数据库部分
一、查询优化
二、持久化数据库连接
django1.6以后已经内置了数据库持久化连接,很多人使用PostgreSQL作为它们的线上数据库系统,而当我们连接PostgreSQL有时会显得很慢,这里我们可以进行优化。
没有持久化连接,每一个网站的请求都会与数据库建立一个连接。如果数据库不在本地,尽管网速很快,这也将花费20-75ms.
设置持久化连接,仅需要添加CONN_MAX_AGE参数到你的数据库设置中:


DATABASES = { ‘default’: { ‘ENGINE’: ‘django.db.backends.postgresql_psycopg2’, ‘NAME’: ‘whoohoodb’, ‘CONN_MAX_AGE’: 600, } }
通过这样的设置,我们设置的持久化连接每次都将存活10分钟
这有助于减少内存泄漏或导致一种片状连接的问题。
你可设置更长的时间,但是我不要设置超过1个小时,因为这样获得的效果不会太好。你可以从django的帮助文档中获取详细信息 django持久化连接
三、select_related() 和 prefetch_related()
相比于修改数据库存储,这里只要需要简单的设置select_related()和prefetch_related(),在使用ORM的情况下,他能够减少sql查询的数量。
这里有一个BlogPost模型,它有一个用户外键,获得了一个listview
queryset = BlogPost.objects.active
那么在模版中是这样使用:
<ul>
{% for post in object_list %}
<li>{{ post.title }} - {{ post.user.email }}</li>
{% endfor %}
</ul>
这里满足了预期的效果,但是每个post都会去查询auth_user表。为了解决这个问题,可以让djangode的ORM在前面就连接上auth_user 表,这样object.user就是一个可以直接用的对象了,这样BlogPost.objects.active().count()就会变成一个简单的查询
修改如下:
queryset = BlogPost.objects.select_related().active()
prefetch_related的机理是相同的
当感到疑惑时,开启django调试工具,然后分析每次请求的查询次数和时间,如果每次查询都要用上5~10次,那么这些就是可以优化的线索
四、利用标准数据库优化技术
传统数据库优化技术博大精深,不同的数据库有不同的优化技巧,但重心还是有规则的。在这里算是题外话,挑两点通用的说说:
索引,给关键的字段添加索引,性能能更上一层楼,如给表的关联字段,搜索频率高的字段加上索引等。Django建立实体的时候,支持给字段添加索引,具体参考Django.db.models.Field.db_index。按照经验,Django建立实体之前应该早想好表的结构,尽量想到后面的扩展性,避免后面的表的结构变得面目全非。
使用适当字段类型,本来varchar就搞定的字段,就别要text类型,小细节别不关紧要,后头数据量一上去,愈来愈多的数据,小字段很可能是大问题。
五、了解Django的QuerySets
了解Django的QuerySets对象,对优化简单程序有至关重要的作用。QuerySets是有缓存的,一旦取出来,它就会在内存里呆上一段时间,尽量重用它。
# 了解缓存属性: >>> entry = Entry.objects.get(id=1) >>> entry.blog # 博客实体第一次取出,是要访问数据库的 >>> entry.blog # 第二次再用,那它就是缓存里的实体了,不再访问数据库
>>> entry = Entry.objects.get(id=1) >>> entry.authors.all() # 第一次all函数会查询数据库 >>> entry.authors.all() # 第二次all函数还会查询数据库
- all,count exists是调用函数(需要连接数据库处理结果的),注意在模板template里的代码,模板里不允许括号,但如果使用此类的调用函数,一样去连接数据库的,能用缓存的数据就别连接到数据库去处理结果。还要注意的是,自定义的实体属性,如果调用函数的,记得自己加上缓存策略。
- 利用好模板的with标签:
模板中多次使用的变量,要用with标签,把它看成变量的缓存行为吧。
- 使用QuerySets的iterator():
通常QuerySets先调用iterator再缓存起来,当获取大量的实体列表而仅使用一次时,缓存行为会耗费宝贵的内存,这时iterator()能帮到你,iterator()只调用iterator而省 去了缓存步骤,显著减少内存占用率,具体参考相关文档。
六、数据库的工作就交给数据库本身计算,别用Python处理
- 使用 filter and exclude 过滤不需要的记录,这两个是最常用语句,相当是SQL的where
- 同一实体里使用F()表达式过滤其他字段
- 使用annotate对数据库做聚合运算
不要用python语言对以上类型数据过滤筛选,同样的结果,python处理复杂度要高,而且效率不高, 白白浪费内存
- 使用QuerySet.extra() extra虽然扩展性不太好,但功能很强大,如果实体里需要需要增加额外属性,不得已时,通过extra来实现,也是个好办法
- 使用原生的SQL语句 如果发现Django的ORM已经实现不了你的需求,而extra也无济于事的时候,那就用原生SQL语句
