标签:Hadoop 搭建分布式集群环境 MapReduce YARN HDFS
分布式环境搭建之环境介绍之前我们已经介绍了如何在单机上搭建伪分布式的Hadoop环境,而在实际情况中,肯定都是多机器多节点的分布式集群环境,所以本文将简单介绍一下如何在多台机器上搭建Hadoop的分布式环境。
我这里准备了三台机器,IP地址如下:
首先在这三台机器上编辑/etc/hosts配置文件,修改主机名以及配置其他机器的主机名
[root@localhost ~]# vim /etc/hosts # 三台机器都需要操作
192.168.77.128 hadoop000
192.168.77.130 hadoop001
192.168.77.134 hadoop002
[root@localhost ~]# reboot三台机器在集群中所担任的角色:
集群之间的机器需要相互通信,所以我们得先配置免密码登录。在三台机器上分别运行如下命令,生成密钥对:
[root@hadoop000 ~]# ssh-keygen -t rsa # 三台机器都需要执行这个命令生成密钥对
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
0d:00:bd:a3:69:b7:03:d5:89:dc:a8:a2:ca:28:d6:06 root@hadoop000
The key‘s randomart image is:
+--[ RSA 2048]----+
| .o. |
| .. |
| . *.. |
| B +o |
| = .S . |
| E. * . |
| .oo o . |
|=. o o |
|*.. . |
+-----------------+
[root@hadoop000 ~]# ls .ssh/
authorized_keys id_rsa id_rsa.pub known_hosts
[root@hadoop000 ~]# 以hadoop000为主,执行以下命令,分别把公钥拷贝到其他机器上:
[root@hadoop000 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop000
[root@hadoop000 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop001
[root@hadoop000 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002注:其他两台机器也需要执行以上这三条命令。
拷贝完成之后,测试能否正常进行免密登录:
[root@hadoop000 ~]# ssh hadoop000
Last login: Mon Apr 2 17:20:02 2018 from localhost
[root@hadoop000 ~]# ssh hadoop001
Last login: Tue Apr 3 00:49:59 2018 from 192.168.77.1
[root@hadoop001 ~]# 登出
Connection to hadoop001 closed.
[root@hadoop000 ~]# ssh hadoop002
Last login: Tue Apr 3 00:50:03 2018 from 192.168.77.1
[root@hadoop002 ~]# 登出
Connection to hadoop002 closed.
[root@hadoop000 ~]# 登出
Connection to hadoop000 closed.
[root@hadoop000 ~]#如上,hadoop000机器已经能够正常免密登录其他两台机器,那么我们的配置就成功了。
到Oracle官网拿到JDK的下载链接,我这里用的是JDK1.8,地址如下:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
使用wget命令将JDK下载到/usr/local/src/目录下,我这里已经下载好了:
[root@hadoop000 ~]# cd /usr/local/src/
[root@hadoop000 /usr/local/src]# ls
jdk-8u151-linux-x64.tar.gz
[root@hadoop000 /usr/local/src]# 解压下载的压缩包,并将解压后的目录移动到/usr/local/目录下:
[root@hadoop000 /usr/local/src]# tar -zxvf jdk-8u151-linux-x64.tar.gz
[root@hadoop000 /usr/local/src]# mv ./jdk1.8.0_151 /usr/local/jdk1.8编辑/etc/profile文件配置环境变量:
[root@hadoop000 ~]# vim /etc/profile # 增加如下内容
JAVA_HOME=/usr/local/jdk1.8/
JAVA_BIN=/usr/local/jdk1.8/bin
JRE_HOME=/usr/local/jdk1.8/jre
PATH=$PATH:/usr/local/jdk1.8/bin:/usr/local/jdk1.8/jre/bin
CLASSPATH=/usr/local/jdk1.8/jre/lib:/usr/local/jdk1.8/lib:/usr/local/jdk1.8/jre/lib/charsets.jar
export PATH=$PATH:/usr/local/mysql/bin/使用source命令加载配置文件,让其生效,生效后执行java -version命令即可看到JDK的版本:
[root@hadoop000 ~]# source /etc/profile
[root@hadoop000 ~]# java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
[root@hadoop000 ~]# 在hadoop000上安装完JDK后,通过rsync命令,将JDK以及配置文件都同步到其他机器上:
[root@hadoop000 ~]# rsync -av /usr/local/jdk1.8 hadoop001:/usr/local
[root@hadoop000 ~]# rsync -av /usr/local/jdk1.8 hadoop002:/usr/local
[root@hadoop000 ~]# rsync -av /etc/profile hadoop001:/etc/profile
[root@hadoop000 ~]# rsync -av /etc/profile hadoop002:/etc/profile同步完成后,分别在两台机器上source配置文件,让环境变量生效,生效后再执行java -version命令测试JDK是否已安装成功。
下载Hadoop 2.6.0-cdh5.7.0的tar.gz包并解压:
[root@hadoop000 ~]# cd /usr/local/src/
[root@hadoop000 /usr/local/src]# wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
[root@hadoop000 /usr/local/src]# tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C /usr/local/注:如果在Linux上下载得很慢的话,可以在windows的迅雷上使用这个链接进行下载。然后再上传到Linux中,这样就会快一些。
解压完后,进入到解压后的目录下,可以看到hadoop的目录结构如下:
[root@hadoop000 /usr/local/src]# cd /usr/local/hadoop-2.6.0-cdh5.7.0/
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0]# ls
bin cloudera examples include libexec NOTICE.txt sbin src
bin-mapreduce1 etc examples-mapreduce1 lib LICENSE.txt README.txt share
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0]#简单说明一下其中几个目录存放的东西:
以上就算是把hadoop给安装好了,接下来就是编辑配置文件,把JAVA_HOME配置一下:
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0]# cd etc/
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc]# cd hadoop
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8/ # 根据你的环境变量进行修改
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# 然后将Hadoop的安装目录配置到环境变量中,方便之后使用它的命令:
[root@hadoop000 ~]# vim ~/.bash_profile # 增加以下内容
export HADOOP_HOME=/usr/local/hadoop-2.6.0-cdh5.7.0/
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@localhost ~]# source !$
source ~/.bash_profile
[root@localhost ~]#接着分别编辑core-site.xml以及hdfs-site.xml配置文件:
[root@hadoop000 ~]# cd $HADOOP_HOME
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0]# cd etc/hadoop
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# vim core-site.xml # 增加如下内容
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop000:8020</value> # 指定默认的访问地址以及端口号
</property>
</configuration>
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# vim hdfs-site.xml # 增加如下内容
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/app/tmp/dfs/name</value> # namenode临时文件所存放的目录
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/app/tmp/dfs/data</value> # datanode临时文件所存放的目录
</property>
</configuration>
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# mkdir -p /data/hadoop/app/tmp/dfs/name
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# mkdir -p /data/hadoop/app/tmp/dfs/data接下来还需要编辑yarn-site.xml配置文件:
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# vim yarn-site.xml # 增加如下内容
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop000</value>
</property>
</configuration>
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# 拷贝并编辑MapReduce的配置文件:
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# vim !$ # 增加如下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# 最后是配置从节点的主机名,如果没有配置主机名的情况下就使用IP:
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# vim slaves
hadoop000
hadoop001
hadoop002
[root@hadoop000 /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# 到此为止,我们就已经在hadoop000上搭建好了我们主节点(master)的Hadoop集群环境,但是还有其他两台作为从节点(slave)的机器没配置Hadoop环境,所以接下来需要把hadoop000上的Hadoop安装目录以及环境变量配置文件分发到其他两台机器上,分别执行如下命令:
[root@hadoop000 ~]# rsync -av /usr/local/hadoop-2.6.0-cdh5.7.0/ hadoop001:/usr/local/hadoop-2.6.0-cdh5.7.0/
[root@hadoop000 ~]# rsync -av /usr/local/hadoop-2.6.0-cdh5.7.0/ hadoop002:/usr/local/hadoop-2.6.0-cdh5.7.0/
[root@hadoop000 ~]# rsync -av ~/.bash_profile hadoop001:~/.bash_profile
[root@hadoop000 ~]# rsync -av ~/.bash_profile hadoop002:~/.bash_profile分发完成之后到两台机器上分别执行source命令以及创建临时目录:
[root@hadoop001 ~]# source .bash_profile
[root@hadoop001 ~]# mkdir -p /data/hadoop/app/tmp/dfs/name
[root@hadoop001 ~]# mkdir -p /data/hadoop/app/tmp/dfs/data
[root@hadoop002 ~]# source .bash_profile
[root@hadoop002 ~]# mkdir -p /data/hadoop/app/tmp/dfs/name
[root@hadoop002 ~]# mkdir -p /data/hadoop/app/tmp/dfs/data对NameNode做格式化,只需要在hadoop000上执行即可:
[root@hadoop000 ~]# hdfs namenode -format格式化完成之后,就可以启动Hadoop集群了:
[root@hadoop000 ~]# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
18/04/02 20:10:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [hadoop000]
hadoop000: starting namenode, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/hadoop-root-namenode-hadoop000.out
hadoop000: starting datanode, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/hadoop-root-datanode-hadoop000.out
hadoop001: starting datanode, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/hadoop-root-datanode-hadoop001.out
hadoop002: starting datanode, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/hadoop-root-datanode-hadoop002.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host ‘0.0.0.0 (0.0.0.0)‘ can‘t be established.
