标签:分类器 多个 算法 抽样 决策 问题 tar 采样 指标
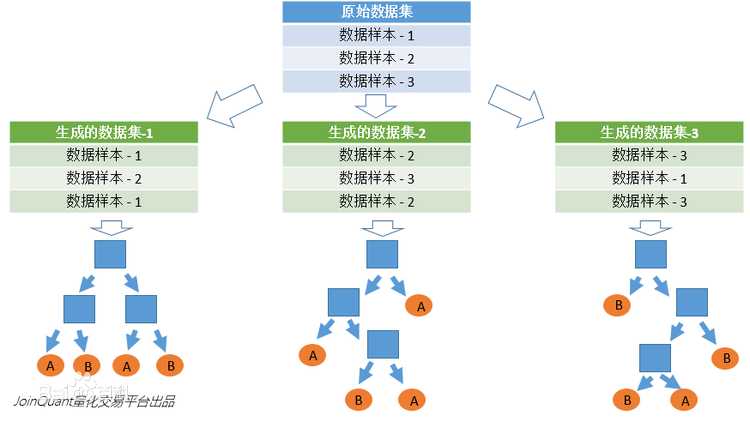
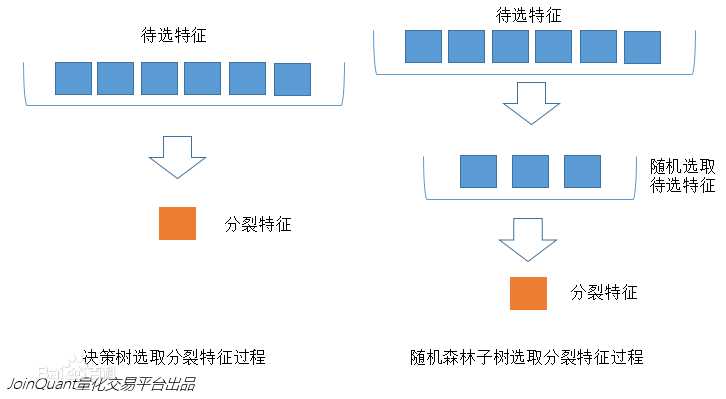
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
编辑
转载自网络、百科等
随机森林
原文地址:https://www.cnblogs.com/1023linlin/p/8782608.html