假期闲着无聊,做了一下Kaggle练手的项目--预测泰坦尼克号乘客的存活情况。对于一些函数和算法,刚开始也是懵懵懂懂的,但通过自己查资料,还是明白了许多,我会把参考资料的网址放在需要查看的地方。
------------------------------------
我们的整个流程如下:
①数据预处理:数据清洗、可视化、标签化
②分割训练数据
③随机森林分类器及其参数调节
数据预处理:数据清洗、可视化、标签化
首先,先导入需要的模块并读取数据
#导入包,读取数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
data_train = pd.read_csv(r‘C:\Users\Administrator\Desktop\456\train.csv‘)
data_test = pd.read_csv(r‘C:\Users\Administrator\Desktop\456\test.csv‘)
导入成功后,我们来看看训练数集↓
↑发现有如下特征:乘客ID,存活情况,船票级别,乘客姓名,性别,年龄,船上的兄弟姐妹以及配偶的人数,船上的父母以及子女的人数,船票编号,工资,所在船舱,登船的港口
来开始进行可视化
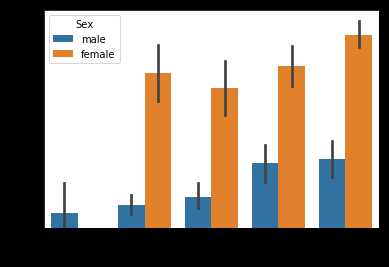
#我们要通过绘图来观察训练数集的基本情况哦,我们先从登舱口Embarked开始,来绘制二维柱状图,不同性别在不同登舱口的生存情况
sns.barplot(x=‘Embarked‘,y=‘Survived‘,hue=‘Sex‘,data=data_train)
#可以发现,在登船的C港口,无论是男女,生存概率都比S、Q多,但相差不会太多。总体上女性生存的几率比男性高很多
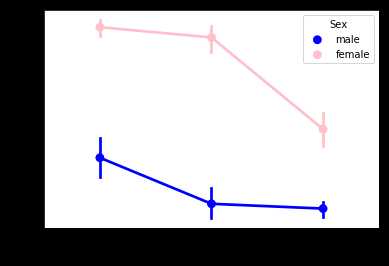
#接着,我们用折线图从Pclass,也就是几等舱来观测下生存概率
sns.pointplot(x=‘Pclass‘,y=‘Survived‘,hue=‘Sex‘,data=data_train,palette={‘male‘:‘blue‘,‘female‘:‘pink‘},
marker=[‘*‘,"o"],linestyle=[‘-‘,‘--‘])
#总的来说,可以发现,随着舱位越来越低,存活率越来越低,这就是有钱的好处吧
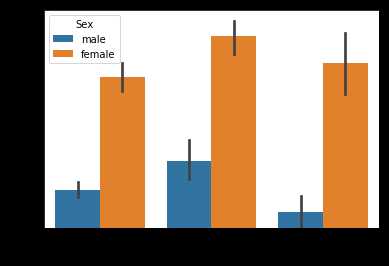
除了Embarked,Pclass,我还想对年龄、Cabin的首字母(与乘客所在舱口有关)、工资这三种情况与生存情况画图分析
但现在的情况是:
①年龄是连续变量,但我们可以按照我们日常生活的逻辑对年龄划区间,对年龄进行分组,再画图根据组来对乘客的Survived状况进行分析
②Cabin是一个字母+一串数字,但我们可以它们切割了,只留字母,再画图根据不同字母对乘客的Survived状况进行分析
③工资也是连续变量,同样需要分组,但我们在日常生活中,对高工资低工资什么的概念也有点模糊,不如我们把他们四分化,分为(最小值到下四分位数),(下四分位数到中位数),(中位数到上四分位数),(上四分位数到最大值)
④我觉得乘客的名字Name、船票编码Ticket、Embarked对乘客的Survived情况没起到显著的作用,所以我打算删掉哦!
