标签:需求 计算 rds 问题 design transform lin 大量数据 提醒
小组github地址
基本任务
一.PSP表格
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
20 | 20 |
|
· Estimate |
· 估计这个任务需要多少时间 |
10 | 10 |
|
Development |
开发 |
60 | 60 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
20 | 15 |
|
· Design Spec |
· 生成设计文档 |
50 | 60 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
60 | 100 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
60 | 100 |
|
· Design |
· 具体设计 |
60 | 150 |
|
· Coding |
· 具体编码 |
100 | 180 |
|
· Code Review |
· 代码复审 |
60 | 100 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
40 | 60 |
|
Reporting |
报告 |
60 | 100 |
|
· Test Report |
· 测试报告 |
60 | 80 |
|
· Size Measurement |
· 计算工作量 |
20 | 30 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 | 30 |
|
合计 |
710 | 1095 |
二.模块接口设计
这次小组作业我们分了四个模块,分别是输入,核心,输出,main函数整合。我做的模块是输出模块。我按照作业要求仔细地分析了输出模块
的需求和功能:1.仅输出单词词频从高到低前100个,因此需要写一个判断,当单词数量少于100个时,按照单词实际数量输出,如果单词数量多于
100个时,只输出前100个单词。2.每行分别给出一个单词及其词频,这就需要做两个数组,一个显示单词,另一个显示单词词频。3.单词按小写形
式给出,需要将含有大写字母的单词进行转换,转换成对应的小写字母。4.对于单词词频相同的情况,按照单词所包含的每个字母从a到z的次序依
次排列,这就需要对每个单词的每个字母的ascll码进行逐位比较,然后进行排序。
输出模块是在wcoutput类中用一个函数output(String[] word,int[] wordFreq)实现的,函数的两个参数是两个数组,一个数组是存储单词的,另一个
