标签:理解 img 现在 研究 梯度下降法 优化参数 个人 代码 关注
????机器是什么,机器就是电脑、芯片、代码这些东西。让电脑遵循人的指令,完成一件特定的任务从计算机发明那天开始就在研究了,现在的各种编程语言、数据结构和编程算法等都是在做这个。但是它们只能依赖于程序员输入的确定的代码才能 work,也就是说他们不能“自己学习”,这样对于有些问题就很尴尬,比如检测一张图片中有几个人,识别一句话中提到了几个人名,识别一张图片是不是黄图等等。这些任务要是写一个代码,依靠规则去实现,那还是非常困难。但是我们可以换个思路,让我们写代码去实现这些功能很困难,但是让我们去给图片打标签(比如给一批图,人为的打上是不是黄图的标签…)不是很简单的嘛,我们如果能让机器自己从打好标签的图片中自己学习那些是黄图不就万事大吉了嘛。这样看的话,标注的工作就对应了传统写代码中写规则匹配的工作。
????那么有了标注好的图片,怎么让程序学习呢?这一步就需要借助于万能的数学了。如果我们能构造一个拟合函数,这个拟合函数可以拟合训练集,比如这里就是给函数输入各个图片的像素 RGB 值,输出就是是不是黄图。拟合完了之后给定一张没见过的图片也就能用这个函数得到是不是黄图了。
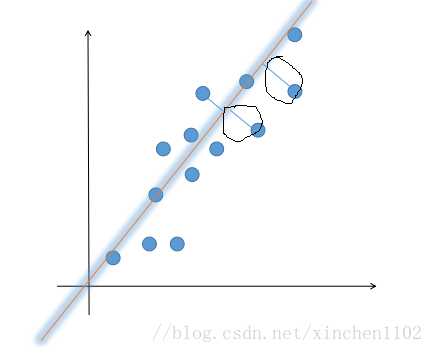
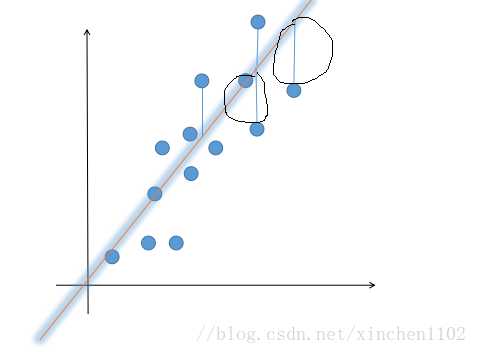
????那么具体是怎么实现这个思路的呢?想一想最小二乘法的做法。举个例子,比如有 100 个点\((x_{0},y_{0}),...,(x_{100},y_{100})\),我们想用一条直线去拟合它。首先直线的方程就是 \(y = ax+b\), 其实这里我们只要求出 a 和 b 就行了,a 和 b 的选择有无数多种,我们要选一种最好的。没有量化就没有优化,我们首先要把 “最好的” 这个标准进行量化,在数学上就是选一个目标函数,比较好的一个目标函数就是让每个点到 y 的距离之和最小(图上画圈部分就是每个点的误差,目标就是让每个点的误差加起来最小)。
????对机器学习感兴趣的新手或者大牛,如果有觉得对别人有帮助的,高质量的网页,大家可以通过 chrome 插件分享给其他人,在这里安装分享插件。
标签:理解 img 现在 研究 梯度下降法 优化参数 个人 代码 关注
原文地址:https://www.cnblogs.com/xinchen1111/p/8763213.html