链接:https://kexue.fm/archives/5253
分布变换
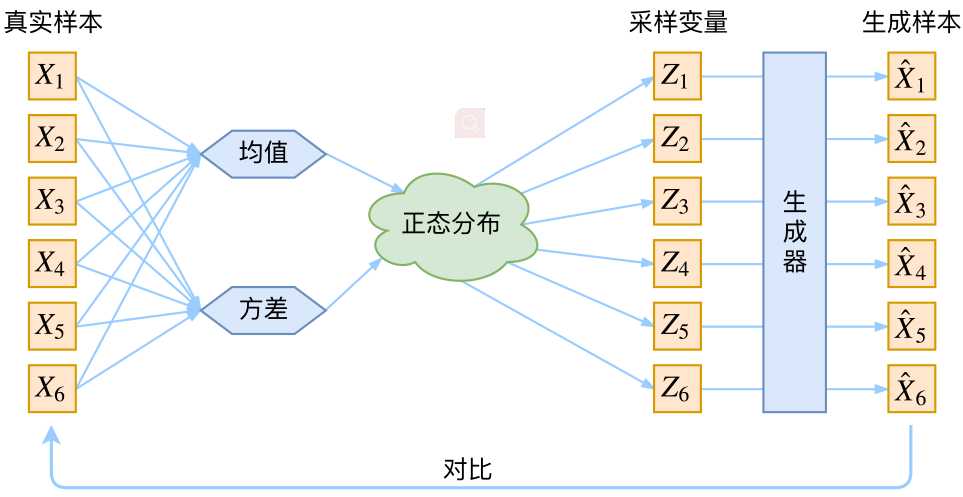
通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量Z生成目标数据X的模型,但是实现上有所不同。更准确地讲,它们是假设了Z服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型X=g(Z),这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
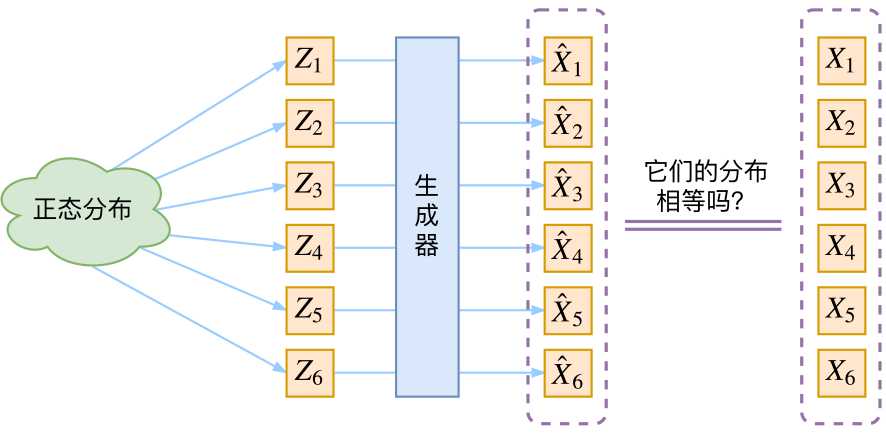
生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式
那现在假设Z服从标准的正态分布,那么我就可以从中采样得到若干个Z1,Z2,…,Zn,然后对它做变换得到X’1=g(Z1),X’2=g(Z2)…,X’n=g(Zn)g有读者说不是有KL散度吗?当然不行,因为KL散度是根据两个概率分布的表达式来算它们的相似度的,然而目前我们并不知道它们的概率分布的表达式,我们只有一批从构造的分布采样而来的数据{X’1,X’2…,X’n},还有一批从真实的分布采样而来的数据{X1,X2,…,Xn}(也就是我们希望生成的训练集)。我们只有样本本身,没有分布表达式,当然也就没有方法算KL散度。
虽然遇到困难,但还是要想办法解决的。GAN的思路很直接粗犷:既然没有合适的度量,那我干脆把这个度量也用神经网络训练出来吧。就这样,WGAN就诞生了,详细过程请参考《互怼的艺术:从零直达WGAN-GP》。而VAE则使用了一个精致迂回的技巧。
VAE慢谈
这一部分我们先回顾一般教程是怎么介绍VAE的,然后再探究有什么问题,接着就自然地发现了VAE真正的面目。
经典回顾

这里我们就不区分求和还是求积分了,意思对了就行。此时p(X|Z)就描述了一个由Z来生成X的模型,而我们假设Z服从标准正态分布,也就是p(Z)=N(0,I),如果这个理想能实现,那么我们就可以先从标准正态分布中采样一个Z,然后根据Z来算一个X,也是一个很棒的生成模型。