- 一:所需安装配置包
- 二:CentOS6.4x64 主机名配置
- 三:journalnode 配置zookeeper 安装
- 四:在namenode节点上部署hadoop 2.5.2
- 五:hadoop 集群的测试:
系统:CentOS 6.4 X64
软件:Hadoop-2.5.2.tar.gz
native-2.5.2.tar.gz
zookeeper-3.4.6.tar.gz
jdk-7u67-linux-x64.tar.gz
将所有软件安装上传到/home/hadoop/yangyang/ 下面 vim /etc/hosts (五台虚拟机全部配置)
192.168.3.1 namenode1.hadoop.com
192.168.3.2 namenode2.hadoop.com
192.168.3.3 journalnode1.hadoop.com
192.168.3.4 journalnode2.hadoop.com
192.168.3.5 journalnode3.hadoop.com角色分配表:
所有服务器均配置-------------
ssh-keygen ----------------一直到最后:
每台机器会生成一个id_rsa.pub 文件,
将所有的密钥生成导入一个authorized_keys文件里面
cat id.rsa.pub >> authorized_keys
然后从新分发到每台服务器的 .ssh/目录下面。
最后进行测试。所有服务器均配置。
安装jdk
tar -zxvf jdk-7u67-linux-x64.tar.gz
mv jdk-7u67-linux-x64 jdk
环境变量配置
vim .bash_profile
到最后加上:export JAVA_HOME=/home/hadoop/yangyang/jdk
export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/home/hadoop/yangyang/hadoop
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:${HADOOP_HOME}/bin
等所有软件安装部署完毕在进行:
source .bash_profile
java –version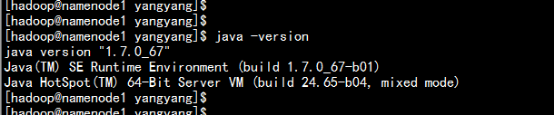
以 namenode1.hadoop.com 配置 作为NTP SERVER, 其它节点同步NTP 配置:
Namenode1.hadoop.com去网上同步时间
echo “ntpdate –u 202.112.10.36 ” >> /etc/rc.d/rc.local
#加入到开机自启动
vim /etc/ntp.conf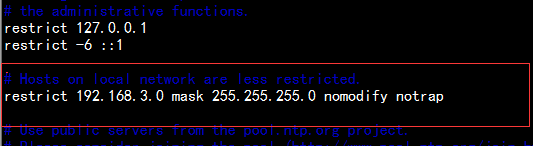
取消下面两行的#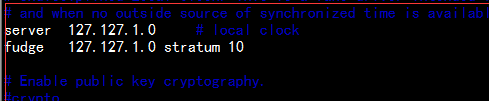
#vim /etc/sysconfig/ntpd
增加: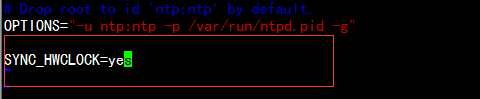
#service ntpd restart
#chkconfig ntpd on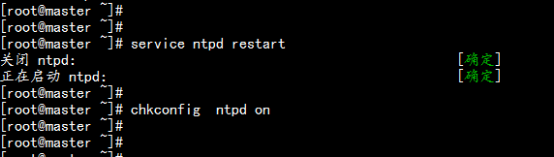
其它节点 配置计划任务处理将从namenode1.hadoop.com 同步时间
crontab –e
*/10 * * * * /usr/sbin/ntpdate namnode1.hadoop.comNamenode2.hadoop.com 
Journalnode1.hadoop.com
Jornalnode2.hadoop.com
Journalndoe3.hadoop.com
mv zookeeper-3.4.6 /home/hadoop/yangyang/zookeeper
cd /home/yangyang/hadoop/zookeeper/conf
cp -p zoo_sample.cfg zoo.cfg
vim zoo.cfg
更改dataDir 目录
dataDir=/home/hadoop/yangyang/zookeeper/data
配置journal主机的
server.1=journalnode1.hadoop.com:2888:3888
server.2=journalnode2.hadoop.com:2888:3888
server.3=journalnode3.hadoop.com:2888:3888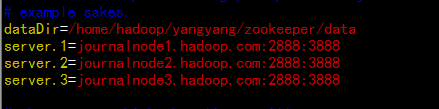
mkdir /home/hadoop/yangyang/zookeeper/data
echo “1” > /home/hadoop/yangyang/zookeeper/myid
cd /home/hadoop/yangyang/
scp –r zookeeper hadoop@journalnode2.hadoop.com:/home/hadoop/yangyang/
