grep文本过滤
1.grep 默认是按照以行为基本单位进行匹配和显示的。
2.grep默认匹配只要包含模式字符即可
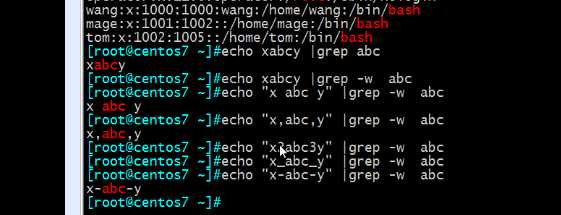
grep -w 是按单词匹配,和普通的匹配不一致
单词的分隔符, 数字加字母加下划线都算做单词的一部分
grep -f p.txt /etc/passwd
正则表达式
1.字符匹配
. 表示一个任意字符 .放在[]里面就表示.本身这个字符
2.匹配次数
某一个字符出现的次数
* 表示*号前面的字符出现的次数是不确定的
3.位置锚定
行首 ^ 不能匹配中间某段字符串的开始
行尾 $ 不能匹配中间某一段字符串的结尾
单词词首 \<root root处于单词的最左侧
单词词尾 root\> root处于单词的最右侧
4.分组
1. echo wangwangwangggww | grep "\(wang\)\{3\}"
2.后向引用
正则表达式和通配符的区别
正则表达式匹配的是文件的内容或者标准输出的字符串,通配符匹配的是文件的名称.两者操作的对象不一致.

匹配字符串问题
shell执行命令的时候,正则表达式是以整个输出作为字符串内容,包括看不到的空格符号。
有些命令结果会输出一个或者多个空格,有些命令不会输出空格.



1.在表达式中()符号前面和{}括号前面都必须要加上\(\) 和 \{\}.
grep "^\(.*\):.*\1$" /etc/passwd
2.正则表达式默认从字符串的最前面开始查找,但是如果锚定的是行尾,那么正则会从尾部开始查找
1.从尾部开始查找
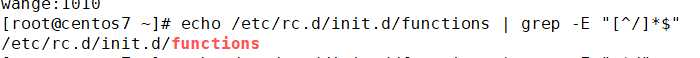
2.从头部开始查找
