上一章讨论了paxos算法,把paxos推到一个很高的位置。但是,paxos有没有什么问题呢?实际上,paxos还是有其自身的缺点的:
1. 活锁问题。在base-paxos算法中,不存在leader这样的角色,于是存在这样一种情况,即P1提交了一个proposal n1并且通过了prepare阶段;此时P2提交了一个proposal n2(n2>n1)并且也通过了prepare阶段;P1在commit时因为已经通过了n2而被拒绝;于是P1继续提交一个proposal n3并且通过prepare阶段;巧的是此时P2开始commit了,由于n2<n3再次被拒绝……如此循环往复。这种情况被称为活锁。即整个系统都没死,但由于互相请求资源而被互相锁死。为了不发生活锁的情况,最简单的方式当然是缩减proposer到一个,这样就不会发生互相请求锁死的情况,也即退化。事实上很多后来的工业级协议,都是paxos协议的退化或者变种。
2. 复杂度问题。base-paxos协议中还存在这样那样的问题,于是各种变种paxos出现了,比如为了解决活锁问题,出现了multi-paxos;为了解决通信次数较多的问题,出现了fast-paxos;为了尽量减少冲突,出现了epaxos。可以看到,工业级实现需要考虑更多的方面,诸如性能,异常等等。这也是为啥许多分布式的一致性框架并非真正基于paxos来实现的原因。
3. 全序问题。对于paxos算法来说,不能保证两次提交最终的顺序,而zookeeper需要做到这点,可以参考文献1。
For high-performance, it is important that ZooKeeper can handle multiple outstanding state changes requested by the client and that a prefix of operations submitted concurrently are committed according to FIFO order.
基于以上这些原因,zookeeper并没有用paxos作为自己实现的协议,取而代之采用了一种称为zab的协议,全称是zookeeper atomic broadcast。下面简单介绍一下zab协议。
上面说过了,paxos存在活锁问题,为了解决活锁问题,zab引入了leader,但是单leader就是赤裸裸的单点问题,如何解决这个单点呢?
paxos采用的方法是leader选举(没有采用主备,因为主备过于固定,不够分布式)。leader选举就必然出现状态不一致的情况,于是就有着同步这样的过程。
zab协议分为4个阶段,即阶段0为leader选举,阶段1为发现,阶段2为同步,阶段3为广播。而实际实现时将发现及同步阶段合并为一个恢复阶段。
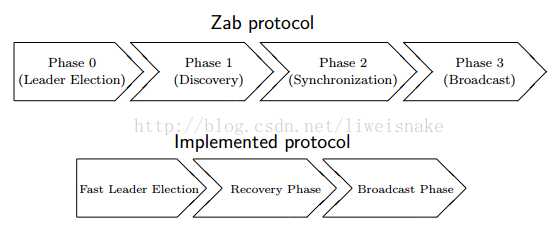
0. leader选举阶段。当集群中没有leader或者其他人感受不到leader时会进入这一阶段,这一阶段的主要目的是选出zxid最大的节点作为准leader。
1. recovery阶段。本阶段的主要目的是根据准leader的情况将数据同步到其他节点。同步完成后准leader变为leader。
2. broadcast阶段。本阶段的主要目的是leader收到请求,并将请求转为proposal,其他节点根据协议进行批准或通过。broadcast阶段事实上就是一个两阶段提交的简化版。其所有过程都跟两阶段提交一致,唯一不一致的是不能做事务的回滚。
广播的过程实际上类似于二阶段提交,但是如果实现完整的两阶段提交,那就解决了一致性问题,没必要发明新协议了,所以zab实际上抛弃了两阶段提交的事务回滚,于是一台follower只能回复ACK或者干脆就不回复了,leader只要收到过半的机器回复即通过proposal。但是这样的设计就存在很多问题,比如如果一个follower因为网络问题从头到尾一直没收到过leader的proposal,后续的询问刚好落到这台follower上该如何处理?比如leader第一阶段收到了所有follower的ACK后提交,然后通知其他follower提交,这时自己挂了该如何处理?于是诞生了崩溃恢复阶段,旨在对各种不一致情况做出恢复和处理。
对于选举和恢复阶段。zab算法需要确保两件事。
1. 已经处理过的proposal不能被丢弃。
发生场景:leader发送了proposal,follower1和follower2回复了ACK给leader,leader向所有follower发送commit请求并commit自身,此时leader挂了。leader已经提交,但是follower尚未提交,这会存在不一致的情况。
确保方式:
a. 重新选举leader时只挑选zxid最大的follower。因为至少半数的follower曾今回复ACK,意味着重新选举时zxid最大的follower应该是当初回复ACK但尚未提交的其中一台。
b. 该follower即准leader,将自身收到prepare但尚未提交的proposal提交
c. 在选举阶段准leader已经能拿到其余follower的所有事务集合,于是准leader根据各个follower的事务执行情况,分别建立队列,先发送prepare请求,再发送commit请求,让所有follower都同步到与leader一样的状态。
通过以上方式,能够确保提交过的proposal不会出现丢弃的情况。
2. 已经丢弃的proposal不能被重复处理。
发生场景:leader收到请求,包装为proposal,此时网络挂了或者leader挂了导致其他follower没收到请求,此时进入崩溃恢复阶段,此时其他follower选主并成功之后这个挂了 的leader以follower的身份加入,此时它有一个多余的proposal,与其他节点不一致。
确保方式:
通过zxid的大小能够直接确定。zxid的编码方式为高32位为epoch(即纪元,可以理解为代),低32位为每个proposal顺序递增的数字。每次变换一个leader,则epoch加一,可以理解为改朝换代了,这样,新朝代的zxid必然比旧朝代的zxid大,新代的leader可以要求将旧朝代的proposal清除。
可以考虑一下,如果leader在崩溃恢复阶段就满血复活了,此时集群的情况是什么样的。
参考文献:
- ZooKeeper’s atomic broadcast protocol:Theory and practice http://www.tcs.hut.fi/Studies/T-79.5001/reports/2012-deSouzaMedeiros.pdf
- Zab:Zookeeper 中的分布式一致性协议介绍 http://www.jianshu.com/p/fb527a64deee
- Zookeeper ZAB 协议分析 http://blog.xiaohansong.com/2016/08/25/zab/
- Zab协议 http://www.cnblogs.com/sunddenly/articles/4073157.html
- ZAB协议和Paxos算法 http://codingo.xyz/index.PHP/2016/12/27/zab_paxos/
- ZooKeeper之ZAB协议 http://www.solinx.co/archives/435
- Zab vs. Paxos https://cwiki.apache.org/confluence/display/ZooKeeper/Zab+vs.+Paxos
- ZooKeeper学习第七期–ZooKeeper一致性原理 http://www.cnblogs.com/sunddenly/p/4138580.html
- 分布式系统理论进阶 – Raft、Zab http://www.cnblogs.com/bangerlee/p/5991417.html