数组是存储单词频率的,传入的数组是待处理的,先判断两个数组里元素的个数是否相等,不相等则报错;相等的话,继续规格化处理,将单词和词频
转化成需要的标准格式,然后循环输出。
三.模块设计的代码实现
主体函数output(String[] word,int[] wordFreq),在与其他组员拼接时由于兼容性的问题,将其写成了output(ArrayList<String> word,ArrayList<Integer> wordFreq)
的样子,该函数接收核心模块的输出结果,将核心模块得到的单词和词频进一步规格化处理。首先是单词大小写的问题,String Uppercase = "ABCDEFGHIJKLMN
OPQRSTUVWXYZ";if(Uppercase.indexOf(ascll)!=-1);用这两句代码,遇到任意26个大写字母时,就将对应字母转化为小写字母。遇到小写和其他字符时,则跳过。
当单词词频相等时,wordFreq[i]==wordFreq[j],对两个单词一位一位地进行比较,将ascll码大的放在后面else if(word[i].charAt(serial)>word[j].charAt(serial))
{temp = word[i];word[i]=word[j];word[j]=temp;}遇到如下两种单词,"app","apple"则长度短的放前面,长的放后面。最后将单词和词频循环输出。
该模块的代码说明已经在代码注释上进行了详细的分析:
public static void output(String[] word,int[] wordFreq) { String Uppercase = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"; String lowercase = "abcdefghijklmnopqrstuvwxyz"; char arr[]= new char[100]; String newword = "";//更新大小写后的单词 int out; int ascll; int length; int serial=0; try { if(word.length!=wordFreq.length) System.out.println("Error handle!"); else { //向默认文件"result.txt"中输出信息 FileOutputStream fs =new FileOutputStream(new File("result.txt")); PrintStream p =new