标签:class exists col standard 静态 sub 手册 and i++
Github项目地址:https://github.com/ahhahahh/WCPro
1、PSP表格
|
PSP2.1 |
PSP阶段 |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
30 |
30 |
|
Estimate |
估计任务需要多少时间 |
30 |
30 |
|
Development |
开发 |
400 |
450 |
|
Analysis |
需求分析 |
30 |
20 |
|
Design Spec |
生成设计文档 |
15 |
15 |
|
Design Review |
设计复审 |
30 |
30 |
|
Coding Standard |
代码规范 |
15 |
15 |
|
Design |
具体设计 |
30 |
40 |
|
Coding |
具体编码 |
150 |
200 |
|
Code Review |
代码复审 |
60 |
30 |
|
Test |
测试 |
60 |
80 |
|
Reporting |
报告 |
45 |
75 |
|
Test Report |
测试报告 |
30 |
50 |
|
Size Measurement |
计算工作量 |
20 |
25 |
|
Postmortem |
总结 |
30 |
45 |
|
|
合计 |
975 |
1136 |
2、代码和设计思路
由于我们组代码能力都有限,只做了基础功能,而且有很多功能在软工1504班成建伟的帮助下完成,在此特别感谢。
在接口设计中,首先设计一个count()函数,输入一个TXT文件名,读取文件,将文件中的大写先改写成小写,通过split()函数将字符进行划分,然后进行单词统计,将统计结果返回到HashMap<String, Integer>函数中。
设计的接口为:
public static HashMap<String, Integer> count(String thefile)
部分代码:此处部分代码有引用
// 划分统计单词数 public static HashMap<String, Integer> count(String thefile) { File file = new File(thefile); HashMap<String, Integer> map = new HashMap<String, Integer>(); if (file.exists()) { try { FileInputStream fis = new FileInputStream(file); InputStreamReader isr = new InputStreamReader(fis, "UTF-8"); BufferedReader br = new BufferedReader(isr); String line = ""; StringBuffer sb = new StringBuffer(); while ((line = br.readLine()) != null) { // 转为小写 line = line.toLowerCase(); int k = 0; // 去除行首的非字母单词 char first = line.charAt(k); while (!((first >= ‘a‘ && first <= ‘z‘) || first == ‘-‘)) { k++; first = line.charAt(k); } line = line.substring(k); // 去除多个空格\\s+ String[] split = line .split("\\s++|0|1|2|3|4|5|6|7|8|9|\\_|\\‘|\\.|\\,|\\;|\\(|\\)|\\~|\\!|" + "\\@|\\#|\\$|\\%|\\&|\\*|\\?|\"" + "|\\[|\\]|\\<|\\>|\\=|\\+|\\*|\\/|\\{|\\}|\\:|\\||\\^|\\`"); for (int i = 0; i < split.length; i++) { // 获取到每一个单词 Integer integer = map.get(split[i]); // 考虑末尾为-的单词或开头为--- if ((split[i].endsWith("-") || split[i].startsWith("-")) && !