wcPro
1. github repo
https://github.com/YinshenYuan/wcPro
2. PSP表格
PSP2.1 | PSP阶段 | 预估耗时 (分钟) | 实际耗时 (分钟) |
Planning | 计划 | 60 | 60 |
· Estimate | · 估计这个任务需要多少时间 | 1000 | 1100 |
Development | 开发 | 200 | 200 |
· Analysis | · 需求分析 (包括学习新技术) | 70 | 70 |
· Design Spec | · 生成设计文档 | 60 | 60 |
· Design Review | · 设计复审 (和同事审核设计文档) | 20 | 20 |
· Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
· Design | · 具体设计 | 30 | 20 |
· Coding | · 具体编码 | 120 | 120 |
· Code Review | · 代码复审 | 30 | 30 |
· Test | · 测试(自我测试,修改代码,提交修改) | 500 | 500 |
Reporting | 报告 | 20 | 20 |
· Test Report | · 测试报告 | 20 | 20 |
· Size Measurement | · 计算工作量 | 800 | 830 |
· Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 65 |
合计 | 1000 | 1100 |
3. 对自己的接口的实现
在本项目中,我负责的接口是 (2)核心处理:对输入进行处理,如单词词频统计,排序等,完成对应业务需求。
我实现的方法为
public static Map<String, Integer> countWord(String content)该方法的参数为读入的文件的内容,输出为排好序的字典
要实现该算法并不难,首先是从读入的内容中得到符合要求的单词,可以使用正则表达式([a-zA-Z]|(?<=[a-zA-Z])-(?=[a-zA-Z]))+匹配(因为使用了正向预查与反向预查,所以这个正则表达式相当简洁);然后将单词插入未排序的词典,最后将词典排序按给定的要求排序即可得到排序了的词典。
方法的代码如下
/*
* The core method converting content to Map whose values are sorted(if two items has the
* same value, then sort the key using lexicographic order)
*/
public static Map<String, Integer> countWord(String content)
{
// Initialize the variables to be used, rawMap refers to the map
// unsorted, while sortedMap refers to the sorted map
Map<String, Integer> rawMap = new HashMap<String, Integer>();
MapUtil mu = new MapUtil(rawMap);
Map<String, Integer> sortedMap = new TreeMap<String, Integer>(mu);
content = content.toLowerCase(); // Convert the content to lower case
Pattern ptn = Pattern.compile("([a-zA-Z]|(?<=[a-zA-Z])-(?=[a-zA-Z]))+");
Matcher mch = ptn.matcher(content);
while(mch.find()) // Find the word satisfied with the requirement
{
String word = content.substring(mch.start(), mch.end());
Integer freq = rawMap.get(word);
rawMap.put(word, (freq == null) ? 1 : freq + 1);
}
// Sort the rawMap
sortedMap.putAll(rawMap);
return sortedMap;
}其中使用的MapUtil类是一个实现了Comparator类的用于将词典排序的类,实现的代码如下
/*
* This class is a map utility used for sorting a map
*/
class MapUtil implements Comparator<String> {
Map<String, Integer> base;
public MapUtil(Map<String, Integer> base) {
this.base = base;
}
// Note: this comparator imposes orderings that are inconsistent with
// equals.
