标签:多个 资源 通过 oop ace hdfs not 建模 lock
简单的说就是开源框架.hadoop不是数据库,但是hadoop有数据库,有nosql数据库。apache的开源项目,主要用于做分布式、可靠性的、稳定的计算框架。
解决的问题:
hadoop擅长日志分析,facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析;淘宝搜索中的自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn 上用于发现您可能认识的人,可以实现类似Amazon.com的协同过滤的推荐效果。淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。(2012年8月25新更新,天猫的推荐系统是hive,少量尝试mahout!)
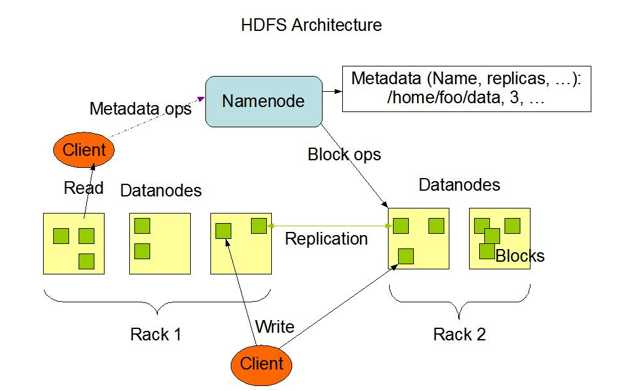
主从结构
主节点, namenode
从节点,有很多个: datanode
namenode负责:
接收用户操作请求
维护文件系统的目录结构
管理文件与block之间关系,block与datanode之间关系
datanode负责:
存储文件
文件被分成block存储在磁盘上
为保证数据安全,文件会有多个副本
扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
可靠性(Reliable):hadoop能自动地维护数据的多份副本,并且在任务失败后能自动地重新部署(redeploy)计算任务。
标签:多个 资源 通过 oop ace hdfs not 建模 lock
原文地址:https://www.cnblogs.com/qlqwjy/p/8777967.html