标签:dia code object query dict explicit erro 代码 att
:reqest.data取值的时候才执行
对请求的数据进行解析:是针对请求体进行解析的。表示服务器可以解析的数据格式的种类
django中的发送请求
#如果是这样的格式发送的数据,在POST里面有值 Content-Type: application/url-encoding..... request.body request.POST #如果是发送的json的格式,在POST里面是没有值的,在body里面有值,可通过decode,然后loads取值 Content-Type: application/json..... request.body request.POST
关于decode、encode 浏览器发送过来是字节需要先解码 ---> decode 如:s=‘中文‘ 如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。这种情况下,要进行编码转换,都需要先用 decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件。 如下: s.decode(‘utf-8‘).encode(‘utf-8‘) decode():是解码 --->把字节变成字符串 encode()是编码---->把字符串变成字节
django只解析两种形式
1:导入django的类 from django.core.handlers.wsgi import WSGIRequest 2: class WSGIRequest(http.HttpRequest): def _get_post(self): if not hasattr(self, ‘_post‘): self._load_post_and_files() return self._post 3: # self._load_post_and_files()从这里找到django解析的方法 def _load_post_and_files(self): """Populate self._post and self._files if the content-type is a form type""" if self.method != ‘POST‘: self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict() return if self._read_started and not hasattr(self, ‘_body‘): self._mark_post_parse_error() return if self.content_type == ‘multipart/form-data‘: if hasattr(self, ‘_body‘): # Use already read data data = BytesIO(self._body) else: data = self try: self._post, self._files = self.parse_file_upload(self.META, data) except MultiPartParserError: # An error occurred while parsing POST data. Since when # formatting the error the request handler might access # self.POST, set self._post and self._file to prevent # attempts to parse POST data again. # Mark that an error occurred. This allows self.__repr__ to # be explicit about it instead of simply representing an # empty POST self._mark_post_parse_error() raise elif self.content_type == ‘application/x-www-form-urlencoded‘: self._post, self._files = QueryDict(self.body, encoding=self._encoding), MultiValueDict() else: self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict() 从上面的 if self.content_type == ‘multipart/form-data‘:和 self.content_type == ‘application/x-www-form-urlencoded‘: 可以知道django只解析urlencoded‘和form-data这两种类型
传json数据默认为urlencoded这种解析
到request。body取原数据过来json数据时,django解析步骤---->需要我们自己操作
1:取到的数据是字节
需要先解码decode():是解码 --->把字节变成字符串
request。body。decode("utf8")
json.loads(request。body。decode("utf8"))
为了这种情况下每次都要decode,loads,显得麻烦,所以才有的解析器。弥补了django的缺点

