标签:open 发布 表达式 lis print php OAO odi count
学会使用正则表达式
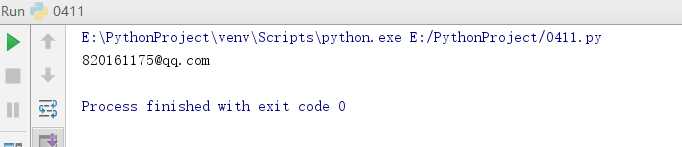
1. 用正则表达式判定邮箱是否输入正确。
import re
rule = ‘^\w+@\w+.\w+‘
mail = ‘820161175@qq.com‘
rec = re.match(rule, mail)
if(rec):
print(rec.group(0))
else:
print(‘error‘)
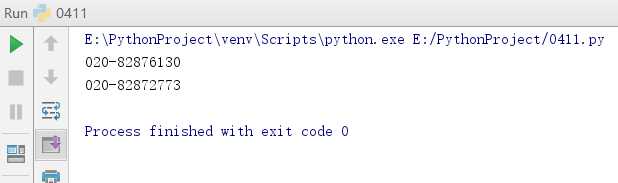
2. 用正则表达式识别出全部电话号码。
t = ‘‘‘学校办公室:020-82876130 招生电话:020-82872773
粤公网安备 44011602000060号 粤ICP备15103669号‘‘‘
rule = ‘\d{3}-\d{6,8}‘
rec = re.findall(rule, t)
if (rec):
for i in rec:
print(i)
else:
print(‘error‘)
3. 用正则表达式进行英文分词。re.split(‘‘,news)
news=‘‘‘President Xi Jinping at the opening-ceremoy of?the Boao Forum for Asia Annual Conference 2018 on Tuseday ‘‘‘ print(re.split((‘[\s,.?\-]+‘),news))

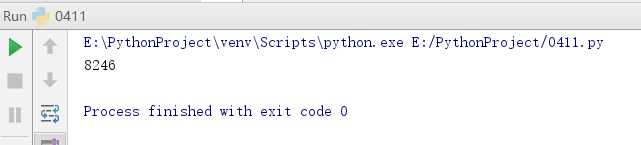
4. 使用正则表达式取得新闻编号
newsUrl=‘http://news.gzcc.cn/html/2017/xiaoyuanxinwen_0925/8246.html‘ s=re.search(‘\_(.*).html‘,newsUrl).group(1).split(‘/‘)[1] print(s)
5. 生成点击次数的Request URL
res = requests.get(‘http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80‘.format(s))
6. 获取点击次数
r = ‘http://news.gzcc.cn/html/2017/xiaoyuanxinwen_0925/8246.html‘
s = re.findall(‘\_(.*).html‘, r)[0].split(‘/‘)[-1]
res = requests.get(‘http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80‘.format(s))
return int(res.text.split(‘.html‘)[-1].lstrip("(‘").rstrip("‘);"))
7. 将456步骤定义成一个函数 def getClickCount(newsUrl):
def getClickCount(r):
s = re.findall(‘\_(.*).html‘, r)[0].split(‘/‘)[-1]
res = requests.get(‘http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80‘.format(s))
return int(res.text.split(‘.html‘)[-1].lstrip("(‘").rstrip("‘);"))
8. 将获取新闻详情的代码定义成一个函数 def getNewDetail(newsUrl):
def getNewsDetail(newsUrl):
resd = requests.get(newsUrl)
resd.encoding = ‘utf-8‘
soupd = BeautifulSoup(resd.text, ‘html.parser‘)
title=soupd.select(‘.show-title‘)[0].text
info=soupd.select(‘.show-info‘)[0].text
ti=datetime.strptime(info.lstrip(‘发布时间:‘)[0:19], ‘%Y-%m-%d %H:%M:%S‘)
if info.find(‘来源:‘)>0:
source=info[info.find(‘来源:‘):].split()[0].lstrip(‘来源:‘)
else:
source=‘none‘
click=getClickCount(newsUrl)
print(ti,title,source,click)
9. 取出一个新闻列表页的全部新闻 包装成函数def getListPage(pageUrl):
def getListPage(pageUrl): #9. 取出一个新闻列表页的全部新闻 包装成函数def getListPage(pageUrl)
res = requests.get(pageUrl)
res.encoding = ‘utf-8‘
soup = BeautifulSoup(res.text, ‘html.parser‘)
for news in soup.select(‘li‘):
if len(news.select(‘.news-list-title‘)) > 0:
g = news.select(‘a‘)[0].attrs[‘href‘]
print(g)
getNewsDetail(g)
10. 获取总的新闻篇数,算出新闻总页数包装成函数def getPageN():
def getPageN():
res = requests.get(‘http://news.gzcc.cn/html/xiaoyuanxinwen/‘)
res.encoding = ‘utf-8‘
soup = BeautifulSoup(res.text, ‘html.parser‘)
pagenumber=int(soup.select(‘.a1‘)[0].text.rstrip(‘条‘))
page = pagenumber//10+1
return page
11. 获取全部新闻列表页的全部新闻详情。
pageUrl=‘http://news.gzcc.cn/html/xiaoyuanxinwen/‘
n=getPageN()
for i in range(1,n+1):
print(i)
listPageUrl=‘http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html‘.format(i)
getListPage(listPageUrl)

标签:open 发布 表达式 lis print php OAO odi count
原文地址:https://www.cnblogs.com/H231/p/8780749.html