import requests
from bs4 import BeautifulSoup
url = ‘http://news.gzcc.cn/html/xiaoyuanxinwen/‘
res = requests.get(url)
res.encoding = ‘utf-8‘
soup = BeautifulSoup(res.text,‘html.parser‘)
for news in soup.select(‘li‘):
if len(news.select(‘.news-list-title‘)) > 0:
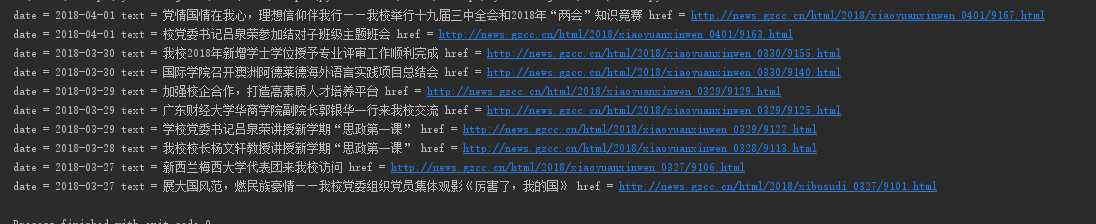
d = news.select(‘.news-list-info‘)[0].contents[0].text
t = news.select(‘.news-list-title‘)[0].text
a = news.select(‘a‘)[0].attrs[‘href‘]
print("date = "+d, "text = "+t, "href = "+a)
for news in soup.select(‘li‘):
if len(news.select(‘.news-list-title‘)) > 0:
d = news.select(‘.news-list-info‘)[0].contents[0].text
t = news.select(‘.news-list-title‘)[0].text
a = news.select(‘a‘)[0].attrs[‘href‘]
# print("date = "+d, "text = "+t, "href = "+a)
resd = requests.get(a)
resd.encoding = ‘utf-8‘
soupd = BeautifulSoup(resd.text, ‘html.parser‘)
c = soupd.select(‘#content‘)[0].text
info = soupd.select(".show-info")
# print(info)
print(info[0].text)

for news in soup.select(‘li‘):
if len(news.select(‘.news-list-title‘)) > 0:
d = news.select(‘.news-list-info‘)[0].contents[0].text
t = news.select(‘.news-list-title‘)[0].text
a = news.select(‘a‘)[0].attrs[‘href‘]
# print("date = "+d, "text = "+t, "href = "+a)
resd = requests.get(a)
resd.encoding = ‘utf-8‘
soupd = BeautifulSoup(resd.text, ‘html.parser‘)
c = soupd.select(‘#content‘)[0].text
info = soupd.select(".show-info")
# print(info)
# print(info[0].text)
#
# info_text = ‘发布时间:2018-04-01 11:57:00 作者:陈流芳??审核:权麟春 来源:马克思主义学院 点击:次‘
dt = info[0].text.lstrip(‘发布时间:‘)[:19]
sh = info[0].text[info[0].text.find(‘审核:‘):].split()[0].lstrip(‘审核:‘)
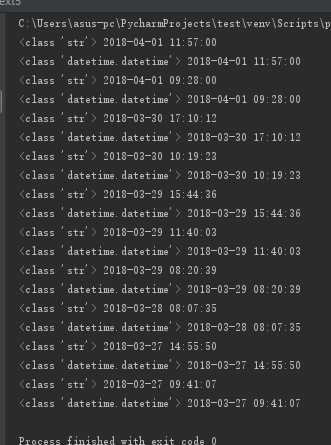
print(type(dt), dt)
from datetime import datetime
date_format = datetime.strptime(dt, ‘%Y-%m-%d %H:%M:%S‘)
print(type(date_format), date_format)