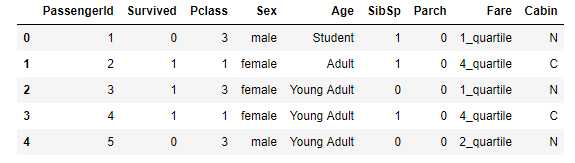
因此,我们要完成以上的任务哦。也就是说,我们要把原来的data_train转化成我们需要的、可以方便我们进行数据分析的表格↓
①简化年龄,就是分组
def simplify_ages(df):
#把缺失值补上,方便分组
df.Age = df.Age.fillna(-0.5)
#把Age分为不同区间,-1到0,1-5,6-12...,60以上,放到bins里,八个区间,对应的八个区间名称在group_names那
bins = (-1, 0, 5, 12, 18, 25, 35, 60, 120)
group_names = [‘Unknown‘, ‘Baby‘, ‘Child‘, ‘Teenager‘, ‘Student‘, ‘Young Adult‘, ‘Adult‘, ‘Senior‘]
#开始对数据进行离散化,pandas.cut就是这个功能
catagories = pd.cut(df.Age,bins,labels=group_names)
df.Age = catagories
return df
②简化Cabin,就是取字母
def simplify_cabin(df):
df.Cabin = df.Cabin.fillna(‘N‘)
df.Cabin = df.Cabin.apply(lambda x:x[0])
return df
③简化工资,也就是分组
def simplify_fare(df):
df.Fare = df.Fare.fillna(-0.5)
bins = (-1, 0, 8, 15, 31, 1000)
group_names = [‘Unknown‘, ‘1_quartile‘, ‘2_quartile‘, ‘3_quartile‘, ‘4_quartile‘]
catagories = pd.cut(df.Fare,bins,labels=group_names)
df.Fare = catagories
return df
④删除无用信息
def simplify_drop(df):
return df.drop([‘Name‘,‘Ticket‘,‘Embarked‘],axis=1)
⑤整合一遍,凑成新表
def transform_features(df):
df = simplify_ages(df)
df = simplify_cabin(df)
df = simplify_fare(df)
df = simplify_drop(df)
return df
⑥执行读取新表
#必须要再读取一遍原来的表,不然会报错,不仅训练集要简化,测试集也要,两者的特征名称要一致
data_train = pd.read_csv(r‘C:\Users\Administrator\Desktop\456\train.csv‘)
data_train = transform_features(data_train)
data_test = transform_features(data_test)
data_train.head()
以上任务执行完毕,继续画图!
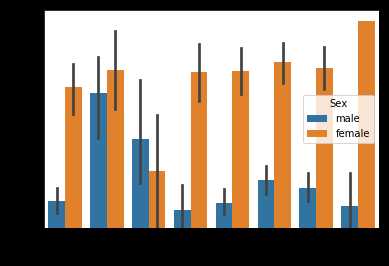
#好啦,我们根据新的表格来画图啦,先来话Age-Survived的图哦,以Sex分组
sns.barplot(x = ‘Age‘,y = ‘Survived‘,hue=‘Sex‘,data = data_train)
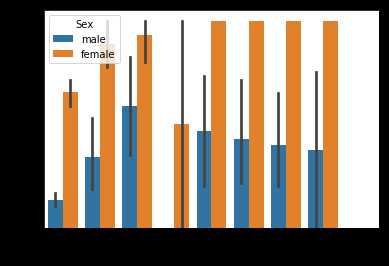
#再按Cabin-Survived画
sns.barplot(x = ‘Cabin‘,y = ‘Survived‘,hue=‘Sex‘,data = data_train)
#根据舱位,其实也可以看出一些端倪哦
#到Fare啦
sns.barplot(x = ‘Fare‘,y = ‘Survived‘,hue=‘Sex‘,data = data_train)
#果然工资越高的,存活率更高啊,不过女性都很高