PrintStream(fs); //输出数组元素个数大于100时只输出前100个 if(wordFreq.length>100) out=100; //否则按实际个数输出 else out = wordFreq.length; for(int i=0;i<word.length;i++) { newword = ""; for(int j=0;j<word[i].length();j++) { ascll=word[i].charAt(j);//把字符转换成对于的Ascll码 //如果是大写转换成小写 if(Uppercase.indexOf(ascll)!=-1) { arr[j]=lowercase.charAt(Uppercase.indexOf(ascll)); newword +=arr[j]; } //如果是小写或其它字符则保持不变 else { arr[j]=word[i].charAt(j); newword +=arr[j]; } } word[i]=newword;//重置数组里的每个单词 } //词频相等时排序处理 String temp = ""; for(int i=0;i<wordFreq.length;i++) for(int j=i+1;j<wordFreq.length;j++) { //在比较的两个单词中取最短的长度 if(word[i].length()<word[j].length()) length = word[i].length(); else length = word[j].length(); //词频相等时进行排序 if(wordFreq[i]==wordFreq[j]) { for(;serial<length;serial++)//单词一位一位比较 { //当前一个单词的某位字母小于后一个单词的对应位字母时,不改变原顺序 if(word[i].charAt(serial)<word[j].charAt(serial)) break; //当前一个单词的某位字母等于后一个单词的对应位字母时,继续比较下一位字母 else if(word[i].charAt(serial)==word[j].charAt(serial)) continue; //当前一个单词的某位字母大于后一个单词的对应位字母时,交换两个单词的顺序 else if(word[i].charAt(serial)>word[j].charAt(serial)) { temp = word[i]; word[i]=word[j]; word[j]=temp; break; } } //当某一个单词里的字母已经比较完了仍没有结果 