public int compare(String a, String b)
{
int valueA = base.get(a);
int valueB = base.get(b);
if (valueA > valueB || valueA == valueB && a.compareTo(b) < 0) {
return -1;
} else {
return 1;
}
}
}4. 测试用例的设计
为了满足测试效率的要求,需要测试用例设计的有典型性,因为该方法没有条件分支语句,所以难以使用白盒测试的方法,因此选择使用黑盒测试中的等价类划分和边界值测试的方法。
我的测试用例主要可以分为三大类,每一类各有侧重:
(1)用于测试正则表达式是否可以正确地匹配到各个单词,例如测试是否可以匹配被标点字符分隔的单词,被特殊字符分隔的单词,被多个-分隔的字符,以及位于单词前面与后面的-能否被去掉,该类测试用例编写如下
// cnt is the array containing input string, and ept contains excepted output
// Case 0: When the input is empty
cnt[0] = "";
// Case 1: When the input is not empty but doesn‘t contain any valid word
cnt[1] = "- -- ;*_123 1-2 :<>{ }\r \n \t";
// Case 2: When the input contains only one valid word
cnt[2] = "hello";
ept[2].put("hello", 1);
// Case 3: When the input contains the same word but some letters are in upper case
cnt[3] = "hello Hello hELLO HELLO HellO";
ept[3].put("hello", 5);
// Case 4: When the input contains words having a preceding or following hyphen
cnt[4] = "hello -hello hello- -hello----hello--";
ept[4].put("hello", 5);
// Case 5: When the input contains some quotation marks
cnt[5] = "hello hello‘hello hello\"hello‘\"hello";
ept[5].put("hello", 6);
// Case 6: When input contains words surrounded by numbers
cnt[6] = "hello233hello233-233hello-233hello233hello-233";
ept[6].put("hello", 5);
// Case 7: When the input contains words surrounded by non-alphanumeric characters
cnt[7] = "hello*hello)(-hello.&%hello\\hello ,[]hello;hello";
ept[7].put("hello", 7);
// Case 8: When the input contains words surrounded by control characters
cnt[8] = "hello\rhello hello\nhello\r\nhello\t\thello";
ept[8].put("hello", 6);
// Case 9: When the input contains all kinds of characters
cnt[9] = "hello-233hello.-:hello%$hello233+\n\thello‘hello--hello-233";
ept[9].put("hello", 7);
(2)测试能否对词典进行正确的排序,如不同的单词有不同的频率的情况,不同的单词有相同的频率的情况,单元测试的代码如下:
// Case 10: When the input contains words having different frequencies
cnt[10] = "hello hello hi";
ept[10].put("hello",2);
ept[10].put("hi", 1);
