标签:key 包装 爬取 open 不能 else jieba split count
1.取出一个新闻列表页的全部新闻 包装成函数。
2.获取总的新闻篇数,算出新闻总页数。
3.获取全部新闻列表页的全部新闻详情。
import requests from bs4 import BeautifulSoup from datetime import datetime import locale import re locale.setlocale(locale.LC_CTYPE,‘chinese‘) def getClickCount(newsUrl): newsId = re.findall(‘\_(.*).html‘, newsUrl)[0].split(‘/‘)[1] #使用正则表达式取得新闻编号 clickUrl = ‘http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80‘.format(newsId) clickStr = requests.get(clickUrl).text return(re.search("hits‘\).html\(‘(.*)‘\);",clickStr).group(1)) def getNewsContent(content): f = open(‘gzccNews.txt‘,‘a‘,encoding=‘utf8‘) f.write(content) f.close() def getNewDetail(newsUrl): resd = requests.get(newsUrl) # 返回response resd.encoding = ‘utf-8‘ soupd = BeautifulSoup(resd.text, ‘html.parser‘) print(‘标题:‘ + soupd.select(‘.show-title‘)[0].text) print(‘链接:‘+newsUrl) newsUrl = newsUrl info = soupd.select(‘.show-info‘)[0].text time = re.search(‘发布时间:(.*) \xa0\xa0 \xa0\xa0作者:‘, info).group(1) dtime = datetime.strptime(time, ‘%Y-%m-%d %H:%M:%S‘) if info.find(‘作者:‘) > 0: author = info[info.find(‘作者:‘):].split()[0].lstrip(‘作者:‘) else: author = ‘无‘ if info.find(‘审核:‘) > 0: check = info[info.find(‘审核:‘):].split()[0].lstrip(‘审核:‘) else: check = ‘无‘ if info.find(‘来源:‘) > 0: source = info[info.find(‘来源:‘):].split()[0].lstrip(‘来源:‘) else: sourec = ‘无‘ if info.find(‘摄影:‘) > 0: photo = info[info.find(‘摄影:‘):].split()[0].lstrip(‘摄影:‘) else: photo = ‘无‘ print(‘发布时间:{}\n作者:{}\n审核:{}\n来源:{}\n摄影:{}‘.format(dtime,author,check,source,photo)) clickCount = getClickCount(newsUrl) print(‘点击次数:‘ + clickCount) content = soupd.select(‘.show-content‘)[0].text getNewsContent(content) # print(content) def getLiUrl(ListPageUrl): res = requests.get(ListPageUrl) res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text,‘html.parser‘) # print(soup.select(‘li‘)) for news in soup.select(‘li‘): if len(news.select(‘.news-list-title‘))>0: a = news.a.attrs[‘href‘] getNewDetail(a) break firstUrl = ‘http://news.gzcc.cn/html/xiaoyuanxinwen/‘ print(‘第1页:‘) # getLiUrl(firstUrl) res = requests.get(firstUrl) res.encoding = ‘utf-8‘ soupn = BeautifulSoup(res.text,‘html.parser‘) n = int(soupn.select(‘.a1‘)[0].text.rstrip(‘条‘))//10+1 for i in range(2,n): pageUrl = ‘http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html‘.format(i) print(‘第{}页:‘.format(i)) getLiUrl(pageUrl) break