scp –r zookeeper hadoop@journalnode3.hadoop.com:/home/hadoop/yangyang/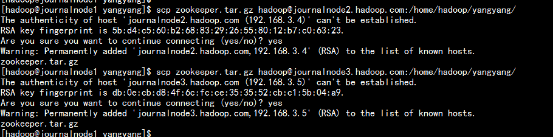
Journalnode2.hadoop.com :
echo “2” > /home/hadoop/yangyang/zookeeper/data/myid
Journalnode3.hadoop.com:
echo “3” > /home/hadoop/yangyang/zookeeper/myid
- 3.4 所有journalnode 节点启动zookeeper。
cd /home/hadoop/yangyang/zookeeper/bin
./zkServer.sh?start
---------------------显示以下内容为正常---------------------------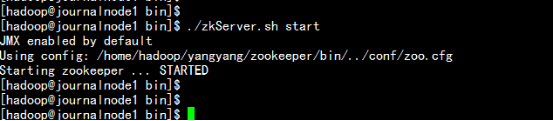
tar –zxvf hadoop-2.5.2.tar.gz
mv hadoop-2.5.2 /home/hadoop/yangyang/hadoop/cd /home/hadoop/yangyang/hadoop/
vim etc/hadoop/hadoop-env.sh
增加jdk 的环境变量export JAVA_HOME=/home/hadoop/yangyang/jdk
export HADOOP_PID_DIR=/home/hadoop/yangyang/hadoop/data/tmp
export HADOOP_SECURE_DN_PID_DIR=/home/hadoop/yangyang/hadoop/data/tmpvim etc/hadoop/mapred-env.sh
增加jdk 的环境
export JAVA_HOME=/home/hadoop/yangyang/jdk
export HADOOP_MAPRED_PID_DIR=/home/hadoop/yangyang/hadoop/data/tmp
vim etc/hadoop/yarn-env.sh
export JAVA_HOME=/home/hadoop/yangyang/jdkvim etc/hadoop/core-site.xml
<configuration>
<!--?指定hdfs的nameservice为mycluster?-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--?指定hadoop临时目录?-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/yangyang/hadoop/data/tmp</value>
</property>
<!--?指定zookeeper地址?-->
<property>
<name>ha.zookeeper.quorum</name>
<value>journalnode1.hadoop.com:2181,journalnode2.hadoop.com:2181,journalnode3.hadoop.com:2181</value>
</property>
</configuration> vim etc/hadoop/hdfs-site.xml
<configuration>
<!--指定hdfs的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致?-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--?masters下面有两个NameNode,分别是nn1,nn2?-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!—nn1的RPC通信地址?-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>namenode1.hadoop.com:8020</value>
</property>
<!--?nn1的http通信地址?-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>namenode1.hadoop.com:50070</value>
</property>
<!--?nn2的RPC通信地址?-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>namenode2.hadoop.com:8020</value>
</property>
<!--?nn2的http通信地址?-->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>namenode2.hadoop.com:50070</value>
</property>
