标签:直接 tail span center 类别 fill nts 复杂 min
基于 word2vec 和 CNN 的文本分类 :综述 & 实践 https://zhuanlan.zhihu.com/p/29076736
一、决策树(Decision Trees)
二、人工神经网络
准确度高 并行分布处理能力强,分布存储及学习能力强,鲁棒性好 联想记忆 神经网络需要大量的参数,如网络拓扑结构、
三、遗传算法 编程实现比较复杂四、KNN算法(K-Nearest Neighbour) 简单、有效 新训练的代价较低 KNN方法主要靠周围有限的邻近的样本 而不是靠判别类域的方法来确定所属类别的 适用交叉或重叠较多的待分样本集 样本容量比较大 可解释性不强,决策树的可解释性较强。
五、支持向量机(SVM)
小样本 高泛化 高维 非线性 避免神经网络结构选择和局部极小点
1、对缺失数据敏感。
2、对非线性问题没有通用解决方案,必须谨慎选择Kernelfunction来处理。
六、朴素贝叶斯
要知道先验概率 分类决策存在错误率
七、Adaboosting方法
高精度 提供的是框架。
不用担心overfitting。
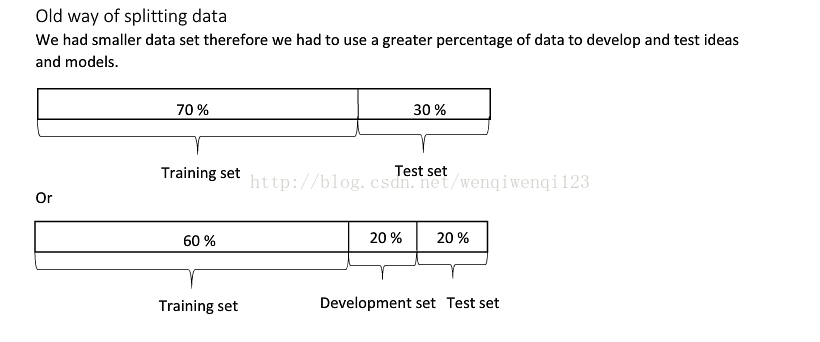
机器学习传统方法的时候,一般将训练集和测试集划为7:3.
若有验证集,则划为6:2:2. 当数据量不大的时候(万级别及以下)。
在深度学习中若是数据很大(百万级以上),我们可以将训练集、验证集、测试集比例调整为98:1:1
Bag of words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现
评估模型的预测性能 减小过拟合 获取多有效信息。
前者是生成式模型,后者是判别式模型,二者的区别就是生成式模型与判别式模型的区别。
1)Navie Bayes通过已知样本求得先验概率P(Y), 及条件概率P(X|Y), 对于给定的实例,计算联合概率,进而求出后验概率。也就是说,它尝试去找到底这个数据是怎么生成的(产生的),然后再进行分类。哪个类别最有可能产生这个信号,就属于那个类别。
优点:样本容量增加时,收敛更快;隐变量存在时也可适用。
缺点:时间长;需要样本多;浪费计算资源
2)相比之下,Logistic回归直接给出预测模型的式子。设每个特征都有一个权重,训练样本数据更新权重w,得出最终表达式。梯度法。
优点:直接预测往往准确率更高;简化问题;可以反应数据的分布情况,类别的差异特征;适用于较多类别的识别。
缺点:收敛慢;不适用于有隐变量的情况。
max_document_length: 文档的最大长度。如果文本的长度大于最大长度,那么它会被剪切,反之则用0填充。
min_frequency: 词频的最小值,出现次数小于最小词频则不会被收录到词表中。
vocabulary: CategoricalVocabulary 对象。
tokenizer_fn:分词函数
标签:直接 tail span center 类别 fill nts 复杂 min
原文地址:https://www.cnblogs.com/qianyuesheng/p/8743760.html