标签:OpenCV 计算机视觉 残差网络 人脸检测 DNN模块
OpenCV基于残差网络实现人脸检测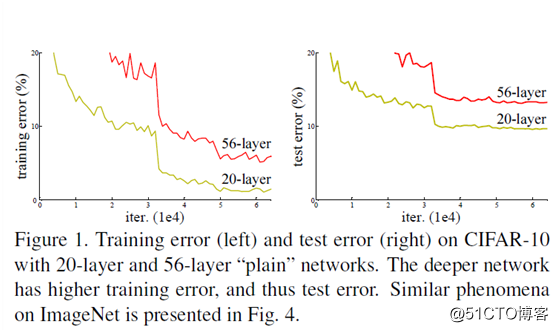
最开始人们以为是因为梯度消失或者梯度爆炸导致的,不过随着大家的努力,认为这个不是一个过拟合问题,而是网络褪化现象,所以针对这种情况,MSRA何凯明团队提出了一种新的网络模型-Residual Networks,其主要思想是使用残差结构来训练网络,一个残差结构如下: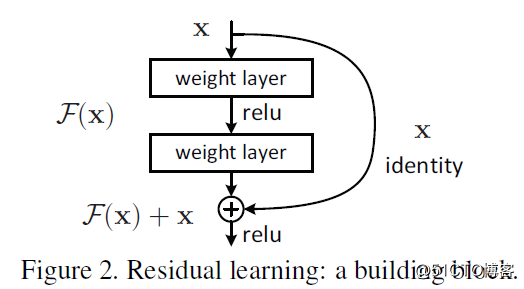
作者认为F(x) = H(x)-x所以得到H(x) = F(x) + x这样的恒等映射,然后作者就建立34层plain网络与34层的残差网络作为对比,而最左边的VGG-19网络作为参考,整个的网络结构显示如下:
--- 图太大啦!!!
模型建立好的之后,作者在不同的数据集上进行了训练与测试,均观察到残差网络的效果要明显优于34层plain网络,而且发现基于残差结构的网络层数越深效果越好,而34层plain网络跟18层的plain网络相比有明显的褪化现象出现。对比训练的结果如下: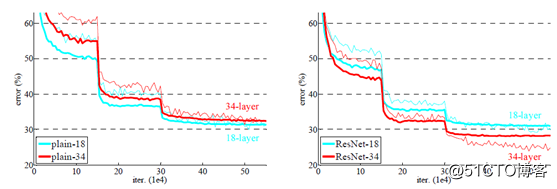
在残差网络没有出来之前,很少有网络的层数会超过100层,但是残差网络可以达到上千层,毫无疑问何凯明团队也凭借残差网络模型在2015年的ImageNet图像分类比赛中获得了冠军,当时使用152层的残差网络。OpenCV中人脸检测的残差网络模型是基于SSD实现的,所以速度还是挺快的,而且效果是特别的好。废话不多说了,下面我就看看OpenCV中如何使用它实现人脸检测。
二:人脸检测代码实现
模型是基于Caffe网络训练生成的,所以在开始写程序之前的第一件事情就是要下载模型文件与描述文件,这个我已经下载好了,大家就不用×××了,直接去我的github地址上下载模型文件即可
https://github.com/gloomyfish1998/opencv_tutorial
下载好模型之后放在本地的一个文件夹下即可,然后就可以开始编程工作啦。
首先需要加载模型成网络:
String modelDesc = "D:/vcprojects/images/dnn/face/deploy.prototxt";
String modelBinary = "D:/vcprojects/images/dnn/face/res10_300x300_ssd_iter_140000.caffemodel";
// 初始化网络
dnn::Net net = readNetFromCaffe(modelDesc, modelBinary);
if (net.empty())
{
printf("could not load net...\n");
return -1;
}然后要打开本地相机或者一段视频文件,使用VideoCapture对象即可,代码如下:
// 打开摄像头
VideoCapture capture(0);
if (!capture.isOpened()) {
printf("could not load camera...\n");
return -1;
}打开相机成功之后就可以读写每帧图像,然后转换成网络可以接受的数据类型,代码如下:
// 输入数据调整
Mat inputBlob = blobFromImage(frame, inScaleFactor,
Size(inWidth, inHeight), meanVal, false, false);
net.setInput(inputBlob, "data");然后在OpenCV中通过调用net.forward实现检测,对结果提取置信分数(0~1)之间,对大于阈值(假设0.5)的提取BOX位置,就可以绘制矩形框显示了,这部分的代码如下:
// 人脸检测
Mat detection = net.forward("detection_out");
vector<double> layersTimings;
double freq = getTickFrequency() / 1000;