(split[i].equals("-"))) { // 去除多个空格\\s+ String[] sp = split[i].split("\\s++|\\-"); // 全部为---- if (sp.length == 0) { split[i] = "-"; integer = map.get(split[i]); } // 处理--dan else if (split[i].startsWith("-")) { int j = 0; char si = split[i].charAt(0); while (split[i].charAt(j) == si) j++; split[i] = split[i].substring(j); integer = map.get(split[i]); } // 去除多个空格\\s+ sp = split[i].split("\\s+|\\-"); // 全部为---- if (sp.length == 0) { split[i] = "-"; integer = map.get(split[i]); } // 处理dn-dan--- else { String tmp = sp[0]; for (int j = 1; j < sp.length; j++) { tmp = tmp + "-" + sp[j]; } split[i] = tmp; integer = map.get(split[i]); } } if (!split[i].equals("") && !split[i].equals("-")) { // 如果这个单词在map中没有,赋值1 if (null == integer) { map.put(split[i], 1); } else { // 如果有,在原来的个数上加上一 map.put(split[i], ++integer); } } } } //sb.append(line); br.close(); isr.close(); fis.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } else { System.out.print("文件不存在\n"); } return map; }
3、测试设计
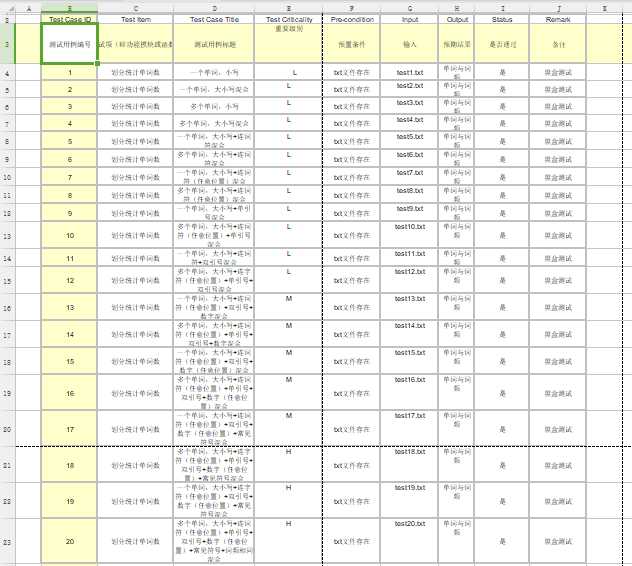
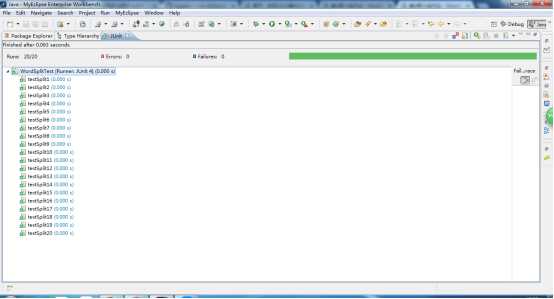
测试分析:随着单元测试的数据结构不断变复杂,用例都正常通过,能正确划分单词,统计次数。
4、小组贡献:
本次实验是接着上次实验进行的,由于我们组代码能力都比较弱,我承担了较多代码,不过还有很多地方是请教大佬完成,贡献率为0.4.
5、静态测试:
《阿里巴巴Java开发手册》中指出:
【强制】类名使用UpperCamelCase风格,必须遵从驼峰形式,但以下情形例外:(领域模型的相关命名)DO / DTO / VO / DAO等。
正例:
MarcoPolo / UserDO / XmlService / TcpUdpDeal / TaPromotion
反例:
macroPolo / UserDo / XMLService / TCPUDPDeal / TAPromotion
明确的命名可以减少歧义,明确的看出各变量的意义,便于字段意义的识别,具有统一性!我负责的是接口和单词识别部分,仔细审查后 ,确认符合《阿里巴巴Java开发手册》的强制规定。
6、交叉评审:17116代码
①代码缩进不够规范。
②"{"和"}"的使用不够规范,每个大括号没有另起。
③删减修改造成的冗余空白行。
④不规范的空格使用。
良好的代码习惯有利于提高效率,这部分代码还有很大的问题,通过评审他人代码也使自己有了很多思考,以后会更加注意。
7、小结:
由于时间和能力的有限,我们没有完成附加题和高级功能,不过这次从编码,测试,软件质量的分析,我名明白了要完成一个质量高的软件,必须完成每一步都认真完成,测试是关键,能发现很多问题,但也不能依赖测试,自己平时也要注意开发规范。
7、参考文献:
Java中split的用法:http://blog.csdn.net/tw19811220/article/details/41040937
标签:class exists col standard 静态 sub 手册 and i++
原文地址:https://www.cnblogs.com/DoubleNing/p/8746648.html