HashMap简介
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
众所周知,mashmap的原理是对key值使用哈希函数使得可以快速找到value存储的位置,因此查询效率很高。然而在很长一段时间中,我都以为hash函数是直接映射到value的内存地址,直到今天仔细地搜索了资料才纠正了这一错误的想法。
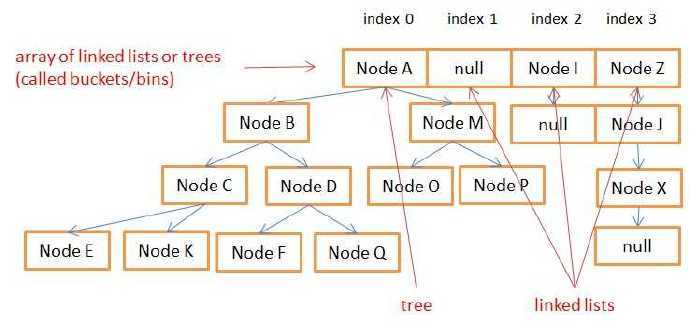
仔细看一下HashMap.class的源码,其中有一些十分重要的默认参数,比如DEFAULT_INITIAL_CAPACITY,它定义了在HashMap实例化时桶的默认大小,而其中桶就是存放键值对的容器,它定义为 Node<K,V>[] table,实际上就是一个键值对的数组,键值对以Node对象封装。关键的问题来了,每次在进行put和get操作时,HashMap根据key值计算出的hash值会对它进行二次哈希,然后再对当前容量取余,计算出一个介于0到当前容量的值,事实上索引的就是前面所说存放键值对的容器中的某个桶,这时候我不禁就会想,如果发生哈希碰撞(事实上在容量较小的时候很容易发生),在同一个桶中如何存放不止一个Node呢?这就是HashMap机智的地方了,当进行put操作,而正好桶中已经存在Node,那么就把这个Node以链表形式连接在它的下一节点。当链表容量比较大时,由于链表顺序查询的性能比较底下,HashMap更机智的设计了红黑树,当一个桶中Node节点超过一定阈值,会自动转为红黑树,当然在这种情况下,也很容易会触发哈希表的扩容。
如有错误,烦请指出!欢迎交流。
参考和引用:http://www.jb51.net/article/80443.htm