<!--?指定NameNode的元数据在JournalNode上的存放位置?-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://journalnode1.hadoop.com:8485;journalnode2.hadoop.com:8485;journalnode3.hadoop.com:8485/mycluster</value>
</property>
<!--?指定JournalNode在本地磁盘存放数据的位置?-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/yangyang/hadoop/data/jn</value>
</property>
<!--?开启NameNode失败自动切换?-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--?配置失败自动切换实现方式?-->
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--?配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!--?使用sshfence隔离机制时需要ssh免登陆?-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!--?配置sshfence隔离机制超时时间?-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>vim etc/hadoop/mapred-site.xml
<configuration>
<!--?指定mr框架为yarn方式?-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--?指定HDFS的日志聚合功能?-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>journalnode3.hadoop.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>journalnode3.hadoop.com:19888</value>
</property>
</configuration>vim etc/hadoop/yarn-site.xml
<configuration>
<!--?开启RM高可靠?-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--?指定RM的cluster?id?-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_HA_ID</value>
</property>
<!--?指定RM的名字?-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--?分别指定RM的地址?-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>namenode1.hadoop.com</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>namenode2.hadoop.com</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!--?指定zk集群地址?-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>journalnode1.hadoop.com:2181,journalnode2.hadoop.com:2181,journalnode3.hadoop.com:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>rm -rf lib/native/*
tar –zxvf hadoop-native-2.5.2.tar.gz –C hadoop/lib/native
cd hadoop/lib/native/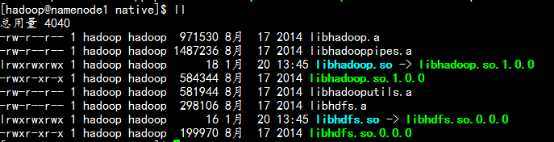
vim etc/hadoop/slaves
journalnode1.hadoop.com
journalnode2.hadoop.com
journalnode3.hadoop.comcd /home/hadoop/yangyang/
scp –r hadoop hadoop@namenode2.hadoop.com:/home/hadoop/yangyang/
scp –r hadoop hadoop@journalnode1.hadoop.com:/home/hadoop/yangyang/
scp –r hadoop hadoop@journalnode2.hadoop.com:/home/hadoop/yangyang/