if(serial==length) { if(word[i].length()<word[j].length()) ; //单词长的放后面 else { temp = word[i]; word[i]=word[j]; word[j]=temp; } } serial=0; } //词频不等时打破内层循环(该单词不会再与后面单词相等),从外层循环继续 else break; } //最后的输出 for(int i=0;i<out;i++) { System.out.println(word[i]+" "+wordFreq[i]); p.println(word[i]+" "+wordFreq[i]); } } } catch(IOException e) { return; } }
四.测试设计过程
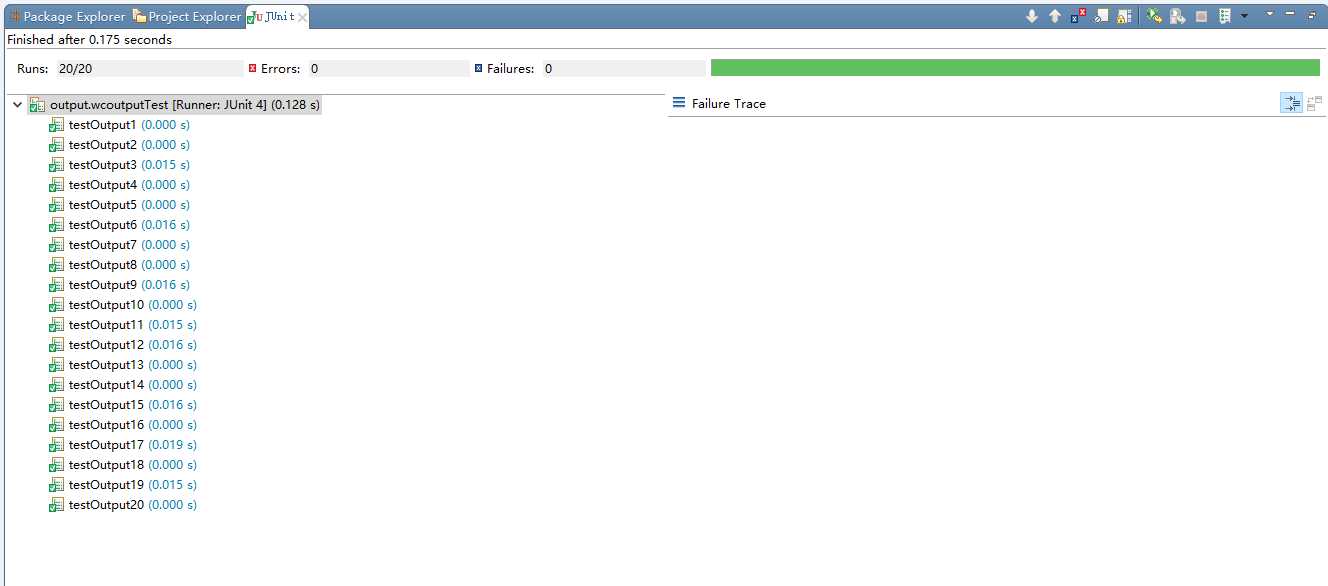
关于测试脚本:首先安装了Junit4包,然后根据被测试类wcoutput,创建了wcoutputTest类。在测试类中调用被测试类中的output
(ArrayList<String> words,ArrayList<Integer> wordsNum)函数,然后利用断言assertEuqals比较理想输出和实际输出,相等则通过,
不相等则报错。(其中理想输出是指经规范化处理之后的单词和词频形式,其中单词和词频分别存储在两个数组中,即对数组中元素的测试)
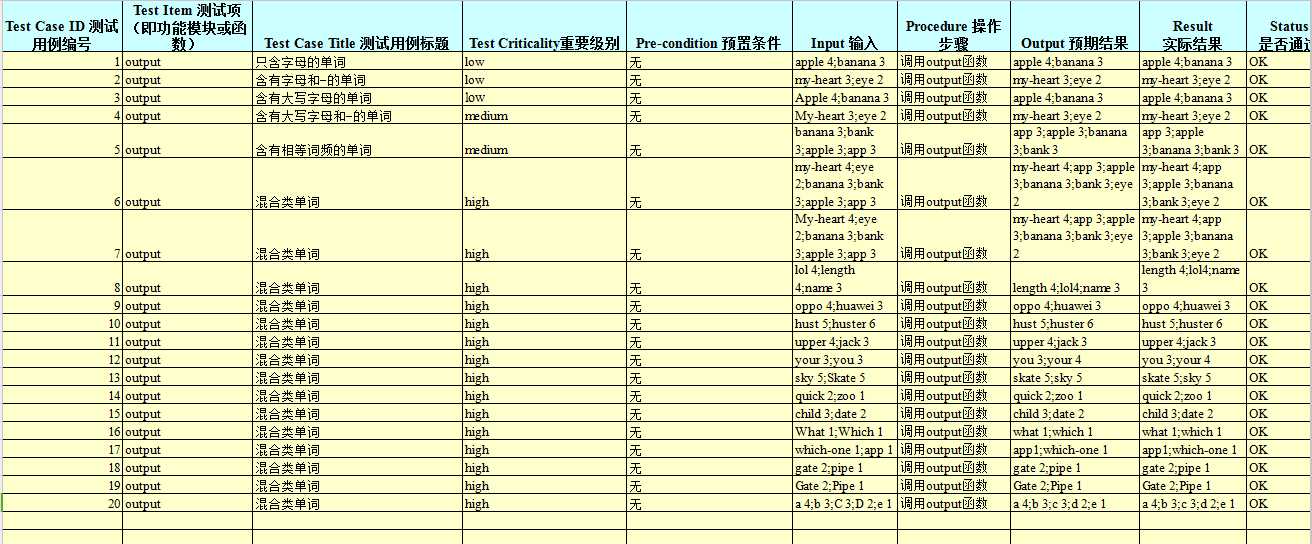
此处仅列出一个测试用例:
public class wcoutputTest @Before public void setUp() throws Exception { } @Test public void testOutput() { //fail("Not yet implemented"); //测试用例 String[] word1={"excuse","la","apple","Banana","lol","what","lala","s"}; int[] wordFreq1={4,3,2,2,2,2,2,1}; //调用被测试类的输出函数 wcoutput.output(word1, wordFreq1);System.out.println("\n"); //理想输出 String[] expword1={"excuse","la","apple","banana","lala","lol","what","s"}; //int[] expwordFreq={4,3,2,2,2,2,2,1}; assertEquals(word1,expword1); }
小组贡献评价