ECDSA key fingerprint is 4d:5a:9d:31:65:75:30:47:a3:9c:f5:56:63:c4:0f:6a.
Are you sure you want to continue connecting (yes/no)? yes # 输入yes即可
0.0.0.0: Warning: Permanently added ‘0.0.0.0‘ (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/hadoop-root-secondarynamenode-hadoop000.out
18/04/02 20:11:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/yarn-root-resourcemanager-hadoop000.out
hadoop001: starting nodemanager, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/yarn-root-nodemanager-hadoop001.out
hadoop002: starting nodemanager, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/yarn-root-nodemanager-hadoop002.out
hadoop000: starting nodemanager, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/yarn-root-nodemanager-hadoop000.out
[root@hadoop000 ~]# jps # 查看是否有以下几个进程
6256 Jps
5538 DataNode
5843 ResourceManager
5413 NameNode
5702 SecondaryNameNode
5945 NodeManager
[root@hadoop000 ~]#到另外两台机器上检查进程:
hadoop001:
[root@hadoop001 ~]# jps
3425 DataNode
3538 NodeManager
3833 Jps
[root@hadoop001 ~]# hadoop002:
[root@hadoop002 ~]# jps
3171 DataNode
3273 NodeManager
3405 Jps
[root@hadoop002 ~]#各机器的进程检查完成,并且确定没有问题后,在浏览器上访问主节点的50070端口,例如:192.168.77.128:50070。会访问到如下页面: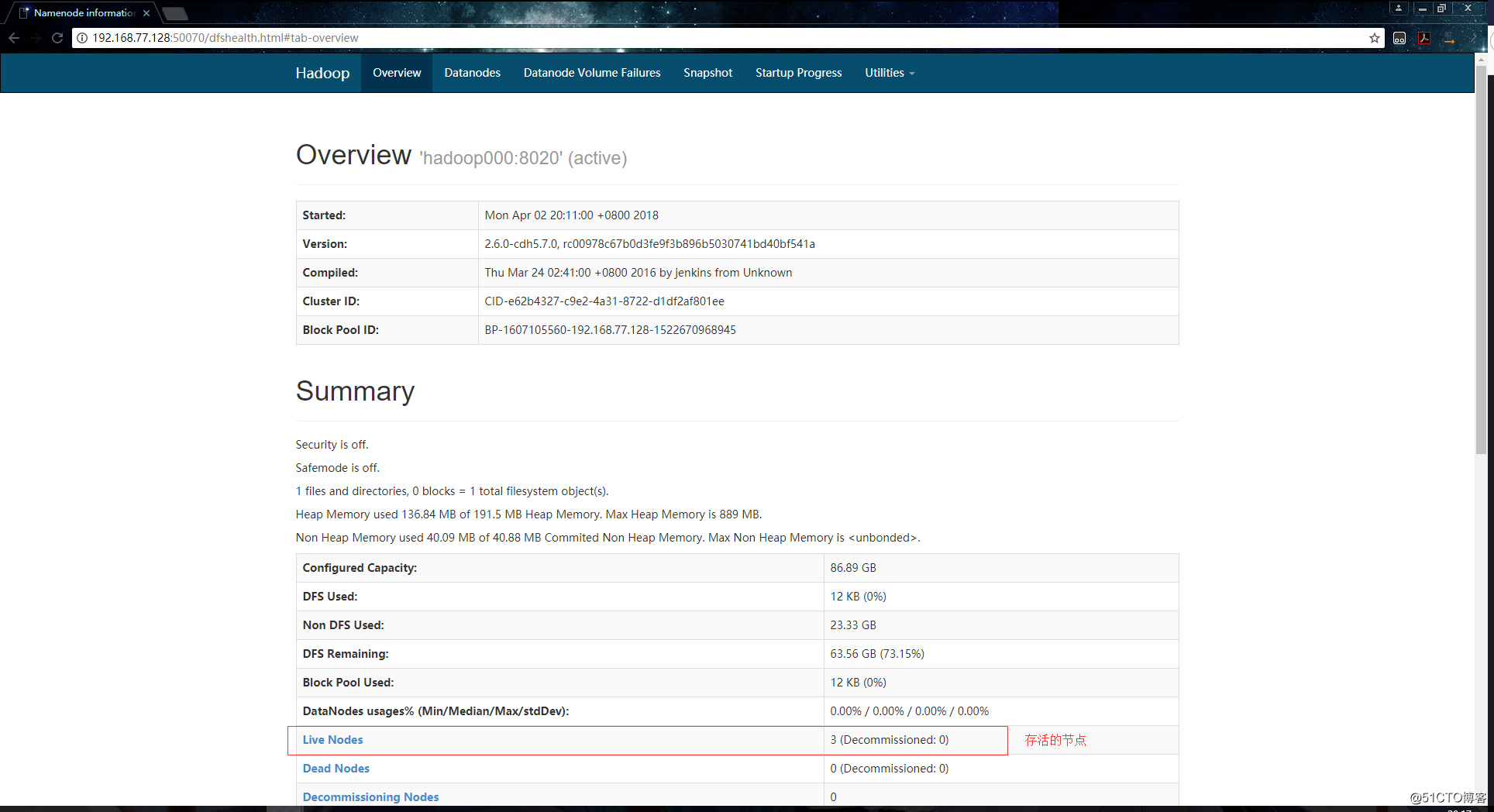