七、如果需要就一次性取出你所需要的数据
单一动作(如:同一个页面)需要多次连接数据库时,最好一次性取出所有需要的数据,减少连接数据库次数。
此类需求推荐使用QuerySet.select_related() (主动连表)和 prefetch_related()(被动连表)
相反,别取出你不需要的东西,模版templates里往往只需要实体的某几个字段而不是全部,这时QuerySet.values() 和 values_list(),对你有用,它们只取你需要的字段,返回字典dict和列表list类型的东西,在模版里够用即可,这可减少内存损耗,提高性能
同样QuerySet.defer()和only()对提高性能也有很大的帮助,一个实体里可能有不少的字段,有些字段包含很多元数据,比如博客的正文,很多字符组成,Django获取实体时(取出实体过程中会进行一些python类型转换工作),我们可以延迟大量元数据字段的处理,只处理需要的关键字段,这时QuerySet.defer()就派上用场了,在函数里传入需要延时处理的字段即可;而only()和defer()是相反功能
使用QuerySet.count()代替len(queryset),虽然这两个处理得出的结果是一样的,但前者性能优秀很多。同理判断记录存在时,QuerySet.exists()比if queryset实在强得太多了
八、懂减少数据库的连接数
使用 QuerySet.update() 和 delete(),这两个函数是能批处理多条记录的,适当使用它们事半功倍;如果可以,别一条条数据去update delete处理。
对于一次性取出来的关联记录,获取外键的时候,直接取关联表的属性,而不是取关联属性,如:
entry.blog.id
优于
entry.blog__id
# 善于使用批量插入记录,如:
Entry.objects.bulk_create([
Entry(headline="Python 3.0 Released"),
Entry(headline="Python 3.1 Planned")
])
优于
Entry.objects.create(headline="Python 3.0 Released")
Entry.objects.create(headline="Python 3.1 Planned")
# 前者只连接一次数据库,而后者连接两次
# 还有相似的动作需要注意的,如:多对多的关系,
my_band.members.add(me, my_friend)
优于
my_band.members.add(me)
my_band.members.add(my_friend)
六、读写分离
1.增加主从数据库
DATABASES = { ‘default‘: { ‘ENGINE‘: ‘django.db.backends.mysql‘, ‘NAME‘: ‘dailyfresh‘, ‘HOST‘: ‘192.168.243.193‘, # MySQL数据库地址(主) ‘PORT‘: ‘3306‘, ‘USER‘: ‘root‘, ‘PASSWORD‘: ‘mysql‘, }, ‘slave‘: { ‘ENGINE‘: ‘django.db.backends.mysql‘, ‘NAME‘: ‘dailyfresh‘, ‘HOST‘: ‘192.168.243.189‘, # MySQL数据库地址(从) ‘PORT‘: ‘3306‘, ‘USER‘: ‘root‘, ‘PASSWORD‘: ‘mysql‘, } }
2.编辑路由分发的类 :db_router.py
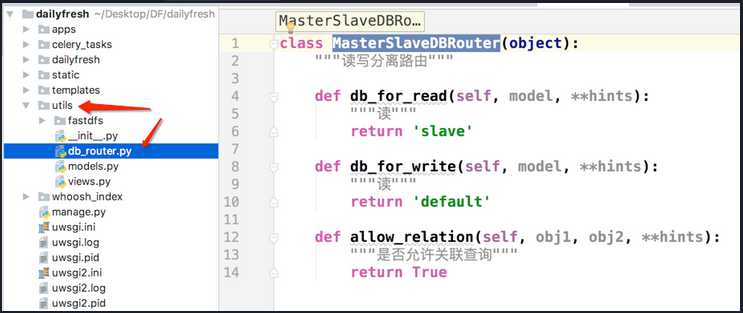
class MasterSlaveDBRouter(object): """读写分离路由""" def db_for_read(self, model, **hints): """读""" return ‘slave‘ def db_for_write(self, model, **hints): """读""" return ‘default‘ def allow_relation(self, obj1, obj2, **hints): """是否允许关联查询""" return True
3.读写分离引导settings.py
# 配置读写分离 DATABASE_ROUTERS = [‘utils.db_router.MasterSlaveDBRouter‘]
三、redis集群
页面渲染部分
一、模板加载
默认django使用两个标准的模版加载器
TEMPLATE_LOADERS = (
‘django.template.loaders.filesystem.Loader’,
‘django.template.loaders.app_directories.Loader’,
)
每一个请求,这些模版加载器都会去文件系统搜索,然后解析这些模版。
这里可以感觉到,它是不是可以处理的更快了?
你可以开启缓存加载,因此django只会查找并且解析你的模版一次
配置如下:
TEMPLATE_LOADERS = (
(‘django.template.loaders.cached.Loader’, (
‘django.template.loaders.filesystem.Loader’,
‘django.template.loaders.app_directories.Loader’,
)),
)
但是,不要在开发环境中开启缓存加载,这样会很烦人的,因为每次模版做了修改之后你都需要重启服务才能看到修改后的效果
缓存部分