scp –r hadoop hadoop@journalnode3.hadoop.com:/home/hadoop/yangyang/ cd /home/hadoop/yangyang/hadoop/sbin
./ hadoop-daemon.sh?start?journalnode
---------------------------显示内容-------------------------- 
cd /home/hadoop/yangyang/hadoop/bin
./hdfs?namenode?–format
![17.png-101.7kB][17]
将namenode1上生成的data文件夹复制到namenode2的相同目录下
scp? -r? hadoop/data/? hadoop@namenode2.hadoop.com:/home/hadoop/yangyang/hadoop
cd /home/hadoop/yangyang/hadoop/bin
./ hdfs?zkfc?–formatZK
###4.12 启动hdfs 与yarn 服务:
./start-dfs.sh
./ start-yarn.sh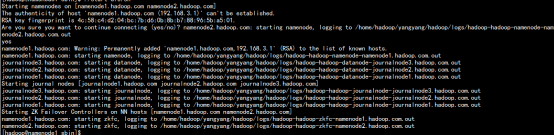
cd /home/hadoop/yangyang/hadoop/sbin
./yarn-daemon.sh start resourcemanager查看namenode
http://namenode1.hadoop.com:50070/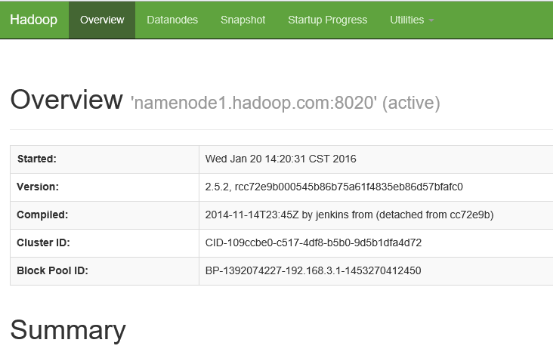
http://namenode2.hadoop.com:50070/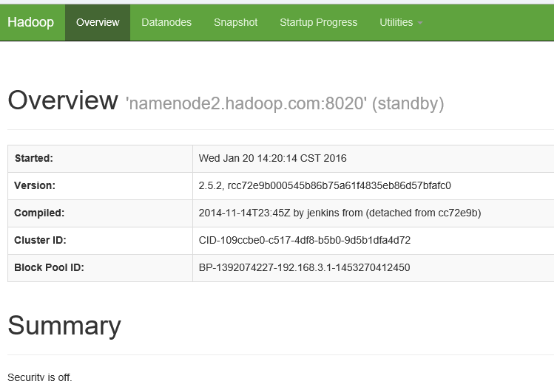
查看resourcemanger
http://namenode1.hadoop.com:8088/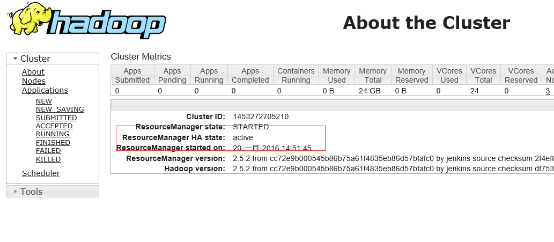
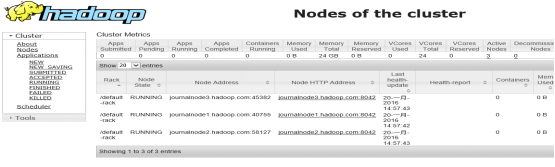
http://namenode2.hadoop.com:8088/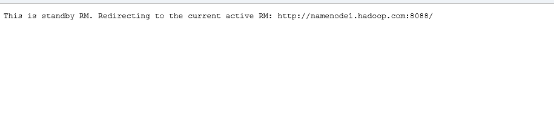
cd /home/hadoop/yangyang/hadoop/sbin/
./mr-jobhistory-daemon.sh start historyserver
杀掉namenode1.haoop.com 上的namenode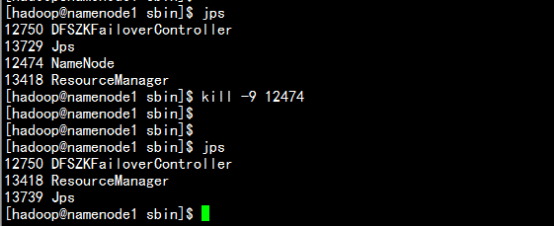
namenode2.haoop.com 的stundby 则切换为active状态。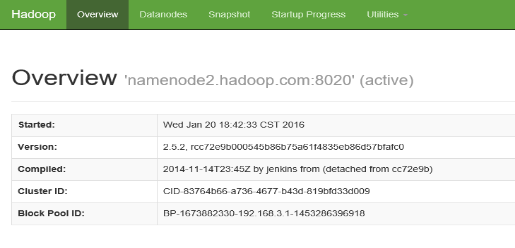
启动namenode1.hadoop.com 的namenode 节点
cd /home/hadoop/yangyang/hadoop/sbin/
./hadoop-daemon.sh start namenode
打开namenode1.hadoop.com 的浏览器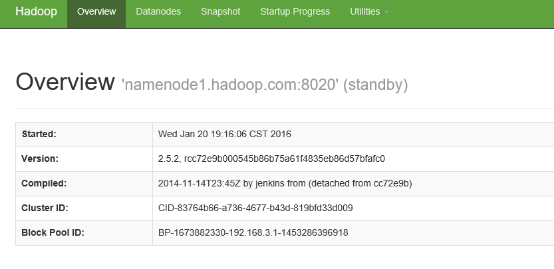
hadoop fs –mkdir /input
hadoop fs –put file1 /input/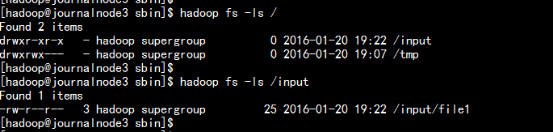
在运行wordcount 时 杀掉 namenode1.hadoop.com 的resourcemanager
运行wordcount
cd /home/hadoop/yangyang/hadoop/share/hadoop/mapreduce
yarn jar hadoop-mapreduce-examples-2.5.2.jar wordcount /input/file1 /output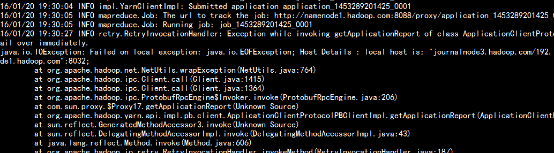
杀掉namenode1.hadoop.com 上的rescourcemanager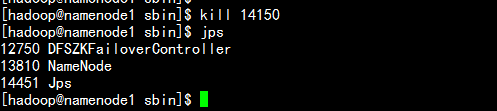
Namenode2.hadoop.com 的yarn 切换为actvie 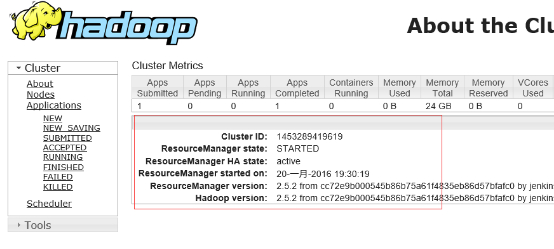
Wordcount 运行执行结束: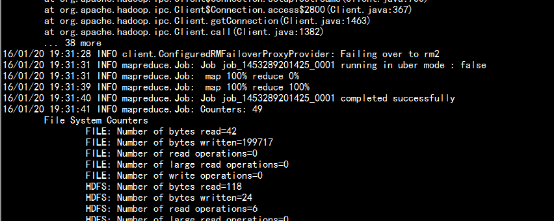
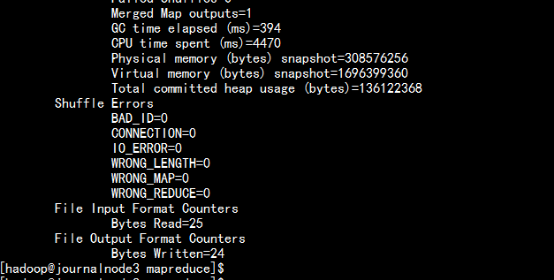
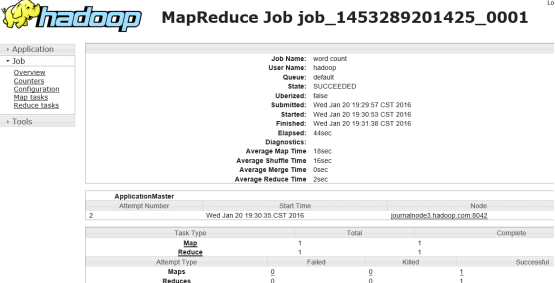
查看jobhistory 页面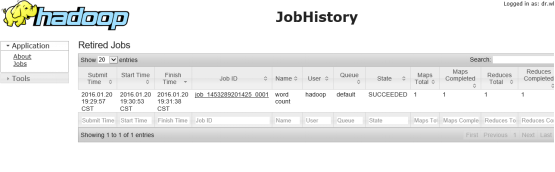
Hadoop 2.5.2 HDFS HA+YARN HA 应用配置
原文地址:http://blog.51cto.com/flyfish225/2096436