double time = net.getPerfProfile(layersTimings) / freq;
Mat detectionMat(detection.size[2], detection.size[3], CV_32F, detection.ptr<float>());
ostringstream ss;
ss << "FPS: " << 1000 / time << " ; time: " << time << " ms";
putText(frame, ss.str(), Point(20, 20), 0, 0.5, Scalar(0, 0, 255));
for (int i = 0; i < detectionMat.rows; i++)
{
float confidence = detectionMat.at<float>(i, 2);
if (confidence > confidenceThreshold)
{
int xLeftBottom = static_cast<int>(detectionMat.at<float>(i, 3) * frame.cols);
int yLeftBottom = static_cast<int>(detectionMat.at<float>(i, 4) * frame.rows);
int xRightTop = static_cast<int>(detectionMat.at<float>(i, 5) * frame.cols);
int yRightTop = static_cast<int>(detectionMat.at<float>(i, 6) * frame.rows);
Rect object((int)xLeftBottom, (int)yLeftBottom,
(int)(xRightTop - xLeftBottom),
(int)(yRightTop - yLeftBottom));
rectangle(frame, object, Scalar(0, 255, 0));
ss.str("");
ss << confidence;
String conf(ss.str());
String label = "Face: " + conf;
int baseLine = 0;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
rectangle(frame, Rect(Point(xLeftBottom, yLeftBottom - labelSize.height),
Size(labelSize.width, labelSize.height + baseLine)),
Scalar(255, 255, 255), CV_FILLED);
putText(frame, label, Point(xLeftBottom, yLeftBottom),
FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 0));
}
}最终运行显示结果如下, 脸部无遮挡,正常情况下: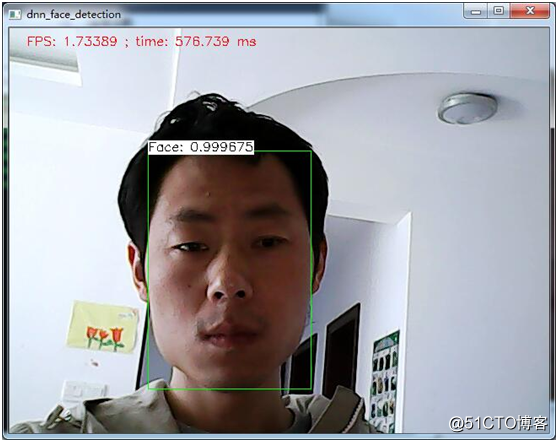
脸部无遮挡,头部倾斜的情况下: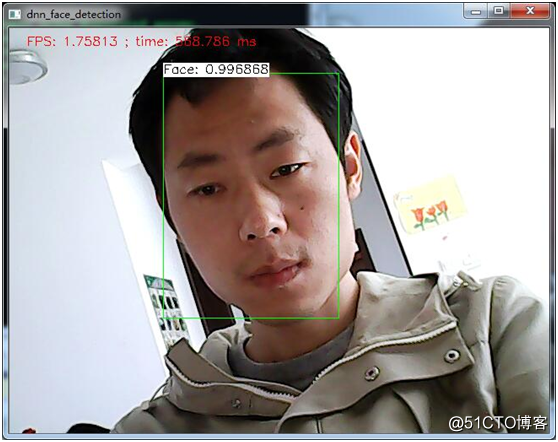
脸部有遮挡的情况下: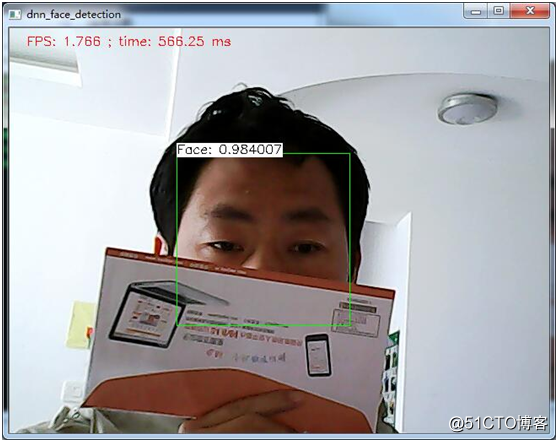
更多倾斜、侧脸、模糊等各种情况下: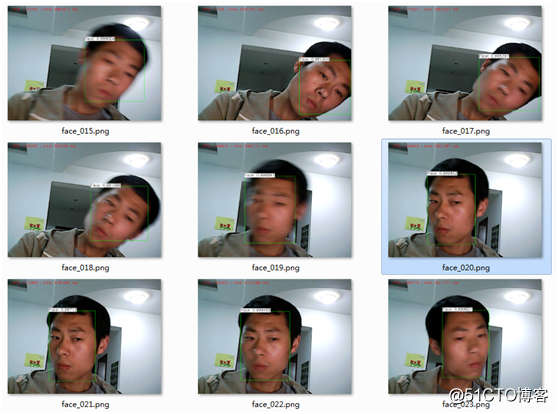
可见残差网络模型是何等的强大,到这里是不是该点一首《凉凉》送给HAAR级联检测器了。上述demo完整源代码,可以在GITHUB上下载。
https://github.com/gloomyfish1998/opencv_tutorial
标签:OpenCV 计算机视觉 残差网络 人脸检测 DNN模块
原文地址:http://blog.51cto.com/gloomyfish/2094611