Spark的代码是在GitHub上托管的,如果想看源码,可以访问:GitHub。至于SparkStreaming等功能,有个测试案例的包,
sparkStreaming的案例地址:https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/streaming
我们以NetworkWordCount.scala 为例进行测试。注意:我们假设你已经安装并配置好了spark环境,并在服务器上安装了瑞士军刀,即nc。
1、在当前窗口(A窗口)开启一个nc,端口号使用9999
nc -lk 9999
2、重新打开一个窗口(B窗口),通过spark-submit 提交spark作业
spark-submit --master local[*] --class org.apache.spark.examples.streaming.NetworkWordCount --name wordCount /opt/spark/examples/jars/spark-examples_2.11-2.0.1.jar localhost 9999
注:
1)、--master local[*] 是指通过本地方式提交作业,*是尽可能多的使用cpu核数,可以改为数字
2)、--class 为启动类,--name 为作业名字,再后面是jar文件,
3)、localhost 9999 为参数,具体可以参考NetworkWordCount.scala中的代码,是指nc的端口和ip地址
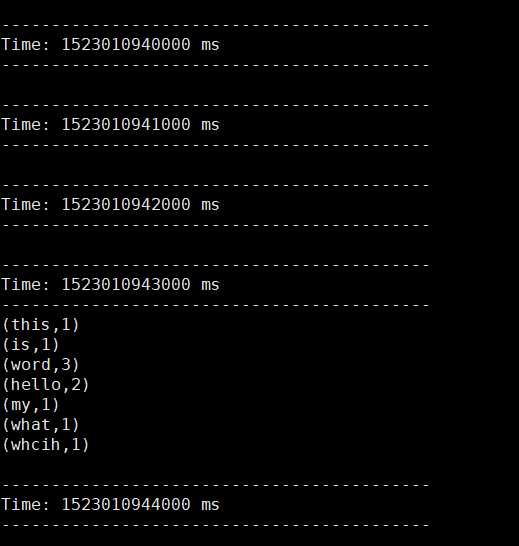
3、在窗口A输入一行文本后,可以看到窗口B会统计单词频率
A窗口输入:

B窗口可以看到