一、Zero-Shot learning
? 在传统的分类模型中,为了解决多分类问题(例如三个类别:猫、狗和猪),就需要提供大量的猫、狗和猪的图片用以模型训练,然后给定一张新的图片,就能判定属于猫、狗或猪的其中哪一类。但是对于之前训练图片未出现的类别(例如牛),这个模型便无法将牛识别出来,而ZSL就是为了解决这种问题。在ZSL中,某一类别在训练样本中未出现,但是我们知道这个类别的特征,然后通过语料知识库,便可以将这个类别识别出来。
zero-shot learning的一个重要理论基础就是利用高维语义特征代替样本的低维特征,使得训练出来的模型具有迁移性。语义向量就是高维语义特征,比如一个物体的高维语义为“四条腿,有尾巴,会汪汪叫,宠物的一种”,那我们就可以判断它是狗,高维语义对它没有细节描述,但是能够很好的对其分类,分类是我们的目的,所以可以舍去低维特征,不需要“全面”。
二、DAP模型
《Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer》
? DAP可以理解为一个三层模型:第一层是原始输入层,例如一张电子图片(可以用像素的方式进行描述);第二层是p维特征空间,每一维代表一个特征(例如是否有尾巴、是否有毛等等);第三层是输出层,输出模型对输出样本的类别判断。在第一层和第二层中间,训练p个分类器,用于对一张图片判断是否符合p维特征空间各个维度所对应的特征;在第二层和第三层间,有一个语料知识库,用于保存p维特征空间和输出y的对应关系,这个语料知识库是事先认为设定的(暂时理解是这样?)。
? 假设我们已经训练好了一个DAP模型,第一层和第二层间的分类器可以判断 是否黑眼圈、是否喜欢吃竹子 之类的特征,然后在语料知识库里面包含一个映射:黑眼圈 喜欢吃竹子--> 熊猫,那么即使我们的模型在训练时没有见过熊猫的图片,在遇到熊猫的图片时,我们可以直接通过对图片的特征进行分析,然后结合知识语料库判断出这张图片是熊猫。假设即使语料知识库里面不包含 黑眼圈 喜欢吃竹子--> 熊猫 的映射,我们也可以通过计算熊猫图片的特征与其他训练样本的特征的汉明距离度量,得到熊猫和什么动物比较类似的信息。整个DAP的运作思想就是类似于上述过程。
- 缺点:
- 算法引入了中间层,核心在于尽可能得判定好每幅图像所对应的特征,而不是直接去预测出类别;因此DAP模型在判定属性时可能会做得很好,但是在预测类别时却不一定;
- 无法利用新的样本逐步改善分类器的功能;
- 无法利用额外的属性信息(如Wordnet等)
三、ALE模型
1. 概要
? 在分类问题中,每个类别被映射到属性空间中,即每个类别可用一个属性向量来表示(例如:熊猫—>(黑眼圈,爱吃竹子,猫科动物......))。ALE模型即学习一个函数F,该函数用于衡量每一幅图像和每个属性向量之间的匹配度. ALE模型确保对于每幅图像,和分类正确的类别的相容性比和其他类别的匹配度高。通过在AWA和CUB数据集上的实验表明,ALE模型比DAP等模型在ZSL问题上的表现更好,而且ALE可以利用额外的类别信息来提高模型表现,以及可以从零样本学习迁移到其他拥有大量数据的学习问题中。
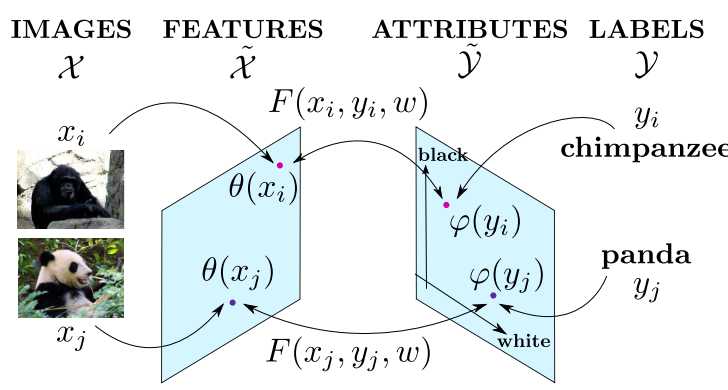
? 在CV领域,大部分的工作都集中与如何从一幅图像里抽取出合适的特征信息(即上图左侧),而在ALE中,研究的重心在于如何把一个类别映射到合适的欧几里得属性空间。
2. 模型推导
? 定义f(x; w)为预测函数,定义F(x, y; w)为输入x和类别y之间的匹配度。则当给定一个需要预测类别的数据x时,预测函数f所做的便是从所有类别y中,找到一个类别y使得F(x, y; w)的值最大。