本次作业分了四个模块,我的输出模块涉及到了最后的输出,并进行了一系列规范化处理,在功能的难易程度上仅次于核心模块,评分为 0.25
扩展任务
1. 开发规范说明
我们选择的是附录4中的规范,用的是3.4.1 代码规范与复审(精简版)现代软件工程讲义 3 代码规范与代码复审。
2. 交叉代码评审
我这次除了评审自己的代码(17050)外,还评审了17048同学的代码:
该同学代码严格按照java类框架,按照类属性,构造方法,get,set方法进行构造,格式规范。在适当的地方合理使用注释,简洁明了。
但我发现该同学模块并没有进行适当的报错处理,缺少用户反馈。另外该同学没有调整他代码的行宽和缩进,不太注重格式要求。
3. 静态代码检查工具
使用了FindBugs静态分析工具
下载地址:
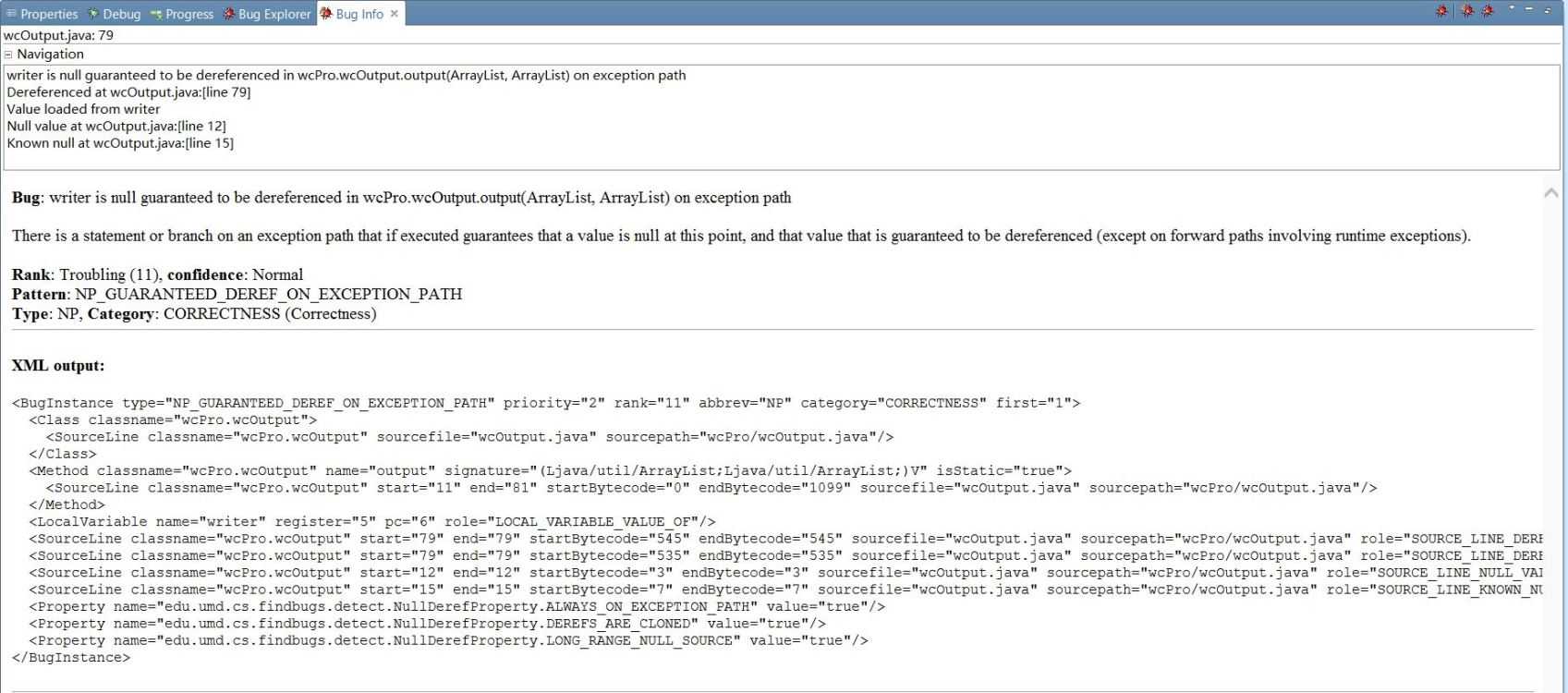
1.自己的模块扫描(17050)
出错原因分析:exception分支上,存在引用一个null对象的方法,引发空指针异常。
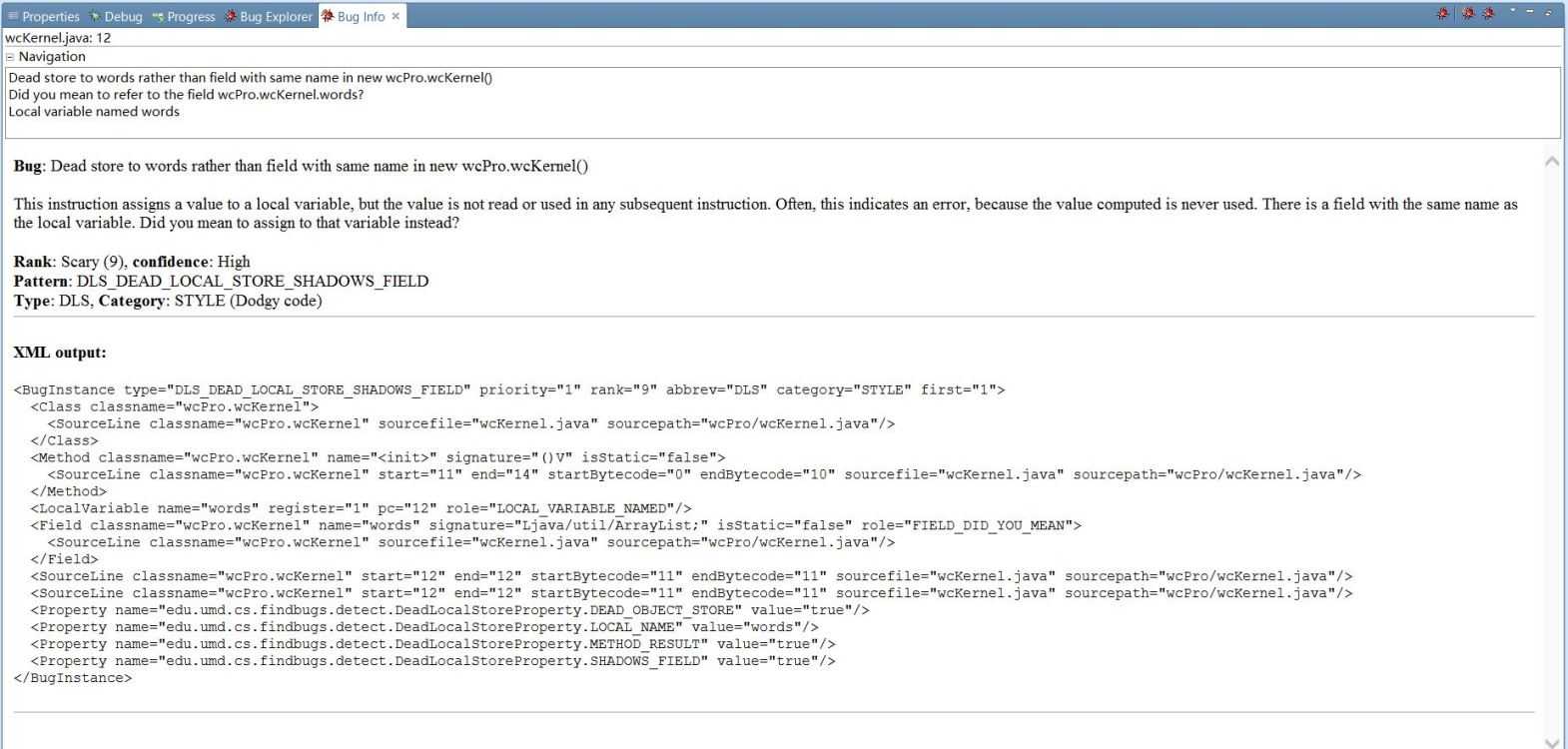
2.其他成员模块扫描(17048)
出错原因分析:成员变量和局部变量重名
解决方案
修改某一个变量的命名
高级任务
(1)测试数据集的设计思路
衡量一个程序好坏的性能指标有很多,比如:程序在长时间运行下出bug的概率,在大数据作用下是否出错,程序运行时间会不会超过用户的忍
受上限等。设计思路:先对优化前的程序进行运行时间测试,然后再测试优化后的程序运行时间,分析是什么原因导致这两者之间的时间差异,得出普遍结论。
(2)优化前的程序
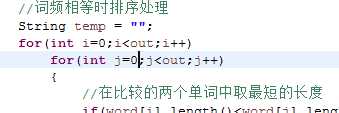
//词频相等时排序处理 String temp = ""; for(int i=0;i<out;i++) for(int j=0;j<out;j++) { //在比较的两个单词中取最短的长度 if(word[i].length()<word[j].length()) length = word[i].length(); else length = word[j].length(); //词频相等时进行排序 if(wordFreq[i]==wordFreq[j]) { for(;serial<length;serial++)//单词一位一位比较 { //当前一个单词的某位字母小于后一个单词的对应位字母时,不改变原顺序 if(word[i].charAt(serial)<word[j].charAt(serial)) break; //当前一个单词的某位字母等于后一个单词的对应位字母时,继续比较下一位字母 else