点击 ”Live Nodes“ 查看存活的节点: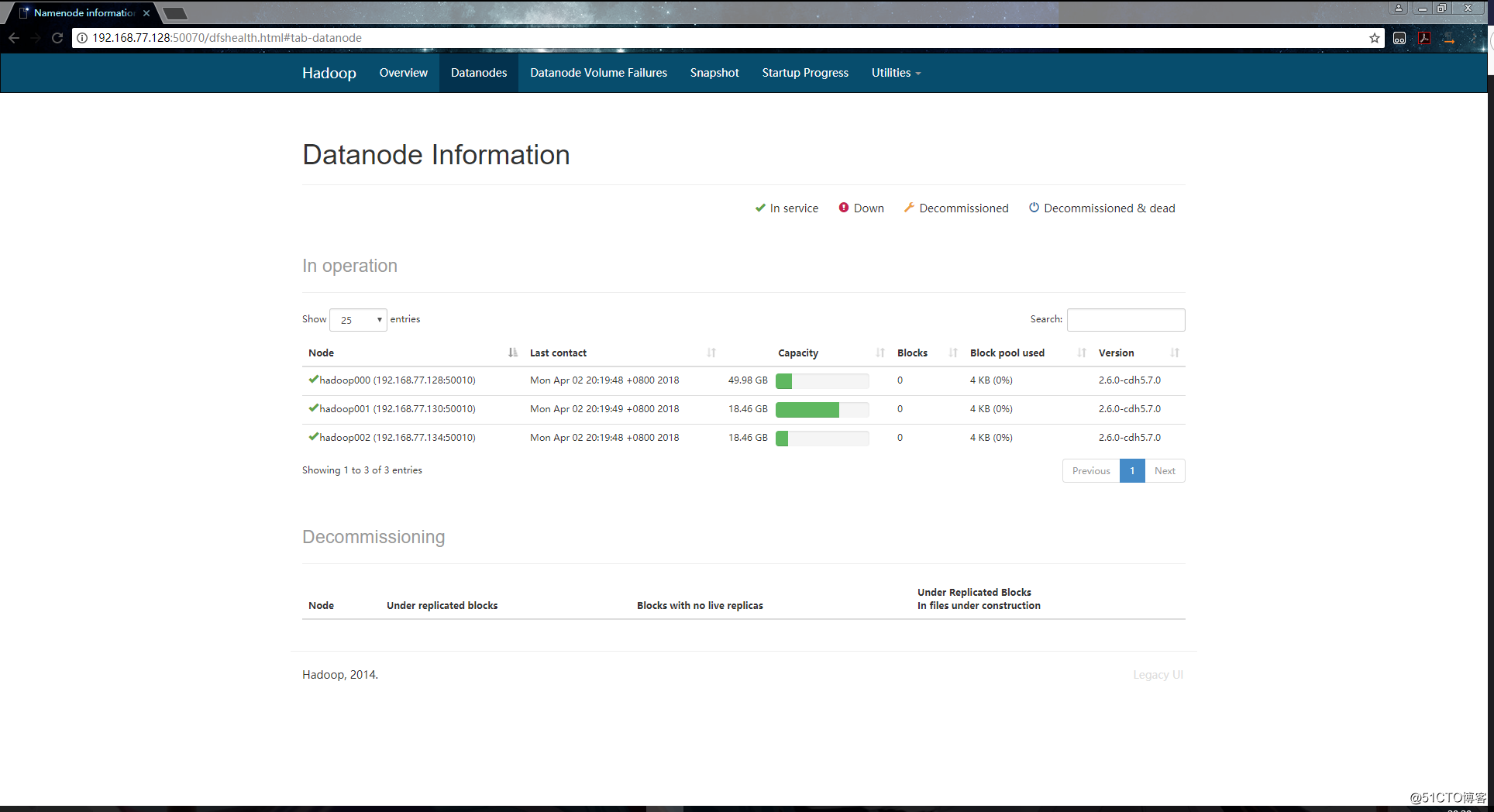
如上,可以访问50070端口就代表集群中的HDFS是正常的。
接下来我们还需要访问主节点的8088端口,这是YARN的web服务端口,例如:192.168.77.128:8088。如下: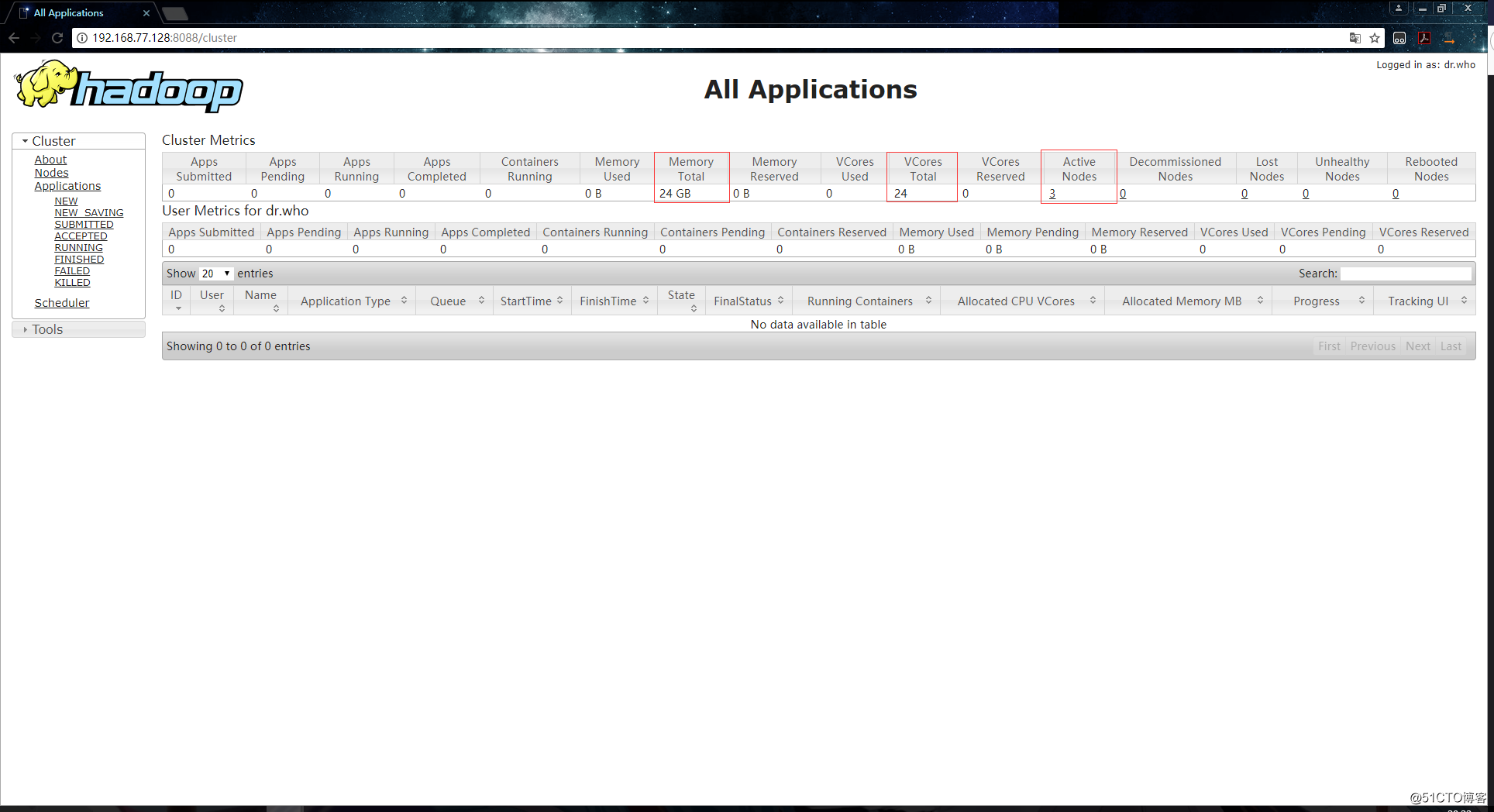
点击 “Active Nodes” 查看存活的节点: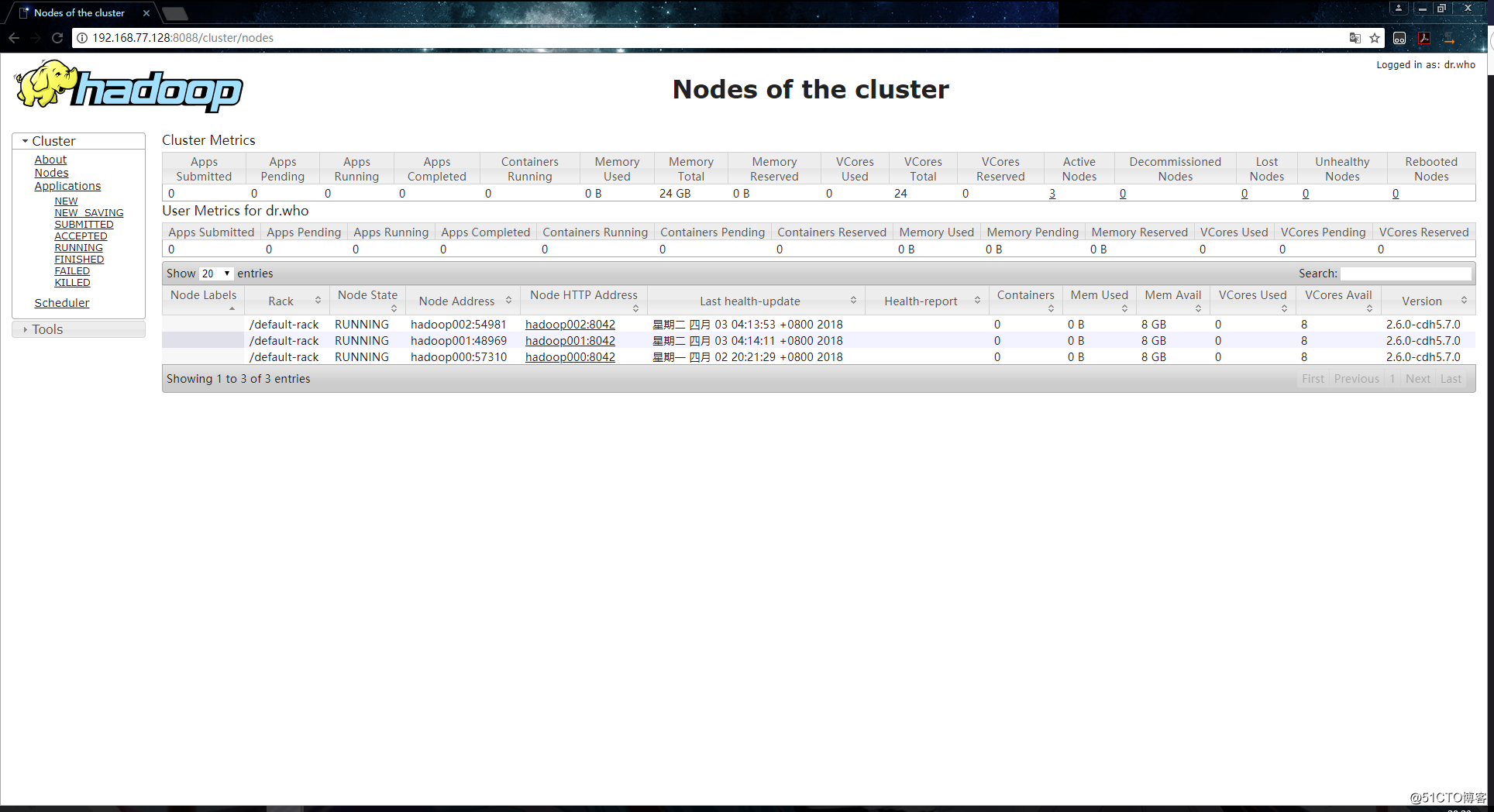
好了,到此为止我们的Hadoop分布式集群环境就搭建完毕了,就是这么简单。那么启动了集群之后要如何关闭集群呢?也很简单,在主节点上执行如下命令即可:
[root@hadoop000 ~]# stop-all.sh实际上分布式环境下HDFS及YARN的使用和伪分布式下是一模一样的,例如HDFS的shell命令的使用方式依旧是和伪分布式下一样的。例如:
[root@hadoop000 ~]# hdfs dfs -ls /
[root@hadoop000 ~]# hdfs dfs -mkdir /data
[root@hadoop000 ~]# hdfs dfs -put ./test.sh /data
[root@hadoop000 ~]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2018-04-02 20:29 /data
[root@hadoop000 ~]# hdfs dfs -ls /data
Found 1 items
-rw-r--r-- 3 root supergroup 68 2018-04-02 20:29 /data/test.sh
[root@hadoop000 ~]# 在集群中的其他节点也可以访问HDFS,而且在集群中HDFS是共享的,所有节点访问的数据都是一样的。例如我在hadoop001节点中,上传一个目录:
[root@hadoop001 ~]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2018-04-02 20:29 /data
[root@hadoop001 ~]# hdfs dfs -put ./logs /
[root@hadoop001 ~]# hdfs dfs -ls /
drwxr-xr-x - root supergroup 0 2018-04-02 20:29 /data
drwxr-xr-x - root supergroup 0 2018-04-02 20:31 /logs
[root@hadoop001 ~]#然后再到hadoop002上查看:
[root@hadoop002 ~]# hdfs dfs -ls /
Found 2 items