? 对于模型的参数w的求解过程为:对于所有样本(x, y),尽
可能得最大化 $\frac{1}{n} \sum_{n=1}^{N}{F(x,y;\omega)}$ ,但是对于这个目标函数,在图像分类问题中无法直接优化得出我们的最终目标(具体为什么我也不知道。。。)因此作者从WSABIE算法中得到灵感,并借此来实现ALE算法。
Zero-shot learning:
? 文中借鉴WSABIE算法,得到我们的目标函数为:$\frac {1}{N} \sum_{n=1}^{N} \max_{y∈Y}l(x_n, y_n, y)$.该目标函数和SSVM很类似,对此解释如下:
- 对于每一个样本,计算对应每个类别的得分。然后从其他所有不是正确类别的得分中找出最大的得分;
- 逐样本累加后即得到损失函数的值,然后利用SGD等方法对参数进行更新即可;
- 算法的核心思想和SVM很像,即让错误分类的得分得尽可能得比正确分类的得分小。
Few-shots learning:
? 在上述的Zero-shot learning下对应的模型中,每个类别通过映射$\phi(y)$得到语义空间的值是实现通过先验信息固定的,但是在使用模型预测的过程中,可能会逐步遇到之前训练样本中不存在对应类别的数据,那么ALE就具有能逐步利用新的训练样本来改善模型的作用。在此问题下,模型的目标函数变为:
? $$\frac {1}{N} \sum_{n=1}^{N} \max_{y∈Y}l(x_n, y_n, y) + \frac{\mu }{2}\begin{Vmatrix} \Phi - \Phi ^{\Lambda }\end{Vmatrix}^{2}$$
? 在上述公式中,参数$\Phi$为在一定维度随机初始化的参数。在使用SGD等方法进行参数更新的时候,为使该损失函数的值尽可能得小,显然$\Phi$要尽可能得接近$\Phi^{\Lambda}$,同时也利用了训练样本中存在的部分信息。从而使得AEL模型达到可以逐步利用新的训练样本(之前的训练样本中不存在的类别)的信息来改善模型。
ALE模型如何利用额外的属性等信息来源?
? DAP模型针对每一个属性训练一个分类器,再从属性向量空间里面找到和测试样本最接近的类别。然后ALE并没有特别针对语义向量空间的每一个维度进行学习,ALE直接学习了从特征空间到语义向量空间的映射。其中$\theta(x)$表示从图像得到的特征,$\varphi (y)$则是从类别到语义向量空间的映射。
? 因为$\varphi (y)$是独立于训练数据的,因此可以根据需要变换为其他种类的先验信息,例如HLE模型,而在DAP模型中,因为模型限定了只能对单一属性进行训练,因为就无法利用其他种类的先验信息了。
3. 岭回归(Ridge Regression)
四、SAE模型
1. 概要
? 传统的ZSL问题,经常遇到映射领域漂移问题,在SAE模型中,为了解决这个问题,要求输入x经过变换生成的属性层S,拥有恢复到原来输入层x的功能。通过加入这个限制,确保了映射函数必须尽可能得保留原输入层的所有信息。
映射领域漂移(Projection domain shift)
对于zero-shot learning问题,由于训练模型时,对于测试数据类别是不可见的,因此,当训练集和测试集的类别相差很大的时候,比如一个里面全是动物,另一个全是家具,在这种情况下,传统zero-shot learning的效果将受到很大的影响。
为什么SAE模型可以解决映射领域漂移问题?
2. 介绍
? 如今CV的研究方向已经逐步朝着大规模的分类问题发展了,但是由于在大数据集(如ImageNet)的21814个类别里,有296个类别的图像仅仅只有一个图像数据,因此可扩展性还是一个严峻的问题。
3. 问题
?