// Case 11: When the input contains words having the same frequency
cnt[11] = "hello hi hello hi ";
ept[11].put("hello", 2);
ept[11].put("hi", 2);
// Case 12: When the input contains words both having different frequencies and the same frequency
cnt[12] = "hello aloha hi hi hello";
ept[12].put("hello", 2);
ept[12].put("hi", 2);
ept[12].put("aloha", 1);
// Case 13: When the input contains words concatenated using hyphens
cnt[13] = "hello-hello hello hello--hello- -hello-hello--";
ept[13].put("hello", 3);
ept[13].put("hello-hello", 2);
// Case 14: When the input contains words that are in upper case
cnt[14] = "hello Hi HeLLo hI hi HELLO hellO";
ept[14].put("hello", 4);
ept[14].put("hi", 3);(3)测试对于处于各种边界值的情况,如词典大小为0,1,99,100,101时能否给出正确的输出,由于在这类测试中预期输出的词典较大,所以我专门构造了方法用于产生输入与预期的输出,编写测试用例的代码如下
// Case 15: When the input contains 1 different words
ArrayList lst1 = ctrTestCase(1); // ctrTestCase() is used to construct test case of different size
cnt[15] = (String)lst1.get(0);
ept[15] = (LinkedHashMap<String, Integer>)lst1.get(1);
// Case 16: When the input contains 99 different words
ArrayList lst99 = ctrTestCase(99);
cnt[16] = (String)lst99.get(0);
ept[16] = (LinkedHashMap<String, Integer>)lst99.get(1);
// Case 17: When the input contains 100 different words
ArrayList lst100 = ctrTestCase(100);
cnt[17] = (String)lst100.get(0);
ept[17] = (LinkedHashMap<String, Integer>)lst100.get(1);
// Case 18: When the input contains 101 different words
ArrayList lst101 = ctrTestCase(101);
cnt[18] = (String)lst101.get(0);
ept[18] = (LinkedHashMap<String, Integer>)lst101.get(1);
// Case 19: When the input contains 200 different words
ArrayList lst200 = ctrTestCase(200);
cnt[19] = (String)lst200.get(0);
ept[19] = (LinkedHashMap<String, Integer>)lst200.get(1);5. 单元测试评价
单元测试的运行截图如下
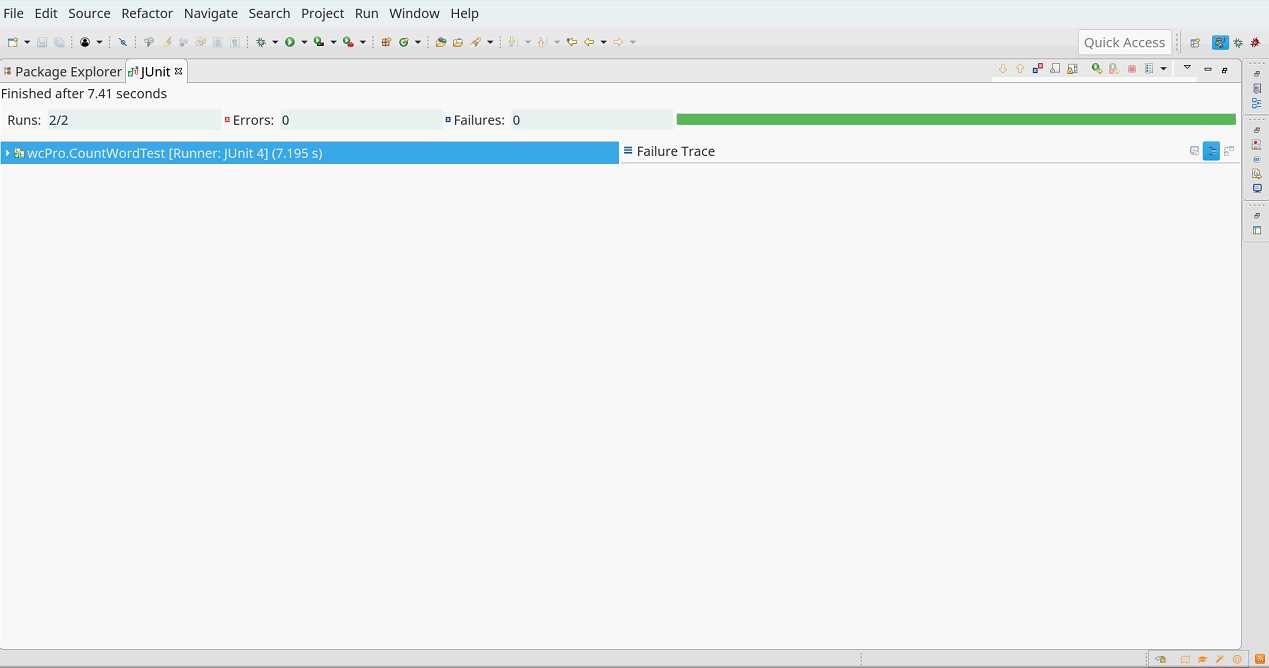
以上的20个测试用例,具有较好的典型性,因此单元测试与被测模块的质量均可达到要求。
6. 对开发规范的理解
关于开发规范,我们小组选择了《阿里巴巴Java开发手册》作为蓝本。现摘抄一段如下
【推荐】表达异常的分支时,少用if-else方式,这种方式可以改写成:
if (condition) {
...
return obj;
}
// 接着写else的业务逻辑代码;
