9. join
join() : (RDD[(K,V)], RDD[(K,W)]) => RDD[(K,(V,W))]
join是把两个以键值对形式的为元素的RDD,按K进行分组,转化成一个RDD,这个RDD的元素依旧是键值对形式,键为K,值为由原来相同键的值组成的元组。
10. cogroup
cogroup() : (RDD[(K,V)], RDD[(K,W)])=> RDD[(K,(Seq[V],Seq[W]))]
cogroup把两个RDD变成一个RDD,最后的RDD是键值对形式,按K分组,把值V和W变成,数组序列。
11. crossProduct
crossProduct() : (RDD[T],RDD[U])=>RDD[(T,U)]
把两个RDD中的元素放到一个RDD中,并且分别作为最终RDD元素的键和值。
12. mapValues
mapValues(f:V=>W) : RDD[(K,V)]=>RDD[(K,W)](Preserves partitioning)
mapValues是对RDD中的每个元素(K,V)中的V进行map操作,K保持不变。
13. sort
sort(c:Comparator[K]) : RDD[(K,V)]=>RDD[(K,V)]
sort进行排序,至于排序方法是和传进来的Comparator有关。RDD[(K,V)] => RDD[(K,V)],元素本身没有变,只是进行了排序。
14. sortBykey
和sort类似,sortByKey是根据键进行排序。
15. sortBy
sortBy与sortByKey不同,sortBy可以指定根据集合中的第几个元素进行排序。例如根据value排序,rdd.sortBy(_._2)。
16. partitionBy
partitionBy(p:Partitioner[K]) : RDD[(K,V)]=>RDD[(K,V)]
可以传入自定义的Partitioner,传入Key,然后根据Key重新进行Partitioner。这时再看RDD里的内容是完全没有变化的,只是内部有一个shuffle,重新分组,把数据多机的内存传到另外多机的内存中去。
三、常用Actions算子及释义
1. count
count() : RDD[T]=>Long
count是统计RDD里面元素的数量。因为count不知道RDD元素的个数,所以返回值类型为Long类型。
2. collect
collect() : RDD[T]=>Seq[T]
collect,把一个RDD返回到一个集合序列中去。RDD[T]=>Seq[T],RDD[T]是弹性分布式数据集,Seq[T]是单机的集合。collect是很恐怖的操作,相当于把分布式的数据,拿到当前的机器或当前客户端的程序中来,如果数据量大而且当前机器的内存小的话机器就容易挂掉。
3. reduce
reduce(f:(T,T)=>T) : RDD[T]=>T
reduce和reduceByKey不同,reduceByKey是一个Transformation,而reduce是一个action。reduce可以将以T为元素类型的RDD转成T类型。例如一个集合是(1,4,6,4,1),对它进行reduce就会返回相同的类型的值。
4. lookup
lookup(k:K) : RDD[(K,V)=>Seq[V](On hash/range partitioned RDDs)
根据Key,把Key的value都找出来,然后放到本地的集合序列中去。
5. save
save(path:String) : Outputs RDD to a storage system, e.g., HDFS
save需要传一个路径,把RDD的结果给输出到文件中去,可以是本地的也可以是hdfs的。
6. saveAsTextFile
saveAsTextFlie(path:String) : Outputs RDD to a storage system, e.g., HDFS
这个saveAsTextFlie不能使用本地的路径。
7. foreach
对RDD中的每个元素进行遍历操作。例如,打印RDD的每个元素:
rdd.foreach(println)
更多资源可以参看Zhen He RDD API。