标签:Lucene style blog http color io os 使用 java
.dvm是存放了DocValue域的元数据,比如DocValue偏移量。
.dvd则存放了DocValue的数据。
在Solr4.8.0中,dvd以及dvm用到的Lucene编码格式是Lucene45DocValuesFormat。跟之前的文件格式类似,它分别包含Lucene45DocValuesProducer
和Lucene45DocValuesConsumer来实现该文件的读和写。
1 @Override 2 public DocValuesConsumer fieldsConsumer(SegmentWriteState state) throws IOException { 3 return new Lucene45DocValuesConsumer(state, DATA_CODEC, DATA_EXTENSION, META_CODEC, META_EXTENSION); 4 } 5 6 @Override 7 public DocValuesProducer fieldsProducer(SegmentReadState state) throws IOException { 8 return new Lucene45DocValuesProducer(state, DATA_CODEC, DATA_EXTENSION, META_CODEC, META_EXTENSION); 9 }
Lucene 4.5 DocValues format通过下面的策略对四种类型进行编码:
BINARY
首先来介绍下.dvm的文件格式:
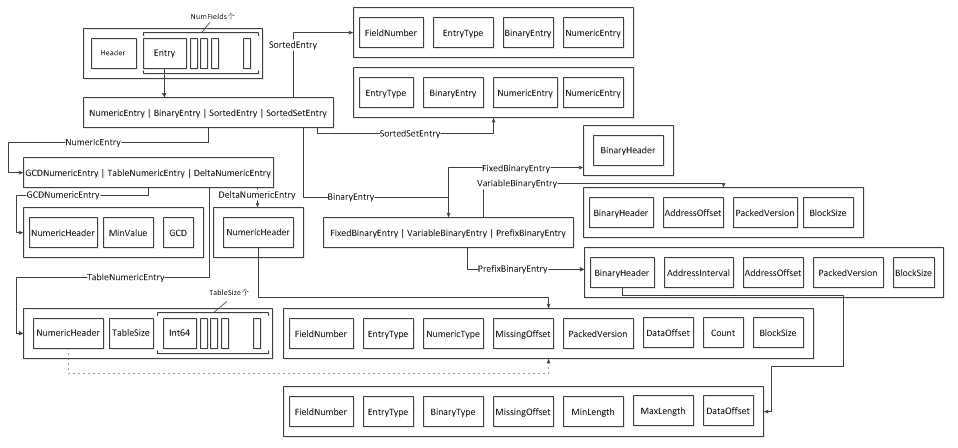
. dvm的文件结构分为好多层:
SortedEntry: 包含FieldNumber,EntryType,BinaryEntry,NumericEntry
SortedSetEntry: 包含EntryType,BinaryEntry,NumericEntry,NumericEntry
.dvd文件格式:
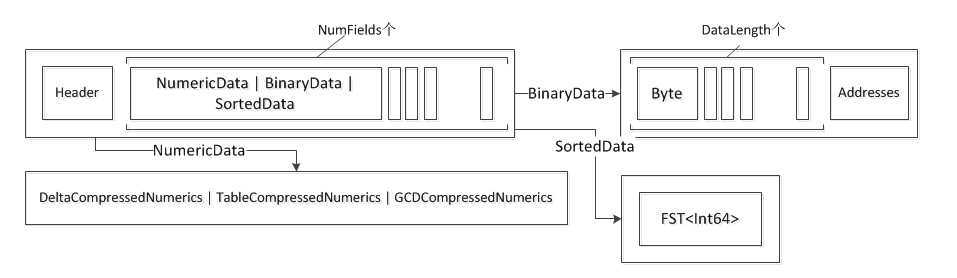
同样.dvd 文件具有好几层结构:
第一层:Header,<NumericData | BinaryData | SortedData>NumFields,Footer 与dvm类似,NumFields个Data(SortedData,BinaryData,NumericData其中一个)
前文讲到Lucene45DocValuesFormat分别包含Lucene45DocValuesProducer和Lucene45DocValuesConsumer来实现该文件的读和写,那么本节内容主要以Lucene45DocValuesProducer为例来学习下dvm和dvd。
首先学习下Lucene45DocValuesProducer的初始化:主要作用是读取.dvm文件和.dvd流。其中在读取.dvm文件过程中,Lucene45DocValuesProducer调用了readFields(in, state.fieldInfos)来获取入口信息。
1 protected Lucene45DocValuesProducer(SegmentReadState state, String dataCodec, String dataExtension, String metaCodec, String metaExtension) throws IOException { 2 //.dvm文件名 3 String metaName = IndexFileNames.segmentFileName(state.segmentInfo.name, state.segmentSuffix, metaExtension); 4 // read in the entries from the metadata file. 5 //打开.dvm并获取检验和,获取文件流, 6 ChecksumIndexInput in = state.directory.openChecksumInput(metaName, state.context); 7 //获取segment的document个数 8 this.maxDoc = state.segmentInfo.getDocCount(); 9 boolean success = false; 10 try { 11 //获取.dvm header 12 version = CodecUtil.checkHeader(in, metaCodec, 13 Lucene45DocValuesFormat.VERSION_START, 14 Lucene45DocValuesFormat.VERSION_CURRENT); 15 numerics = new HashMap<>(); 16 ords = new HashMap<>(); 17 ordIndexes = new HashMap<>(); 18 binaries = new HashMap<>(); 19 sortedSets = new HashMap<>(); 20 21 //读取NumFields个<Entry> 22 readFields(in, state.fieldInfos); 23 24 //加入Footer 25 if (version >= Lucene45DocValuesFormat.VERSION_CHECKSUM) { 26 CodecUtil.checkFooter(in); 27 } else { 28 CodecUtil.checkEOF(in); 29 } 30 31 success = true; 32 } finally { 33 if (success) { 34 IOUtils.close(in); 35 } else { 36 IOUtils.closeWhileHandlingException(in); 37 } 38 } 39 40 success = false; 41 try { 42 //.dvd文件名 43 String dataName = IndexFileNames.segmentFileName(state.segmentInfo.name, state.segmentSuffix, dataExtension); 44 //打开.dvd文件 45 data = state.directory.openInput(dataName, state.context); 46 //获取.dvd header 47 final int version2 = CodecUtil.checkHeader(data, dataCodec, 48 Lucene45DocValuesFormat.VERSION_START, 49 Lucene45DocValuesFormat.VERSION_CURRENT); 50 if (version != version2) { 51 throw new CorruptIndexException("Format versions mismatch"); 52 } 53 54 success = true; 55 } finally { 56 if (!success) { 57 IOUtils.closeWhileHandlingException(this.data); 58 } 59 } 60 //估算类的大小,也就是估算.dvd流的大小 61 ramBytesUsed = new AtomicLong(RamUsageEstimator.shallowSizeOfInstance(getClass())); 62 }
readFields(in, state.fieldInfos)主要是读取EntryType,根据它的值来选择哪种方式来读取后续的Entry信息,
函数中涉及了以下几个方式:
1. Numeric类型readNumericEntry()
2.BinaryEntry类型readBinaryEntry()
3.SortedSetEntry类型readSortedField()
4.SortedSetEntry类型readSortedSetEntry(),同时在该类型下,readFields还分别调用了readSortedSetFieldWithAddresses和readSortedField
1 private void readFields(IndexInput meta, FieldInfos infos) throws IOException { 2 //读取Entry的编号,如果编号为-1,表示这是最后一个Entry。 3 int fieldNumber = meta.readVInt(); 4 while (fieldNumber != -1) { 5 // check should be: infos.fieldInfo(fieldNumber) != null, which incorporates negative check 6 // but docvalues updates are currently buggy here (loading extra stuff, etc): LUCENE-5616 7 if (fieldNumber < 0) { 8 // trickier to validate more: because we re-use for norms, because we use multiple entries 9 // for "composite" types like sortedset, etc. 10 throw new CorruptIndexException("Invalid field number: " + fieldNumber + " (resource=" + meta + ")"); 11 } 12 //读取EntryType,以此来区分Entry的类型,0表示NUMERICENTRY,1表示BINARYENTRY,2表示SORTEDENTRY,3表示SORTED_SETENTRY 13 byte type = meta.readByte(); 14 if (type == Lucene45DocValuesFormat.NUMERIC) { 15 //获取具体的NumericEntry内容,并放入以编号为键,NumericEntry为值的map中 16 numerics.put(fieldNumber, readNumericEntry(meta)); 17 } else if (type == Lucene45DocValuesFormat.BINARY) { 18 //获取具体的BinaryEntry内容,并放入以编号为键,BinaryEntry为值的map中 19 BinaryEntry b = readBinaryEntry(meta); 20 binaries.put(fieldNumber, b); 21 } else if (type == Lucene45DocValuesFormat.SORTED) { 22 //读取SortedEntry 23 readSortedField(fieldNumber, meta, infos); 24 } else if (type == Lucene45DocValuesFormat.SORTED_SET) { 25 //读取SortedSetEntry,并放入以编号为键,SortedSetEntry为值的map中 26 SortedSetEntry ss = readSortedSetEntry(meta); 27 sortedSets.put(fieldNumber, ss); 28 //标准的存储有序的集合是否通过address的间接转换,SORTED_SET_WITH_ADDRESSES是docid->address>ord映射 29 if (ss.format == SORTED_SET_WITH_ADDRESSES) { 30 readSortedSetFieldWithAddresses(fieldNumber, meta, infos); 31 //SORTED_SET_SINGLE_VALUED_SORTED 