结果截图:

4.找一个自己感兴趣的主题,进行数据爬取,并进行分词分析。不能与其它同学雷同。
import requests,jieba,locale from bs4 import BeautifulSoup locale.setlocale(locale.LC_CTYPE,‘chinese‘) def getKeyWords(text): str = ‘‘‘一!“”,。?、;’"‘,.、\t:\n‘‘‘ for s in str: text = text.replace(s, ‘‘) wordlist = list(jieba.cut(text)) exclude = {‘是‘,‘的‘,‘在‘,‘了‘,‘个‘,‘和‘,‘说‘,} wordset = set(wordlist) - exclude dict = {} keywords = [] for key in wordset: dict[key] = wordlist.count(key) dictlist = list(dict.items()) dictlist.sort(key=lambda x: x[1], reverse=True) for i in range(5): keywords.append(dictlist[i][0]) return keywords def getNewDetail(newsUrl): resd = requests.get(newsUrl) # 返回response resd.encoding = ‘gbk‘ soupd = BeautifulSoup(resd.text, ‘html.parser‘) print(‘链接:‘ + newsUrl) print(‘标题:‘ + soupd.select(‘h1‘)[0].text) content = soupd.select(‘.box_con‘)[0].text keywords = getKeyWords(content) print(‘关键词:{}、{}、{}‘.format(keywords[0], keywords[1], keywords[2])) tands = soupd.select(‘.box01‘)[0].text print(‘日期:‘+tands.split()[0]) print(tands.split()[1]) print(soupd.select(‘.edit‘)[0].text.lstrip(‘(‘).rstrip(‘)‘)) print(content) def getLiUrl(ListPageUrl): res = requests.get(ListPageUrl) res.encoding = ‘gbk‘ soupn = BeautifulSoup(res.text,‘html.parser‘) # print(soupn.select(‘li‘)) for news in soupn.select(‘.on‘): atail = news.a.attrs[‘href‘] a = ‘http://legal.people.com.cn/‘+atail getNewDetail(a) break Url = ‘http://legal.people.com.cn/‘ res = requests.get(Url) res.encoding = ‘gbk‘ soup = BeautifulSoup(res.text,‘html.parser‘) print(‘第1页:‘) getLiUrl(Url) for i in range(2,6): pageUrl = ‘http://legal.people.com.cn/index{}.html#fy01‘.format(i) print(‘第{}页:‘.format(i)) getLiUrl(pageUrl) break
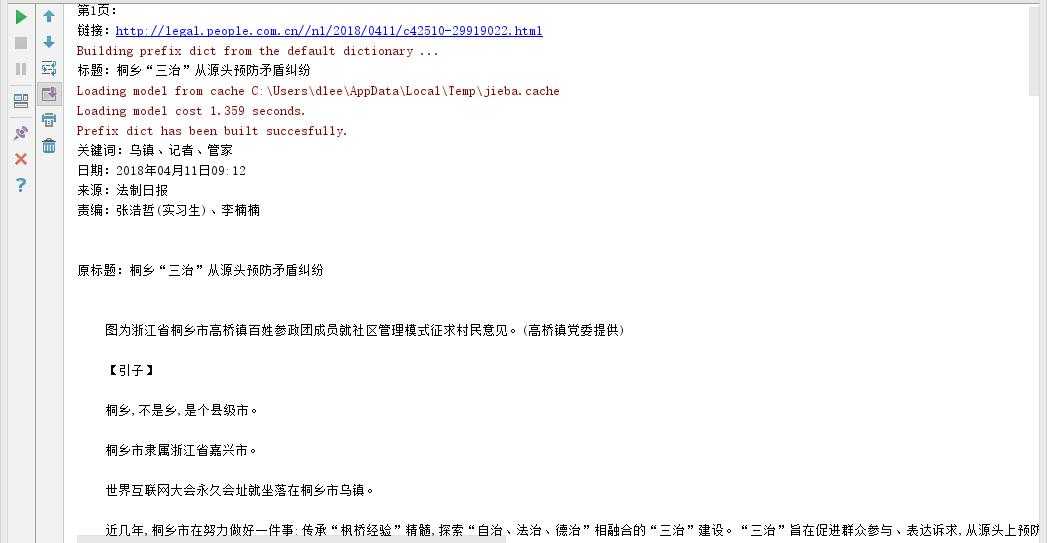
结果截图:

标签:key 包装 爬取 open 不能 else jieba split count
原文地址:https://www.cnblogs.com/stcy520/p/8795105.html