说明:如果非得使用if()...else if()...else...方式表达逻辑,【强制】避免后续代码维护困难,请勿超过3层。
正例:超过3层的 if-else 的逻辑判断代码可以使用卫语句、策略模式、状态模式等来实现,其中卫语句示例如下:
public void today() {
if (isBusy()) {
System.out.println(“change time.”);
return;
}
if (isFree()) {
System.out.println(“go to travel.”);
return;
}
System.out.println(“stay at home to learn Alibaba Java Coding Guidelines.”);
return;
}
看到这个规范,让我不由想起了刚沈刚老师的《数据结构》课程时的青葱岁月。那个时候沈刚老师说如果if中包含了return,那么不需要else子句。当时我就想:哇,还有这种操作!在阿里的开发手册中,也有相似的内容,这么做可以减少else子句,使得代码更加简洁和美观。
7. 对组员代码的评价
以以上规范为标准,我审查了H同学(17165)的代码,发现有可以根据该规范予以改进的地方。
源代码如下
String err = null;
if( args[0]== null )
{
err = "No input";
System.err.println("No input");
System.exit(1);
}//Lack of input
else if (args[0] == "-x")//when first input is -x
{
if(args.length > 1)// more than one input
{
err = "You must use -x alone";
System.err.println("You must use -x alone");
System.exit(1);
}
else
{
Window guiWnd = new Window();
guiWnd.showDialog();
}
}
else if(!args[0].endsWith(".txt"))//file name doesn‘t end with .txt
{
err = "The file doesn‘t end with .txt ";
System.err.println( "The file doesn‘t end with .txt ");
System.exit(1);
}
else if(args.length > 1)//more than one input
{
err = "More than one input";
System.err.println("More than one input");
System.exit(1);
}
else//one file path input
{
String content = getContent(args[0]);
if(content==null)
{
err = "can‘t open file";
System.err.println("can‘t open file");
System.exit(1);
}
else
{
Map<String, Integer> map = countWord(content);
if(map==null)
{
err = "can‘t record map";
System.err.println("can‘t record map");
System.exit(1);
}
else
{
if(!writeOutput(map))
{
err = "can‘t open file";
System.err.println("can‘t open file");
System.exit(1);
}
}
err = "write file finished";
}
}
return err;这段代码为程序的主要逻辑,含有大量的异常处理,所以出现了大量的乃至嵌套的else子句,使代码难以阅读。使用了该标准后,代码修改如下(同时将代码进行了拆分,将参数解析与方法调用分开,使程序逻辑更为清晰):
public static String argsInfo(String[] args)
{
String argsinfo = null;
if( args[0]== null )//Lack of input
{
argsinfo = "No input";
return argsinfo;
}
