标签:ext 时间转换 beautiful 字符 datetime pre span img 爬取
1. 用requests库和BeautifulSoup库,爬取校园新闻首页新闻的标题、链接、正文、show-info。
2. 分析info字符串,获取每篇新闻的发布时间,作者,来源,摄影等信息。
3. 将字符串格式的发布时间转换成datetime类型
4. 使用正则表达式取得新闻编号
5. 生成点击次数的Request URL
6. 获取点击次数
7. 将456步骤定义成一个函数 def getClickCount(newsUrl):
8. 将获取新闻详情的代码定义成一个函数 def getNewDetail(newsUrl):
9. 尝试用使用正则表达式分析show info字符串,点击次数字符串。
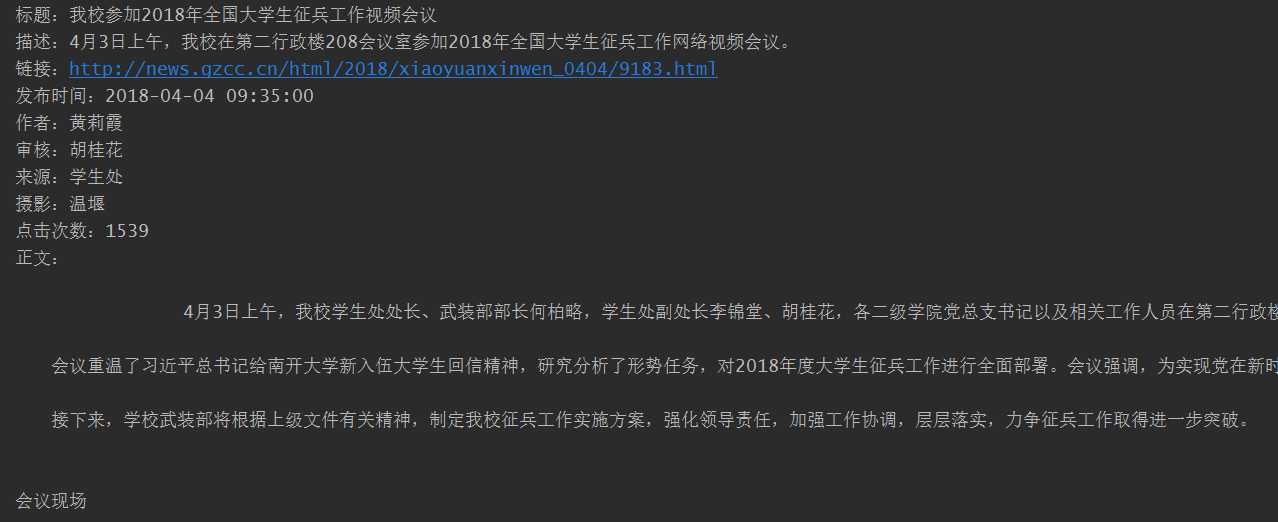
# -*- coding : UTF-8 -*- # -*- author : Kamchuen -*-+ import requests from bs4 import BeautifulSoup from datetime import datetime import locale import re locale.setlocale(locale.LC_CTYPE,‘chinese‘) newsurl = ‘http://news.gzcc.cn/html/xiaoyuanxinwen/‘ res = requests.get(newsurl) #返回response res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text,‘html.parser‘) def getClickCount(newsUrl): #获取点击次数 newsId = re.findall(‘\_(.*).html‘, newsUrl)[0].split(‘/‘)[1] #使用正则表达式取得新闻编号 clickUrl = ‘http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80‘.format(newsId) clickStr = requests.get(clickUrl).text return(re.search("hits‘\).html\(‘(.*)‘\);",clickStr).group(1)) def getNewDetail(newsUrl): #获取新闻详情 resd = requests.get(newsUrl) # 返回response resd.encoding = ‘utf-8‘ soupd = BeautifulSoup(resd.text, ‘html.parser‘) print(‘标题:‘ + title) print(‘描述:‘ + description) print(‘链接:‘ + newsUrl) info = soupd.select(‘.show-info‘)[0].text time = re.search(‘发布时间:(.*) \xa0\xa0 \xa0\xa0作者:‘, info).group(1) dtime = datetime.strptime(time, ‘%Y-%m-%d %H:%M:%S‘) #时间转换成datetime类型 print(‘发布时间:{}‘.format(dtime)) print(‘作者:‘ + re.search(‘作者:(.*)审核:‘, info).group(1)) print(‘审核:‘ + re.search(‘审核:(.*)来源:‘, info).group(1)) print(‘来源:‘ + re.search(‘来源:(.*)摄影:‘, info).group(1)) print(‘摄影:‘ + re.search(‘摄影:(.*)点击‘, info).group(1)) print(‘点击次数:‘ + getClickCount(a)) print(‘正文:‘+soupd.select(‘.show-content‘)[0].text) for news in soup.select(‘li‘): if len(news.select(‘.news-list-title‘))>0: title = news.select(‘.news-list-title‘)[0].text description = news.select(‘.news-list-description‘)[0].text a = news.a.attrs[‘href‘] getNewDetail(a) break
截图:
标签:ext 时间转换 beautiful 字符 datetime pre span img 爬取
原文地址:https://www.cnblogs.com/LauSir139/p/8747445.html