为一个信息流产品作数据抓取,其中数据清洗时必不可少的。其中有一个步骤就是清洗掉其中与内容无关的广告。文本通过语料库积累和NLP相关技术进行过滤,有些文字广告不过滤对产品影响也不大。有点儿麻烦的是其中的有些图片广告如果不过滤掉,在感官上会对产品造成很大的印象,为了解决这个问题,用了一些杂七杂八的方法,始终没有一个唯一的解决方案。最终采用多级判断进行组合check(漏斗式缩小范围),在这里简单记录一下。
主要处理步骤如下图:
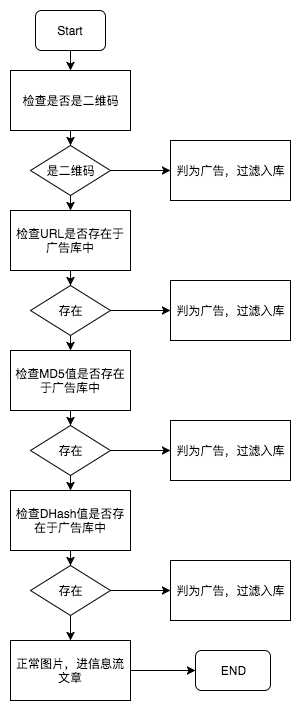
第一步:检查是否为二维码
文章开始和末尾的二维码一般都是广告(可以说至今没有发现不是的),由于二维码是编码良好的图片,可以不依赖材料库就可以判断,所以第一步先判断图片是否为二维码。
二维码判断Demo代码如下:
# coding:utf-8
import sys
from PIL import Image
import zbarlight
def is_qr_code(img):
try:
scan_result = zbarlight.scan_codes("qrcode", img)
except Exception:
return False
else:
# 打印QRCODE信息
return True if scan_result else False
if __name__ == "__main__":
img_name = sys.argv[1]
ig = Image.open(img_name)
print is_qr_code(ig)若怕二维码中有重要信息,可以将从二维码图片中识别的文本信息做进一步的NLP处理,从而决定是否判定为广告
第二步:检查来源URL
有些广告图片都来同一个URL,比如某些自媒体/资讯平台会在每篇文章下面带有相同的广告图片,有的不是同一家产品的,但是采用了同一个广告平台都会出现这种情况。具体实现就是文本比对,代码就不用说了。
第三步:检查图片Hash-MD5(绝对指纹)
某些广告图片完全相同,但却来自不同的URL(比如,某些网站静态资源URI变更),用第二步的URL比对就不行了。在本步骤中采用图片内容的完全比对进行广告图片识别。若采用像素点比对那效率就太低了,所以采用MD5哈希值比对。MD5一般用于校验文件是否损坏、被修改,在这一步正好合适。
获取图片MD5哈希值的简单Demo代码:
Demo代码:
# coding:utf-8
import sys
from hashlib import md5
if __name__ == "__main__":
img_name = sys.argv[1]
img_body = open(img_name).read()
fingerprint = md5(img_body).hexdigest()
print fingerprint第四步:检测图片感知哈希
参考:https://realpython.com/blog/python/fingerprinting-images-for-near-duplicate-detection/
在第三步中采用的MD5哈希比对对于内容完全相同的广告图片是适用的,但是一旦两张图片稍有差异,MD5就完全不同了,也就造成第三步的检测失效。所以在这里采用感知哈希进行相似图片的匹配(和广告图片相似的也是广告图片)。感知哈希是一类哈希算法。这里实验两种
DHash——均值感知哈希,
pHash——余弦变换感知哈希
均值哈希Demo代码:
# coding:utf-8
import sys
from PIL import Image
def dhash(image, hash_size=8):
image = image.convert('L').resize(
(hash_size + 1, hash_size),
Image.ANTIALIAS,
)
difference = []
for row in xrange(hash_size):
for col in xrange(hash_size):
pixel_left = image.getpixel((col, row))
pixel_right = image.getpixel((col + 1, row))
difference.append(pixel_left > pixel_right)
decimal_value = 0
hex_string = []
for index, value in enumerate(difference):
if value:
decimal_value += 2 ** (index % 8)
if (index % 8) == 7:
hex_string.append(hex(decimal_value)[2:].rjust(2, '0'))
decimal_value = 0
return ''.join(hex_string)
if __name__ == "__main__":
img_name = sys.argv[1]
img = Image.open(img_name)
print dhash(img)第五步:人为定义特征
还可以通过其他人为定义特征进行过滤,以下特征可以考虑:
- 色彩分布
- 整体轮廓
- ......
结束
本文只介绍了整个流程的实现demo。当然,在真正的业务项目中还牵涉到其他的组件。其中主要的时广告图片url、md5、指纹的存储和比对,就不介绍了,这和其他服务中的数据库的检索没什么区别,就是根据实际数据量进行设计&调整持久化、索引、缓存、备份、排序等相关策略。
后记:很早之前写的,写的不好,一直躺在草稿箱。现在发布出来,虽然已经不在进行这项工作了,还是希望有朋友提出改进的建议,谢谢!