drwxr-xr-x - root supergroup 0 2018-04-02 20:29 /data
drwxr-xr-x - root supergroup 0 2018-04-02 20:31 /logs
[root@hadoop002 ~]# 可以看到,不同的节点,访问的数据也是一样的。由于和伪分布式下的操作是一样的,我这里就不再过多演示了。
简单演示了HDFS的操作之后,我们再来运行一下Hadoop自带的案例,看看YARN上是否能获取到任务的执行信息。随便在一个节点上执行如下命令:
[root@hadoop002 ~]# cd /usr/local/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce
[root@hadoop002 /usr/local/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce]# hadoop jar ./hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 3 4
[root@hadoop002 ~]# 申请资源: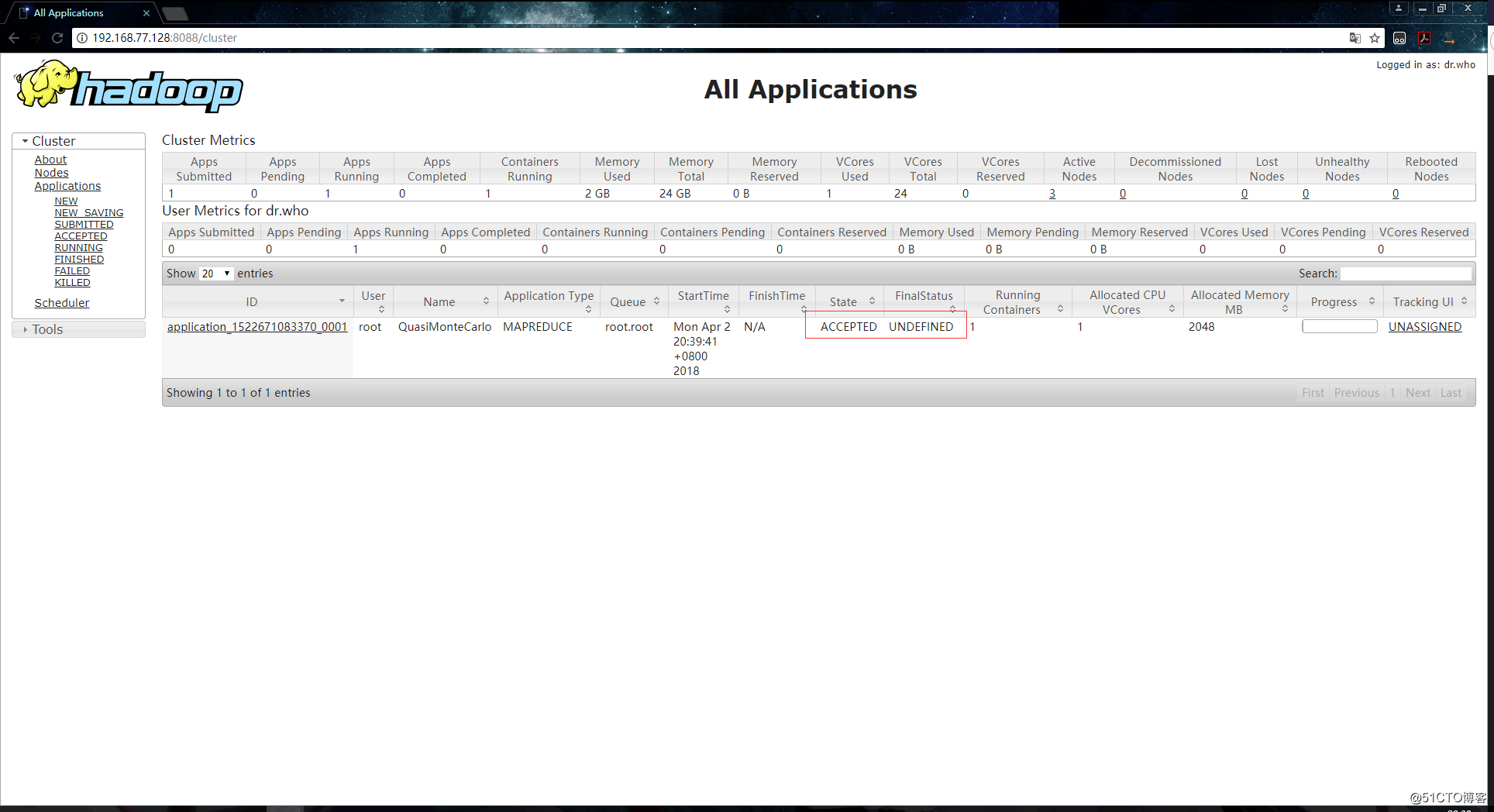
执行任务: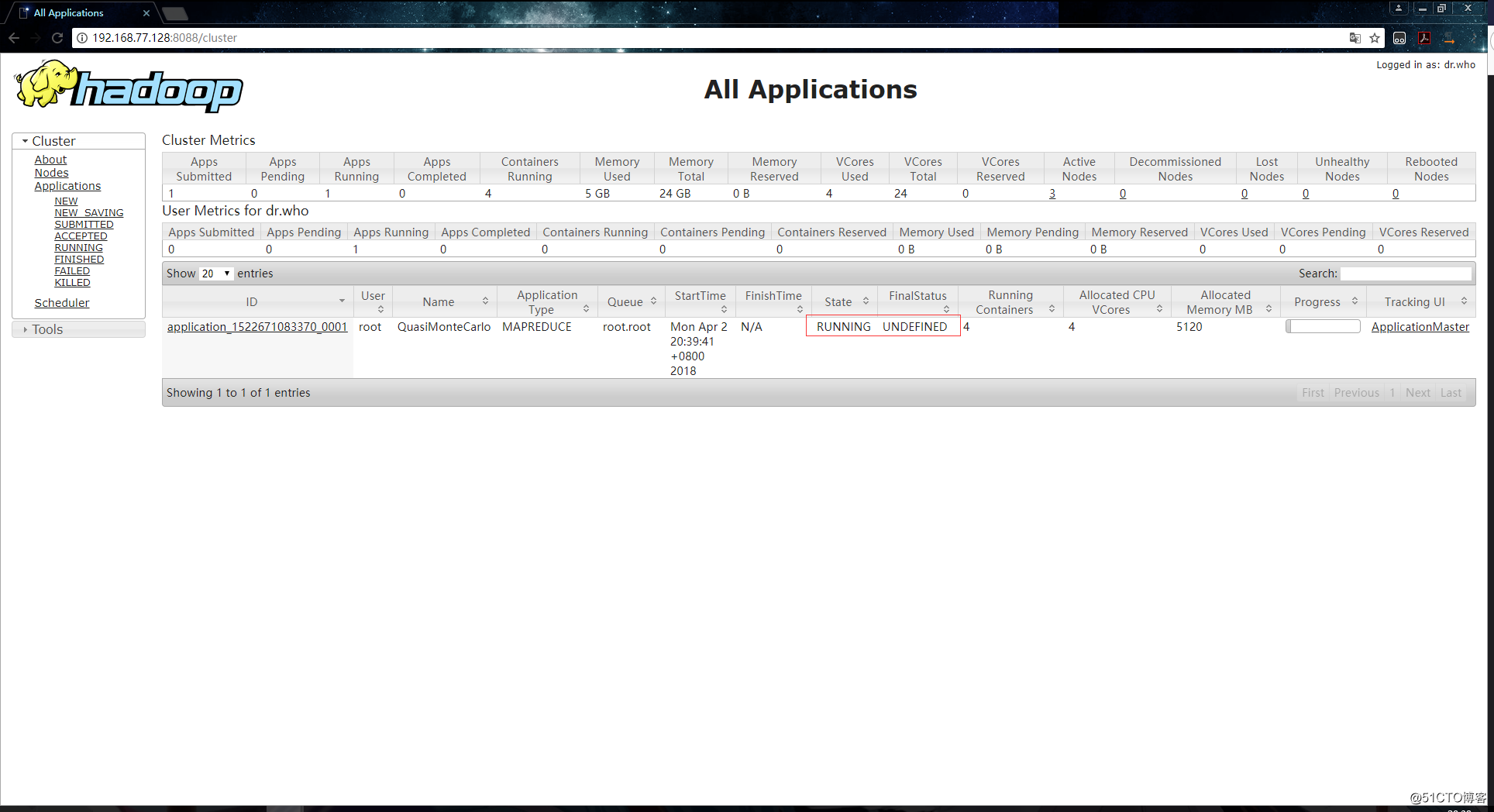
然而我这不幸的执行失败(容我喊一句当妈的撕高达):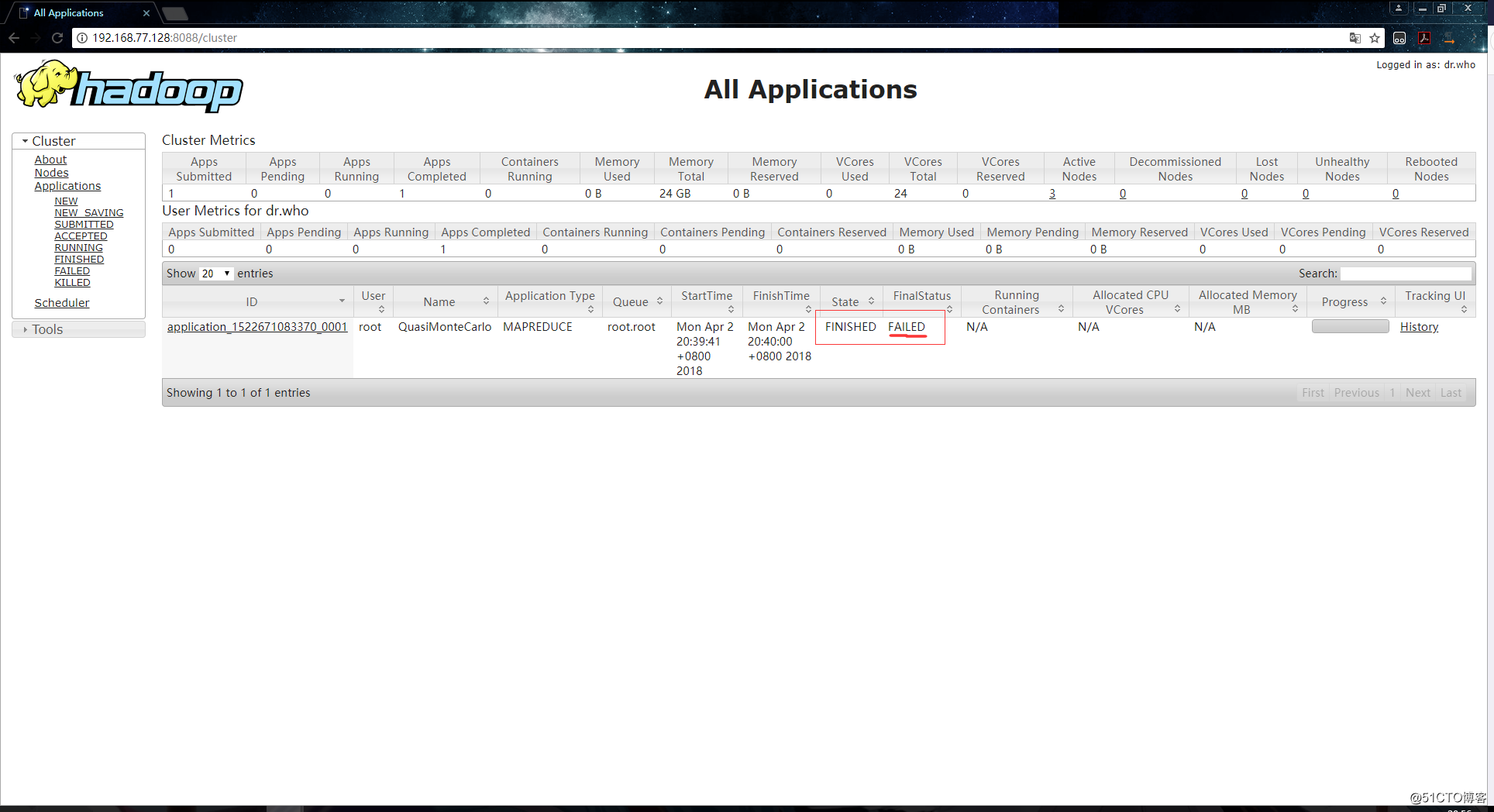
能咋办,只能排错咯,查看到命令行终端的报错信息如下:
Note: System times on machines may be out of sync. Check system time and time zones.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:168)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:159)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:379)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
18/04/03 04:32:17 INFO mapreduce.Job: Task Id : attempt_1522671083370_0001_m_000002_0, Status : FAILED
Container launch failed for container_1522671083370_0001_01_000004 : org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container.