if(word[i].charAt(serial)==word[j].charAt(serial)) continue; //当前一个单词的某位字母大于后一个单词的对应位字母时,交换两个单词的顺序 else if(word[i].charAt(serial)>word[j].charAt(serial)) { temp = word[i]; word[i]=word[j]; word[j]=temp; break; } } //当某一个单词里的字母已经比较完了仍没有结果 if(serial==length) { if(word[i].length()<word[j].length()) ; //单词长的放后面 else { temp = word[i]; word[i]=word[j]; word[j]=temp; } } serial=0; } //词频不等时打破内层循环(该单词不会再与后面单词相等),从外层循环继续 else break; }
运行时间: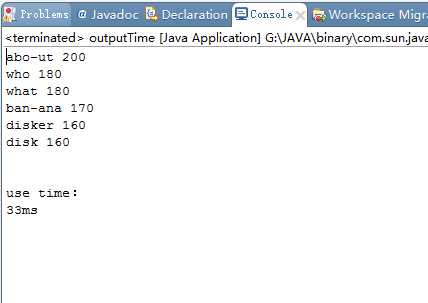
(3)同行评审
参与人员:冷福星(17048),李慎纲(17050),付佳韵(17039),康之是(17040)。主持人:康之是。评审员:李慎纲,付佳韵。
评审对象:核心模块及输出模块
评审意见:对于错误输入有报错和提醒,对于可以忽略的错误能自动处理,容错率提高。但代码的规范化程度仍有待提高,
注释不专业,不该注释的地方随意注释,代码行宽和缩进没有调整。
(4)实际结论
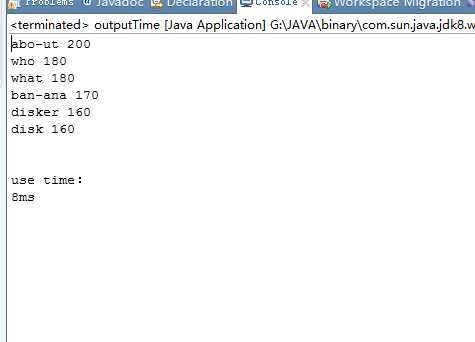
影响程序运行时间的重要因素是循环体,循环的次数越多,程序运行越缓慢,在大量数据的导入时甚至会出现
卡死的情况。
(5)优化思路
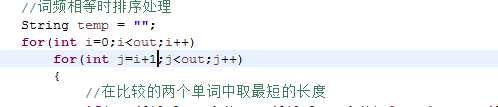
在算法层次上减少循环,减轻程序运算负担
优化前的循环:
优化后的循环:
程序运行时间明显缩短:
(6)项目总结
通过这次项目,我完成了基本任务,扩展任务,高级任务,学到了很多东西,也学会了如何将自己模块与组员进行对接,以及对接时应做的修改。另外我对软件开发,
软件测试,软件质量之间的关系有了深刻的认识。没有软件开发就没有软件测试,软件开发为软件测试提供对象。软件开发和软件测试都是软件生命周期中的重要组
成部分。软件测试是保证软件质量的重要手段。
参考链接
https://wk.baidu.com/view/b121cf8402d276a200292e12
标签:需求 计算 rds 问题 design transform lin 大量数据 提醒
原文地址:https://www.cnblogs.com/LiShengang/p/8722742.html