标签:并行 文本 并且 png 权重 重要性 割点 通过 个数
TF-IDF算法
TF-IDF(词频-逆文档频率)算法是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。该算法在数据挖掘、文本处理和信息检索等领域得到了广泛的应用,如从一篇文章中找到它的关键词。
主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上就是 TF*IDF,其中 TF(Term Frequency),表示词条在文章Document 中出现的频率;IDF(Inverse Document Frequency),其主要思想就是,如果包含某个词 Word的文档越少,则这个词的区分度就越大,也就是 IDF 越大。对于如何获取一篇文章的关键词,我们可以计算这边文章出现的所有名词的 TF-IDF,TF-IDF越大,则说明这个名词对这篇文章的区分度就越高,取 TF-IDF 值较大的几个词,就可以当做这篇文章的关键词。
计算步骤
-
计算词频(TF)

-
计算逆文档频率(IDF)
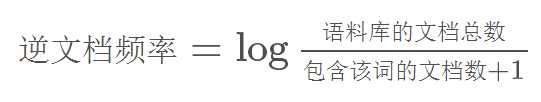
-
计算词频-逆文档频率(TF-IDF)
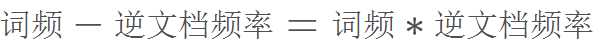
贝叶斯:
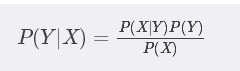

垃圾邮件识别 分词 条件独立假设 简单高效,吊丝逆袭
训练集是有限的,而句子的可能性则是无限的。所以覆盖 所有句子可能性的训练集是不存在的。
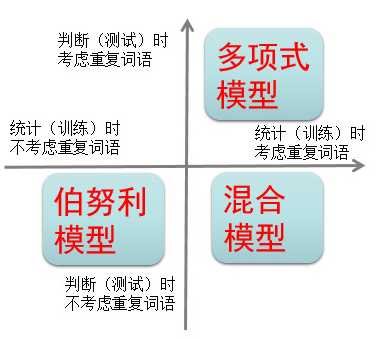
贝叶斯公式 + 条件独立假设 = 朴素贝叶斯方法
匹配关键词来识别垃圾邮件准确率太低 词语会随着时间不断变化
工程上的一些tricks
取对数 转换为权重 选取topk的关键词 分割样本 位置权重
GBDT:
1) 可以灵活处理各种类型的数据,包括连续值和离散值。
2) 在相对少的调参时间情况下,预测的准备率也可以比较高。这个是相对SVM来说的。
3)使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
GBDT的主要缺点有:
1)由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
集成学习
流程:
1、数据收集
2、除去数据中非文本部分
3、处理中文编码问题
4、中文分词
5、引入停用词
6、特征处理
7、建立分析模型
xgboost相比传统gbdt有何不同?xgboost为什么快?xgboost如何支持并行?
作者:wepon链接:https://www.zhihu.com/question/41354392/answer/98658997来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- GBDT以CART作为基分类器, xgboost还支持线性分类器,xgboost==逻辑斯蒂回归+L1和L2正则化项(分类问题)或者线性回归(回归问题)。
- GBDT在优化时只用到一阶导数信息 则对代价函数进行二阶泰勒展开和一阶、二阶导数。支持自定义代价函数(可一阶和二阶导)
- 在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
- 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 可并行的近似直方图算法,高效地生成候选的分割点。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低
模型融合 ML_8课程
IMPORTANT NOTES
标签:并行 文本 并且 png 权重 重要性 割点 通过 个数
原文地址:https://www.cnblogs.com/qianyuesheng/p/8743288.html