if(args.length > 1)//more than one input
{
argsinfo = "More than one input";
return argsinfo;
}
if (args[0] == "-x")//when first input is -x
{
argsinfo = args[0];
return argsinfo;
}
else if(!args[0].endsWith(".txt"))//file name doesn‘t end with .txt
{
argsinfo = "The file doesn‘t end with .txt ";
return argsinfo;
}
return args[0];//normal situation return path
}
public static String exec(String argsinfo)
{
String err = null;
if( argsinfo == null )//Lack of input
{
err = "args err";
return err;
}
if(argsinfo == "No input" || argsinfo == "More than one input" || argsinfo == "The file doesn‘t end with .txt ")
{
return argsinfo;
}//when args err
else if(argsinfo == "-x" )//when first input is -x
{
Window guiWnd = new Window();
guiWnd.showDialog();
}
else // when normal situation return path
{
String content = getContent(argsinfo);
if(content==null)
{
err = "file does not exist";
return err;
}
Map<String, Integer> map = countWord(content);
if(!writeOutput(map))
{
err = "can‘t write file";
return err;
}
return "write file finished";
}
return "Window";
}可以看到,else子句大大减少,程序更为美观。
8. 静态代码检查
在本次实验中,我们小组用的静态代码检查工具为FindBugs,其下载与使用教程见FindBugs ,对代码进行静态检查的运行截图如下:
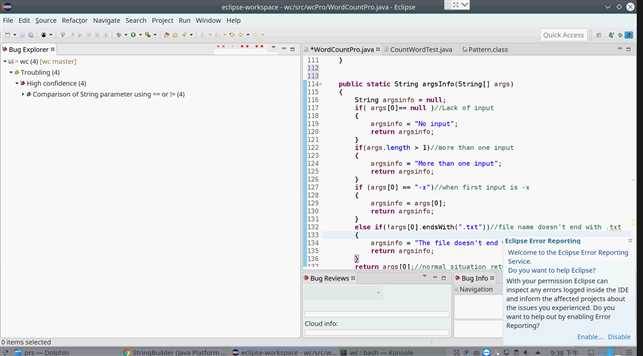
我负责的代码中并没有出现Troubling,说明我编写代码的习惯较为良好。组内其他成员的代码中出现的Troubling也是虚晃一枪(使用==、!=和字符串常量比较),所以证明了小组内代码的质量很高。不过为了消除警告,还是修改了代码,修改后截图如下:
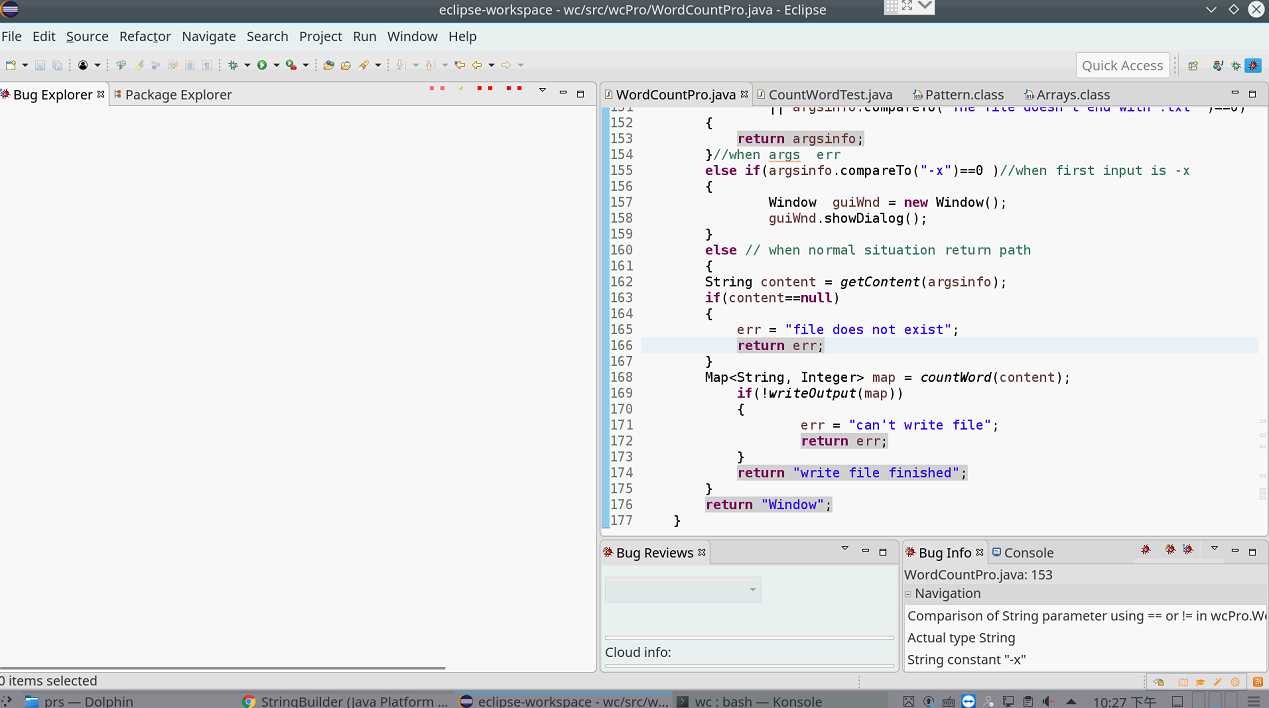
9. 测试数据集的设计思路
因为我负责的模块的输入是String,所以我对测试数据集的设计思路是产生一极长的字符串,然后以该字符串为输入,测试多长的字符串会给模块造成压力。
10. 同行评审
在同行评审中,我们小组以模块为单位,分别讨论每个模块是否可以优化以及怎么进行优化。每个人讲解自己的负责的模块,其他人进行评审。对于我的模块,因为构造未排序的词典时间复杂为O(n),所以主要的瓶颈为时间复杂度为O(lg(n)的对词典的排序,但是该排序无法避免,且不能用多线程进行优化,所以得到的结论为我负责的模块已经无法优化。
11. 压力测试
为了测试我负责的模块的极限,大约500MB大小的字符串的处理时间为55.363秒,大约1GB大小的字符串处理时间为115.115秒,对于再大些的输入其本身会将java堆内存耗尽,所以无法测试,足以见到该模块对于较大的输入也能轻松胜任。(压力测试结果依赖与硬件性能,所以在不同的机器上跑结果可能会有很大的不同)
12. 感想与其他
通过本次作业,我感受到在软件开发的过程中,软件质量需要软件测试来保证。单元测试的编写不仅可以保证自己写的代码符合需求,而且可以在代码重构以后轻松地验证自己的代码没有问题,很大程度上保证了代码的质量。而且我感受到,编写单元测试的一个很大的好处是在编写测试用例与预期输出的过程中,可以对需求有更准确与清晰的认识,因此可以使代码的质量更高。
因为我在小组中担任组长,设计了程序的架构,且负责核心模块的编写,因此在讨论后,得到了较高的小组贡献率:33%