只存储docid->ord的值 32 } else if (ss.format == SORTED_SET_SINGLE_VALUED_SORTED) { 33 if (meta.readVInt() != fieldNumber) { 34 throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 35 } 36 if (meta.readByte() != Lucene45DocValuesFormat.SORTED) { 37 throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 38 } 39 readSortedField(fieldNumber, meta, infos); 40 } else { 41 throw new AssertionError(); 42 } 43 } else { 44 throw new CorruptIndexException("invalid type: " + type + ", resource=" + meta); 45 } 46 //读取下一个Entry 47 fieldNumber = meta.readVInt(); 48 } 49 }
1. readNumericEntry()
1 static NumericEntry readNumericEntry(IndexInput meta) throws IOException { 2 NumericEntry entry = new NumericEntry(); 3 entry.format = meta.readVInt(); //NumericType,Numeric的编码方式 4 entry.missingOffset = meta.readLong(); //MissingOffset表示该field在哪个document中缺失,如果为-1表示没有document缺失字段 5 entry.packedIntsVersion = meta.readVInt(); //PackedVersion 打包整数的version 6 entry.offset = meta.readLong(); //DataOffset 指向.dvd文件中数据起始位置的指针 7 entry.count = meta.readVLong(); //Count 已写的值的个数 8 entry.blockSize = meta.readVInt(); //BlockSize 已打包的整数的大小 9 switch(entry.format) { 10 case GCD_COMPRESSED: //GCD-compressed(最大公约数压缩) 11 entry.minValue = meta.readLong(); //MinValue 12 entry.gcd = meta.readLong(); //GCD 13 break; 14 case TABLE_COMPRESSED: //Table-compressed(表压缩) 15 if (entry.count > Integer.MAX_VALUE) { 16 throw new CorruptIndexException("Cannot use TABLE_COMPRESSED with more than MAX_VALUE values, input=" + meta); 17 } 18 final int uniqueValues = meta.readVInt(); //TableSize 19 if (uniqueValues > 256) { //TableSize必须小于256 20 throw new CorruptIndexException("TABLE_COMPRESSED cannot have more than 256 distinct values, input=" + meta); 21 } 22 entry.table = new long[uniqueValues]; //TableSize个Long 23 for (int i = 0; i < uniqueValues; ++i) { 24 entry.table[i] = meta.readLong(); 25 } 26 break; 27 case DELTA_COMPRESSED: //Delta-compressed(增量压缩) 28 break; 29 default: 30 throw new CorruptIndexException("Unknown format: " + entry.format + ", input=" + meta); 31 } 32 return entry; 33 }
2. BinaryEntry()
1 static BinaryEntry readBinaryEntry(IndexInput meta) throws IOException { 2 BinaryEntry entry = new BinaryEntry(); 3 entry.format = meta.readVInt(); //BinaryType类型 4 entry.missingOffset = meta.readLong(); //缺失表示,同NuericEntry 5 entry.minLength = meta.readVInt(); //存储Binary 类型的值的位数组的长度的最小值和最大值。 6 //如果这两个值是相等的,那么所有的值都是固定的大小, 7 //并且可以通过DataOffset + (docID * length)计算出来。 