标签:des com http blog style div img code java c log
在JavaWeb开发中,使用tomcat,与字符编码有关的有
|
URIEncoding |
This specifies the character encoding used to decode the URI bytes, after %xx decoding the URL. If not specified, ISO-8859-1 will be used. 该属性用于指定用于解码URI的字符集,如果未指定则使用ISO8859-1 |
|
useBodyEncodingForURI |
This specifies if the encoding specified in contentType should be
used for URI query parameters, instead of using the URIEncoding.
This setting is present for compatibility with Tomcat 4.1.x, where
the encoding specified in the contentType, or explicitly set using
Request.setCharacterEncoding method was also used for the parameters
from the URL. The default value is
false. |
在Servlet规范中有这样一段描述,如下:
Currently,many browsers do not send a char encoding qualifier with the Content-
Typeheader, leaving open the determination of the character encoding for reading
HTTPrequests. The default encoding of a request the container uses to create the
request reader and parse POST data must be “ISO-8859-1” if none has been specified
bythe client request. However, in order to indicate to the developer, in thiscase, the
failureof the client to send a character encoding, the container returns null from
thegetCharacterEncoding method.
If the client hasn’t set character encoding and therequest data is encoded with a
differentencoding than the default as described above, breakage can occur. To
remedythis situation, a new method setCharacterEncoding(String enc) has
beenadded to the ServletRequest interface. Developers can override the
characterencoding supplied by the container by calling this method. It must be
calledprior to parsing any post data or reading any input from the request. Calling
thismethod once data has been read will not affect the encoding.
大体意思就是:
现在的大多数浏览器并不把使用的字符编码类型包含在header中发送给服务器。如果客户端请求中没有指定字符集,则Servlet容器用来创建request reader和解析POST data所使用的默认字符集必须是ISO8859-1。Servlet容器通过从getCharacterEncoding方法中返回null,来让开发者知道客户端并没有发送字符集。
当客户端并没有使用ISO8859-1,而Servlet容器仍然使用ISO8859-1来解析数据时,就会出现筹码问题。开发者可以调用setCharacterEncoding方法来告诉容器应该使用哪种字符集来解析数据,而且必须在从request中解析任何数据或读取任何输入之前调用,否则对已经读取的数据的字符集无影响。
作用:设置发送到客户端的response的字符编码。默认ISO8859-1
response.setContentType("text/html;charset=UTF-8");
上面一行代码等效于下面两行代码
response.setContentType("text/html");
response.setCharacterEncoding("UTF-8");
该方法必须在调动getWriter方法调动,否则起不到任何效果。
response.setContentType("text/html;charset=UTF-8");
System.out.println(response.getCharacterEncoding());//输出UTF-8
response.setCharacterEncoding("GBK");
System.out.println(response.getCharacterEncoding());//输出GBK
response.setContentType("text/html;charset=UTF-8");
PrintWriter pw =response.getWriter();
System.out.println(response.getCharacterEncoding()); //输出UTF-8
response.setCharacterEncoding("GBK");
System.out.println(response.getCharacterEncoding()); //输出UTF-8
pw.close();
response.setCharacterEncoding("GBK");
System.out.println(response.getCharacterEncoding()); //输出UTF-8
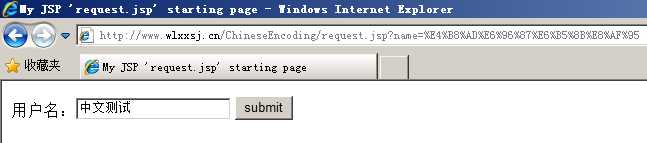