五、SCoRE
《Semantically Consistent Regularization for Zero-Shot Recognition》
1. Deep-RIS
要学习样本X到属性向量S的映射W,设训练集
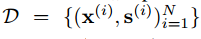
其中x为输入样本,y为样本标签;属性集合为
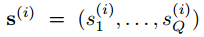
对于Q个属性,为每个属性建立一个CNN,作为属性分类器:
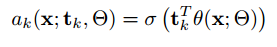
其中,为sigmoid函数。损失函数可以定义为交叉熵损失。
2. Deep-RULE
假设有Q个属性,用二值表示;有C个类别,则可以将每个类别转换为one-hot的形式:

即为类别y的语义编码,则分类器可以定义为:
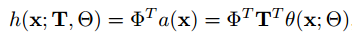
其中表示输入图片的特征表示;
为一个映射矩阵,
表示类别的one-hot表示。若使用神经网络结构实现上述目标函数,只需要先用CNN提取图片的特征,通过一个全连接层将特征映射到语义空间中(也就是学习映射矩阵
),输出时为类别y的形式即可。损失函数直接采用网络输出和真实样本之间的交叉熵损失即可。
3.Deep-RIS和Deep-RULE之间的关系
? 可以从两者的损失函数,来说明它们之间的关系。Deep-RIS对每一个单独的属性ak(x)进行了监督学习,这是一种很强的约束,它把属性向量的表达限制在一个固定的范围内;反观Deep-RULE,它建立了一个语义空间SV,将样本和类别属性化之后,投影到该语义空间中。这样做的结果是:属性向量之间有了相关关系,使得属性向量的表达更加丰富;但同时,会产生冗余空间,这个冗余空间的问题在于,它会加重semantic domain shift的问题。更详细的解释是:设训练集中样本的属性向量所构成的语义空间XV的往往要小于SV,令NV=SV-XV,如果在测试集中,测试样本的属性向量处于NV中,则由训练样本训练出来的分类器将无法对该测试样本进行分类。在Deep-RIS中,对于样本到属性向量之间的映射有着非常强的约束,使得XV和SV相近。在同样的属性定义的前提下,由于NV的存在,使得Deep-RULE更有可能无法处理测试集中的类别。
? 通过上面的论述其实可以知道,如果NV很小,几乎没有测试集类别的属性向量位于其中,则Deep-RULE的方法会取得更好的效果;如果NV很大,测试集中很多类别的属性向量位于其中,则Deep-RIS的方法可能会更好。
? 通过对上述两类方法的分析,可以发现,两种方法存在互补性。如果能够将Deep-RIS对于单个属性的约束融入到Deep-RULE中,就可以一定程度上使得NV变小,从而得到更好的结果。
? 以DAP和ALE两种典型的模型为例,当采用属性作为语义空间的表达时,两者属性空间的构成基本是一致的,都是由一系列的属性构成(例如有尾巴、会飞等)。最核心的不同在于DAP针对每一个属性监督学习一个分类器(如SVM),因此训练样本所包含的属性空间信息往往和整个属性空间差别很小。DAP对于每一个测试类别,输出一个维度为D(属性的个数)的向量。且DAP没有学习到属性之间的依赖关系,比如“水中动物”和“有翅膀”这两个属性就有着很强的负相关,则表明了我们可以利用更少的属性维度去表达和之前一样的信息。
? 而ALE直接从输入的特征空间学习一个到属性空间的映射,在训练过程中采用rank函数——确保所有正确类别的得分都比错误类别高。模型的输出是一个维度为C(类别个数)的变量,表示测试数据在每一个类别上的得分情况。因此ALE是从类别C的维度去进行监督学习的。在ALE训练完成后,训练样本里存在的类别在测试时对应的得分也会最大,但是对于训练样本中不存在的类别(ZS类),因为在训练时没有数据可以用于ZS类的监督学习,所有在测试时ZS类的得分表现就没有那么好。
? 因为属性空间是利用先验知识对所有类别映射而成的,因此存在一些属性只有在ZS类别里存在,而在训练类别里不存在。。。
4. 问题
Abstract: The latter addresses this issue but leaves part of the semantic space unsupervised.
ALE和DAP中两个参数W之间的区别?
六、word2vec
1. 词向量基础(one hot or 1-of N)
2. CBOW模型
对小型数据库比较合适
3. Skip-Gram模型
在大型预料中表现更好
七、迁移学习
什么是迁移学习 (Transfer Learning)?这个领域历史发展前景如何?
目前ZSL还是不能摆脱对其他模态信息的依赖:比如标注的属性,或者用wordvec去提语义特征,多数做法是将视觉特征嵌入到其他模态空间,或者将多个模态特征映射到一个公共latent空间,利用最近邻思想实现对未见类的分类,本质上也是一种知识迁移。
Transfer Learning涉及的范围就很大了,最近我也在看,涉及的细分领域比如Domain Adaptation等等,许多Transfer Learning中的技术也用于提高ZSL的性能,比如将Self-taughting Learning,Self-Paced Learning的思想可以用到Transductive ZSL中提高ZSL的算法性能。