This token is expired. current time is 1522701136752 found 1522673393827
Note: System times on machines may be out of sync. Check system time and time zones.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:168)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:159)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:379)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
18/04/03 04:32:18 INFO mapreduce.Job: Task Id : attempt_1522671083370_0001_m_000001_1, Status : FAILED
Container launch failed for container_1522671083370_0001_01_000005 : org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container.
This token is expired. current time is 1522701157769 found 1522673395895
Note: System times on machines may be out of sync. Check system time and time zones.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:168)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:159)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:379)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
18/04/03 04:32:20 INFO mapreduce.Job: Task Id : attempt_1522671083370_0001_m_000001_2, Status : FAILED
Container launch failed for container_1522671083370_0001_01_000007 : org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container.
This token is expired. current time is 1522701159832 found 1522673397934
Note: System times on machines may be out of sync. Check system time and time zones.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:168)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:159)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:379)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
18/04/03 04:32:23 INFO mapreduce.Job: map 33% reduce 100%
18/04/03 04:32:24 INFO mapreduce.Job: map 100% reduce 100%
18/04/03 04:32:24 INFO mapreduce.Job: Job job_1522671083370_0001 failed with state FAILED due to: Task failed task_1522671083370_0001_m_000001
Job failed as tasks failed. failedMaps:1 failedReduces:0
18/04/03 04:32:24 INFO mapreduce.Job: Counters: 12
Job Counters
Killed map tasks=2
Launched map tasks=2
Other local map tasks=4
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=10890
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=10890
Total vcore-seconds taken by all map tasks=10890
Total megabyte-seconds taken by all map tasks=11151360
Map-Reduce Framework
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Job Finished in 23.112 seconds
java.io.FileNotFoundException: File does not exist: hdfs://hadoop000:8020/user/root/QuasiMonteCarlo_1522701120069_2085123424/out/reduce-out