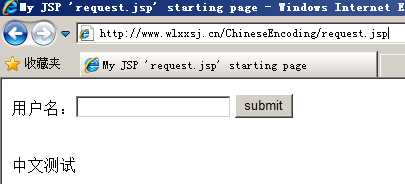
实验 ,验证编码请求数据所使用的字符集由谁来决定,测试文字“中文测试”
环境如下图所示:
|
条件 |
结果 |
|
pageEncoding="UTF-8" method="get" |
“中文测试”四个字经过URL编码后为:%E4%B8%AD%E6%96%87%E6%B5%8B%E8%AF%95 String utf8 = "UTF-8"; String encoded = "%E4%B8%AD%E6%96%87%E6%B5%8B%E8%AF%95"; System.out.println(URLDecoder.decode(encoded, utf8)); //输出结果为:中文测试 |
|
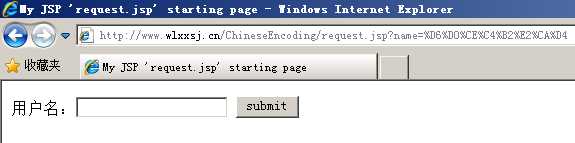
pageEncoding="GBK" method="get" |
“中文测试”四个字经过URL编码后为:%D6%D0%CE%C4%B2%E2%CA%D4 String gbk = "GBK"; String encoded = "%D6%D0%CE%C4%B2%E2%CA%D4"; System.out.println(URLDecoder.decode(encoded, gbk)); //输出结果为:中文测试 |
|
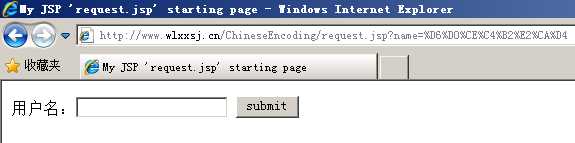
pageEncoding="GBK" URIEncoding="UTF-8" method="get" |
“中文测试”四个字经过URL编码后为:%D6%D0%CE%C4%B2%E2%CA%D4 String gbk = "GBK"; String encoded = "%D6%D0%CE%C4%B2%E2%CA%D4"; System.out.println(URLDecoder.decode(encoded, gbk)); //输出结果为:中文测试 |
|
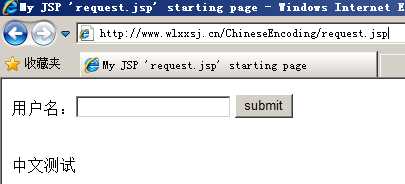
pageEncoding="UTF-8" URIEncoding="UTF-8" method="post" |
response.jsp文件主要代码如下: <body> <form action="request.jsp" method="post"> 用户名:<input name="name" type="text"> <input type="submit" value="submit"> </form> <% String name = request.getParameter("name"); if(name != null){ name = URLEncoder.encode(name, "ISO8859-1"); name = URLDecoder.decode(name, "UTF-8"); } %> <br/> <%= name %> </body>
输出结果:
|
|
pageEncoding="UTF-8" URIEncoding="UTF-8" Request.setCharact-erEncoding("UTF-8") method="post" |
response.jsp文件主要代码如下: <body> <form action="request.jsp" method="post"> 用户名:<input name="name" type="text"> <input type="submit" value="submit"> </form> <% request.setCharacterEncoding("UTF-8"); String name = request.getParameter("name"); if(name != null){ name = URLEncoder.encode(name, "UTF-8"); name = URLDecoder.decode(name, "UTF-8"); } %> <br/> <%= name %> </body>
输出结果:
|
实验结论
请求数据所使用的编码由浏览器当前使用的编码决定。
进一步的说明
Tomcat的server.xml文件中的Connector元素的URIEncoding属性只决定Tomcat将用哪种编码来解析URL带到服务器的数据,也就是通过get请求发送到服务器的数据。
request.setCharacterEncoding方法只决定Tomcat将用哪种编码来解析POST请求中的数据。在jsp文件中,设置pageEncoding属性值相当于调动了request.setCharacterEncoding方法,可以通过request.getCharacterEncoding方法进行验证。
response.setCharacterEncoding方法则决定Tomcat向客户端响应数据的编码,同时也会告诉客户端使用哪种编码来显示数据。通过该方法设置的编码将能够通过相应的getCharacterEncoding方法取得。在jsp文件中,response.setCharacterEncoding获取到的是pageEncoding属性的值,也就是说,在jsp文件中,设置pageEncoding属性的值就相当于在Servlet中调用response.setCharacterEncoding方法
乱码类型改解决方案
通过设置pageEncoding属性为一个支持中文的编码即可解决。
通过调用response.setCharacterEncoding方法设置一个支持中文的编码即可解决。
通过设置Tomcat的server.xml文件中Connector元素的URIEncoding属性为一个支持中文的编码即可解决。
通过设置pageEncoding属性为一个支持中文的编码即可解决。
通过调用request.setCharacterEncoding方法设置一个支持中文的编码即可解决。
客户端与Tomcat交互过程中的encode与decode图示
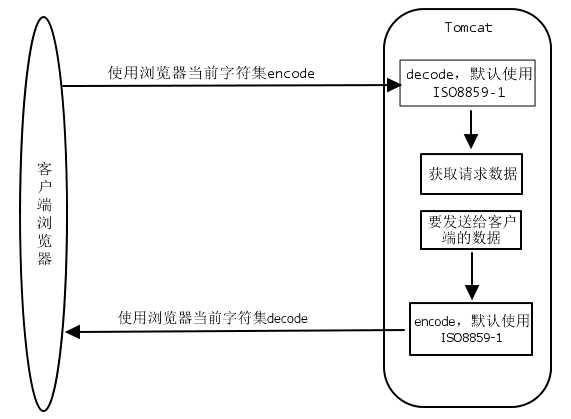
在不改变Tomcat默认字符集ISO8859-1的情况下,解决获取数据时出现乱码的另一种方案就是,先使用ISO8859-1 encode,再使用正确的字符集decode
String name =request.getParameter("name");
name = URLEncoder.encode(name, "ISO8859-1");
name =URLDecoder.decode(name, "UTF-8");
标签:des com http blog style div img code java c log
原文地址:http://www.cnblogs.com/daojoo/p/3698940.html