8 //否则,Binary的值是不定长的 9 entry.maxLength = meta.readVInt(); 10 entry.count = meta.readVLong(); 11 entry.offset = meta.readLong(); //实际二进制数的偏移 12 switch(entry.format) { 13 case BINARY_FIXED_UNCOMPRESSED: //Fixed-width Binary 14 break; 15 case BINARY_PREFIX_COMPRESSED: //Variable-width Binary 16 entry.addressInterval = meta.readVInt(); 17 entry.addressesOffset = meta.readLong(); 18 entry.packedIntsVersion = meta.readVInt(); 19 entry.blockSize = meta.readVInt(); 20 break; 21 case BINARY_VARIABLE_UNCOMPRESSED: //Prefix-compressed Binary 22 entry.addressesOffset = meta.readLong(); 23 entry.packedIntsVersion = meta.readVInt(); 24 entry.blockSize = meta.readVInt(); 25 break; 26 default: 27 throw new CorruptIndexException("Unknown format: " + entry.format + ", input=" + meta); 28 } 29 return entry; 30 }
3. readSortedSetFieldWithAddresses()
1 private void readSortedSetFieldWithAddresses(int fieldNumber, IndexInput meta, FieldInfos infos) throws IOException { 2 // sortedset = binary + numeric (addresses) + ordIndex 3 if (meta.readVInt() != fieldNumber) { 4 throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 5 } 6 if (meta.readByte() != Lucene45DocValuesFormat.BINARY) { 7 throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 8 } 9 BinaryEntry b = readBinaryEntry(meta); 10 binaries.put(fieldNumber, b); 11 12 if (meta.readVInt() != fieldNumber) { 13 throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 14 } 15 if (meta.readByte() != Lucene45DocValuesFormat.NUMERIC) { 16 throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 17 } 18 NumericEntry n1 = readNumericEntry(meta); 19 ords.put(fieldNumber, n1); 20 21 if (meta.readVInt() != fieldNumber) { 22 throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 23 } 24 if (meta.readByte() != Lucene45DocValuesFormat.NUMERIC) { 25 throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 26 } 27 NumericEntry n2 = readNumericEntry(meta); 28 ordIndexes.put(fieldNumber, n2); 29 }
4. readSortedField
1 private void readSortedField(int fieldNumber, IndexInput meta, FieldInfos infos) throws IOException { 2 // sorted = binary + numeric 3 if (meta.readVInt() != fieldNumber) { 4 throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 5 } 6 if (meta.readByte() != Lucene45DocValuesFormat.BINARY) { 7 throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 8 } 9 BinaryEntry b = readBinaryEntry(meta); 10 binaries.put(fieldNumber, b); 11 12 if (meta.readVInt() != fieldNumber) { 13 throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 14 } 15 if (meta.readByte() != Lucene45DocValuesFormat.NUMERIC) { 16 throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")"); 17 } 18 NumericEntry n = readNumericEntry(meta); 19 ords.put(fieldNumber, n); 20 }
Solr4.8.0源码分析(11)之Lucene的索引文件(4)
标签:Lucene style blog http color io os 使用 java
原文地址:http://www.cnblogs.com/rcfeng/p/3987364.html