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1219)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1211)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1211)
at org.apache.hadoop.io.SequenceFile$Reader.<init>(SequenceFile.java:1750)
at org.apache.hadoop.io.SequenceFile$Reader.<init>(SequenceFile.java:1774)
at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:314)
at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71)
at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)虽然报了一大串的错误信息,但是从报错信息中,可以看到第一句是System times on machines may be out of sync. Check system time and time zones.,这是说机器上的系统时间可能不同步。让我们检查系统时间和时区。然后我就检查了集群中所有机器的时间,的确是不同步的。那么要如何同步时间呢?那就要使用到ntpdate命令了,在所有机器上安装ntp包,并执行同步时间的命令,如下:
[root@hadoop000 ~]# yum install -y ntp
[root@hadoop000 ~]# ntpdate -u ntp.api.bz完成之后再次执行之前的命令,这次任务执行成功: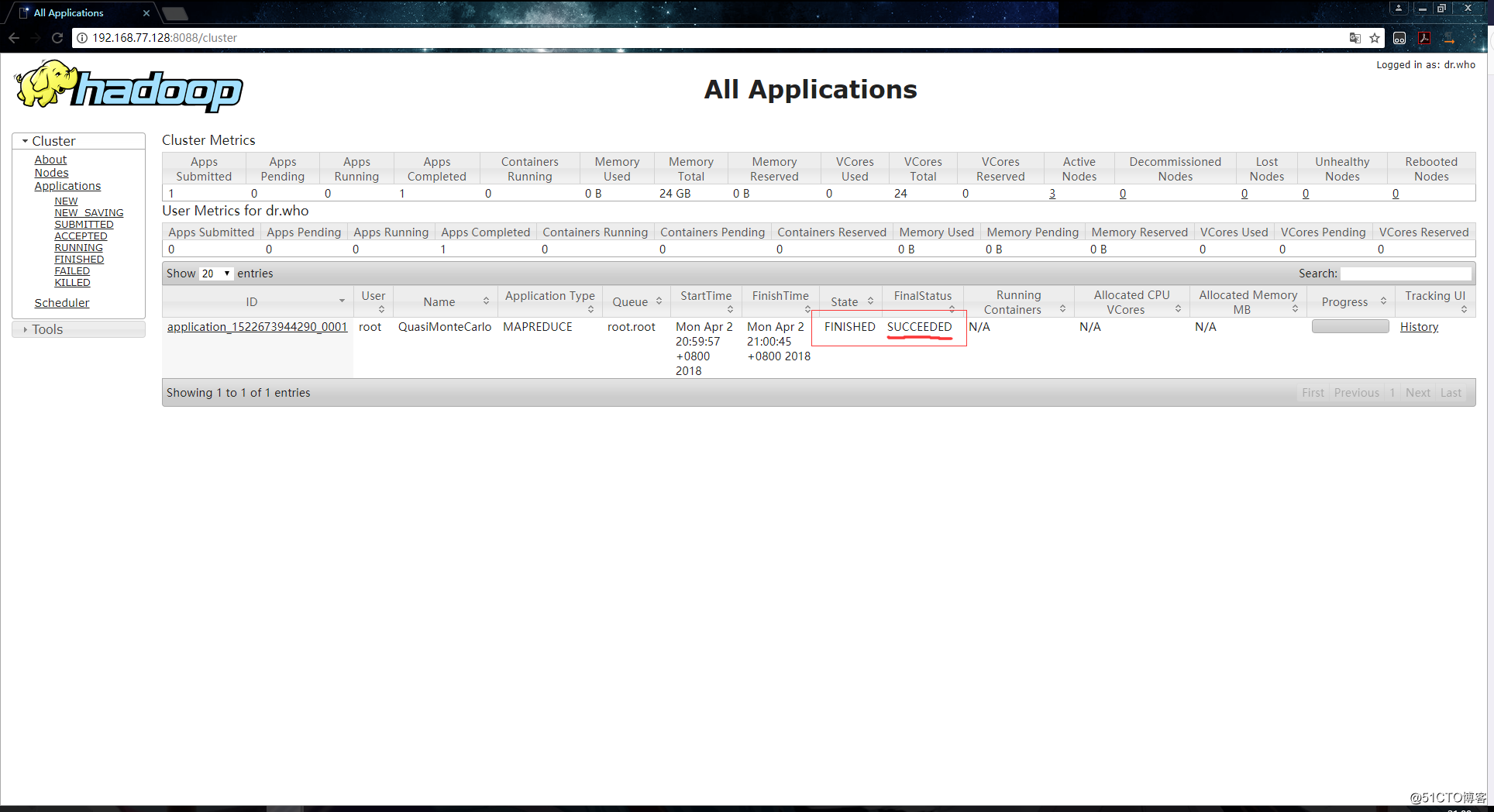
在这之前用Hadoop写了一个统计日志数据的小项目,现在既然我们的集群搭建成功了,那么当然是得拿上来跑一下看看。首先将日志文件以及jar包上传到服务器上:
[root@hadoop000 ~]# ls
10000_access.log hadoop-train-1.0-jar-with-dependencies.jar
[root@hadoop000 ~]# 把日志文件put到HDFS文件系统中:
[root@hadoop000 ~]# hdfs dfs -put ./10000_access.log /
[root@hadoop000 ~]# hdfs dfs -ls /
Found 5 items
-rw-r--r-- 3 root supergroup 2769741 2018-04-02 21:13 /10000_access.log
drwxr-xr-x - root supergroup 0 2018-04-02 20:29 /data
drwxr-xr-x - root supergroup 0 2018-04-02 20:31 /logs
drwx------ - root supergroup 0 2018-04-02 20:39 /tmp
drwxr-xr-x - root supergroup 0 2018-04-02 20:39 /user
[root@hadoop000 ~]#执行以下命令,将项目运行在Hadoop集群之上:
[root@hadoop000 ~]# hadoop jar ./hadoop-train-1.0-jar-with-dependencies.jar org.zero01.hadoop.project.LogApp /10000_access.log /browserout到YARN上查看任务执行时的信息:
申请资源: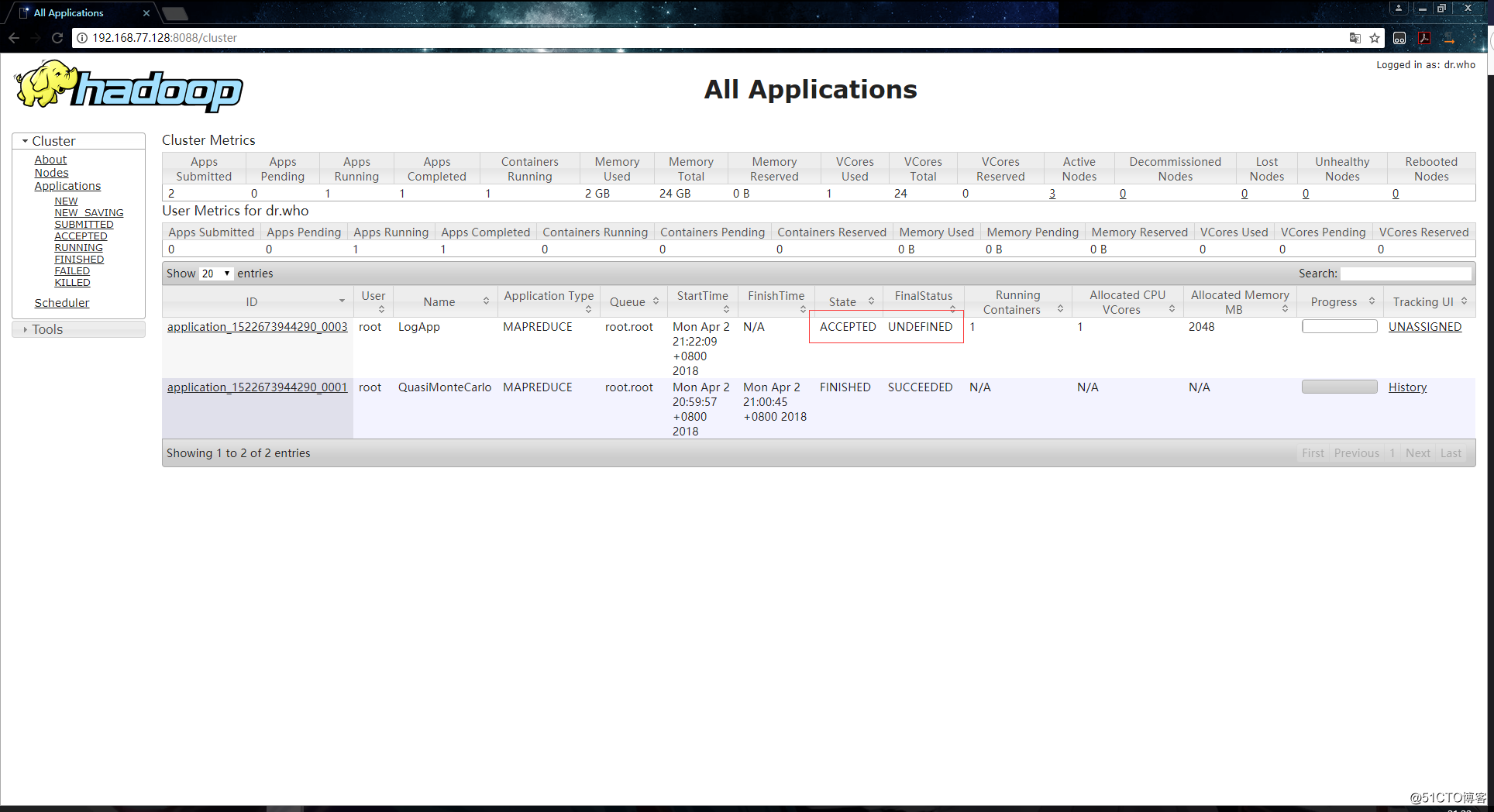
执行任务: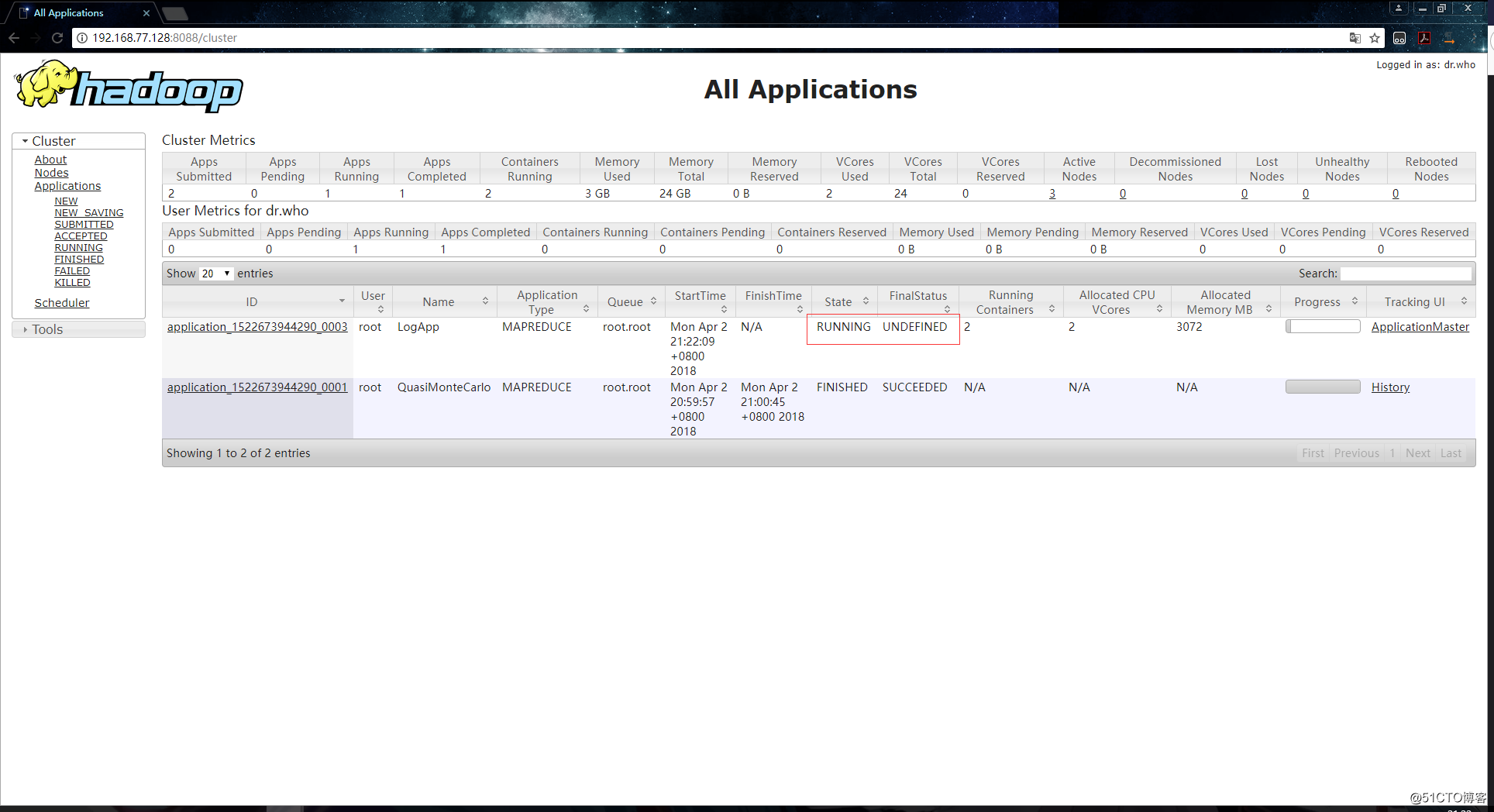
任务执行成功: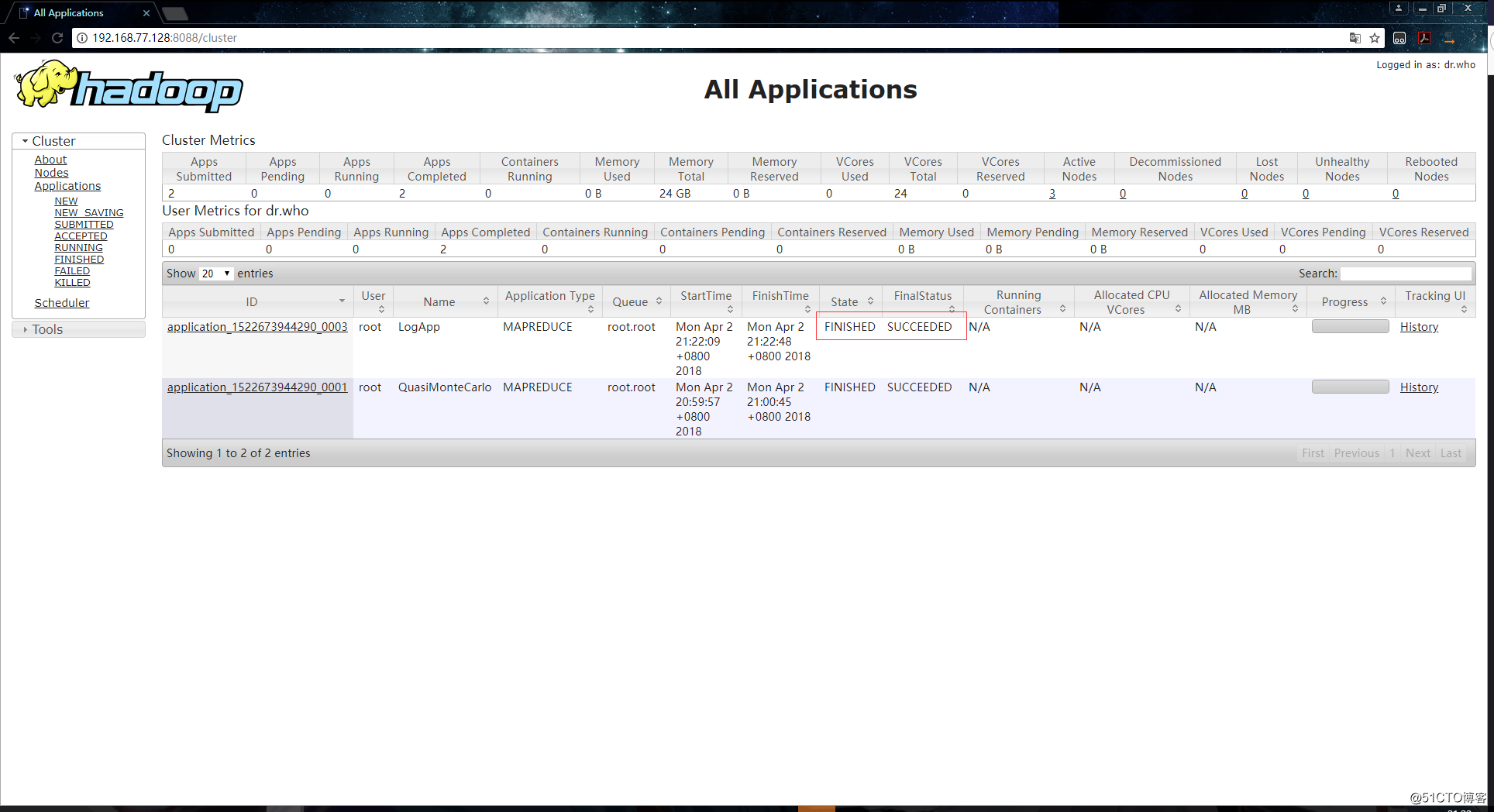
查看输出文件内容:
[root@hadoop000 ~]# hdfs dfs -ls /browserout
Found 2 items
-rw-r--r-- 3 root supergroup 0 2018-04-02 21:22 /browserout/_SUCCESS
-rw-r--r-- 3 root supergroup 56 2018-04-02 21:22 /browserout/part-r-00000
[root@hadoop000 ~]# hdfs dfs -text /browserout/part-r-00000
Chrome 2775
Firefox 327
MSIE 78
Safari 115
Unknown 6705
[root@hadoop000 ~]#处理结果没有问题,到此为止,我们的测试也完成了,接下来就可以愉快的使用Hadoop集群来帮我们处理数据了(当然代码你还是得写的)。
从整个Hadoop分布式集群环境的搭建到使用的过程中,可以看到除了搭建与伪分布式有些许区别外,在使用上基本是一模一样的。所以也建议在学习的情况下使用伪分布式环境即可,毕竟集群的环境比较复杂,容易出现节点间通信障碍的问题。如果卡在这些问题上,导致学习不成还气得不行就得不偿失了233。
标签:Hadoop 搭建分布式集群环境 MapReduce YARN HDFS
原文地址:http://blog.51cto.com/zero01/2093979