客户端: Content-Type: application/json ‘{"name":"alex","age":123}‘ 服务端接收: 读取客户端发送的Content-Type的值 application/json parser_classes = [JSONParser,FormParser] #表示服务器可以解析的数据格式的种类 media_type_list = [‘application/json‘,‘application/x-www-form-urlencoded‘] 如果客户端的Content-Type的值和 application/json 匹配:JSONParser处理数据 如果客户端的Content-Type的值和 application/x-www-form-urlencoded 匹配:FormParser处理数据 配置: 单视图: class UsersView(APIView): parser_classes = [JSONParser,] 全局配置: REST_FRAMEWORK = { ‘VERSION_PARAM‘:‘version‘, ‘DEFAULT_VERSION‘:‘v1‘, ‘ALLOWED_VERSIONS‘:[‘v1‘,‘v2‘], # ‘DEFAULT_VERSIONING_CLASS‘:"rest_framework.versioning.HostNameVersioning" ‘DEFAULT_VERSIONING_CLASS‘:"rest_framework.versioning.URLPathVersioning", ‘DEFAULT_PARSER_CLASSES‘:[ ‘rest_framework.parsers.JSONParser‘, ‘rest_framework.parsers.FormParser‘, ] } class UserView(APIView): def get(self,request,*args,**kwargs): return Response(‘ok‘) def post(self,request,*args,**kwargs): print(request.data) #以后取值就在这里面去取值 return Response(‘...‘) 具体讲解
在rest-framework中 是以利用Request类进行数据解析
1:找到apiview class APIView(View): # The following policies may be set at either globally, or per-view. renderer_classes = api_settings.DEFAULT_RENDERER_CLASSES parser_classes = api_settings.DEFAULT_PARSER_CLASSES # 解析器 2:找api_settings没有定义找默认 renderer_classes = api_settings.DEFAULT_RENDERER_CLASSES 3:. api_settings = APISettings(None, DEFAULTS, IMPORT_STRINGS) 4:DEFAULTS DEFAULTS = { # Base API policies # 自带的解析器 ‘DEFAULT_PARSER_CLASSES‘: ( ‘rest_framework.parsers.JSONParser‘, # 解析json数据 ‘rest_framework.parsers.FormParser‘, # from数据 ‘rest_framework.parsers.MultiPartParser‘ # 多数据 ),
例如
# 利用rest-framework的解析器 from rest_framework.parsers import JSONParser, FormParser class PublishView(generics.ListCreateAPIView): parser_classes = [FormParser] # 自定义用哪些解析器来解析数据 queryset = Publish.objects.all() serializer_class = PublishSerializers
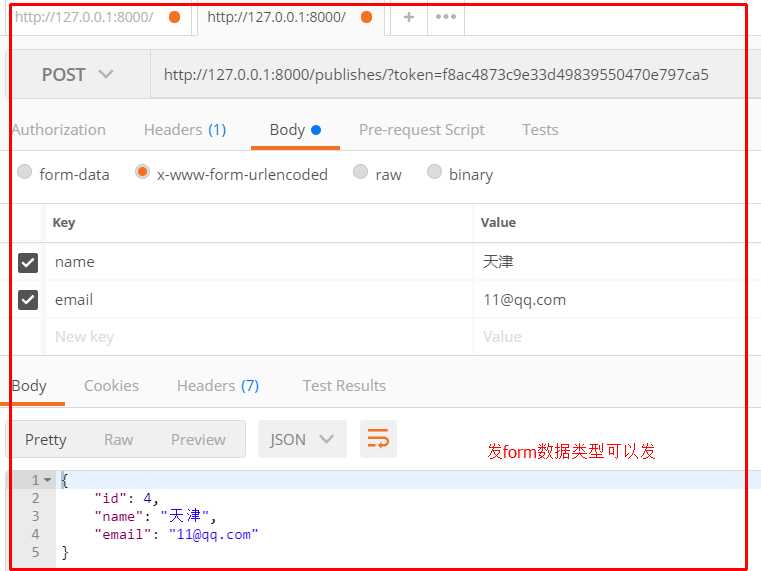
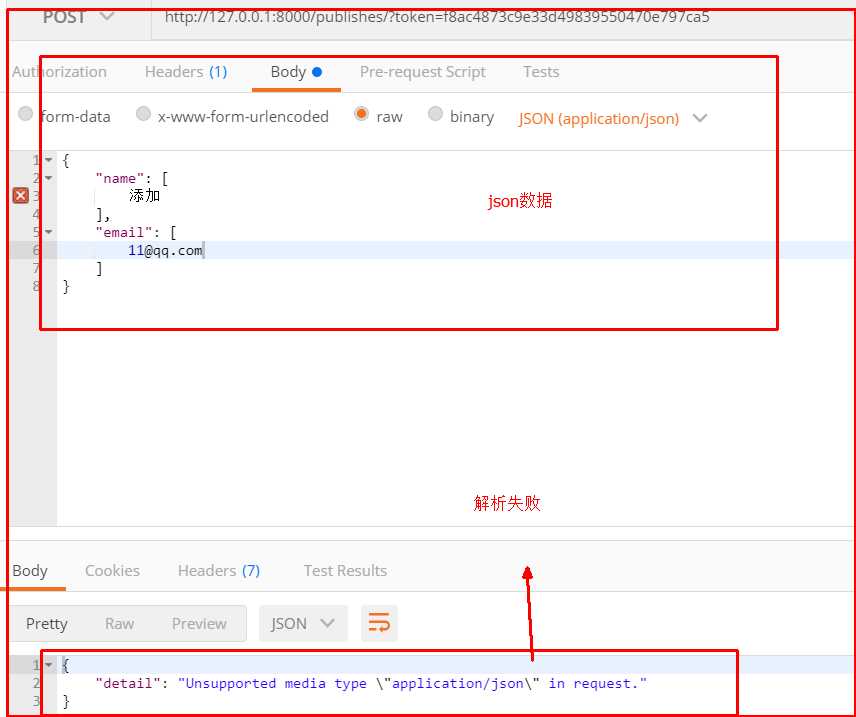
REST_FRAMEWORK={ "DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",], "DEFAULT_PERMISSION_CLASSES":["app01.service.permissions.SVIPPermission",], "DEFAULT_THROTTLE_CLASSES":["app01.service.throttles.VisitThrottle",], "DEFAULT_THROTTLE_RATES":{ "visit_rate":"5/m", }, "DEFAULT_PARSER_CLASSES":[‘rest_framework.parsers.FormParser‘,] }
试问如果当数据量特别大的时候,你是怎么解决分页的?
view。py: class PublishView(generics.ListCreateAPIView): # parser_classes = [FormParser] # 自定义用哪些解析器来解析数据 queryset = Publish.objects.all() serializer_class = PublishSerializers # 序列化 def get(self,request,*args,**kwargs): publish_list = Publish.objects.all() # 构建分页器对象 pnp = PageNumberPagination() # 分完页的数据 pager_pulisher = pnp.paginate_queryset(queryset=publish_list,request=request,view=self) print(pager_pulisher) ps = PublishSerializers(pager_pulisher,many=True) return Response(ps.data) setting: REST_FRAMEWORK={ "DEFAULT_AUTHENTICATION_CLASSES":["api.service.auth.MyAuthentication"], # 认证组件 "DEFAULT_PERMISSION_CLASSES":["api.service.permission.SVIPPermission"], # 权限组件 "DEFAULT_THROTTLE_CLASSES":["api.service.throttles.VisitThrottle"], # 频率组件 # SimpleRateThrottle "DEFAULT_THROTTLE_RATES":{ "visit_rate":"5/m," }, # 分页器参数 "PAGE_SIZE":2 #每页显示的数据 }
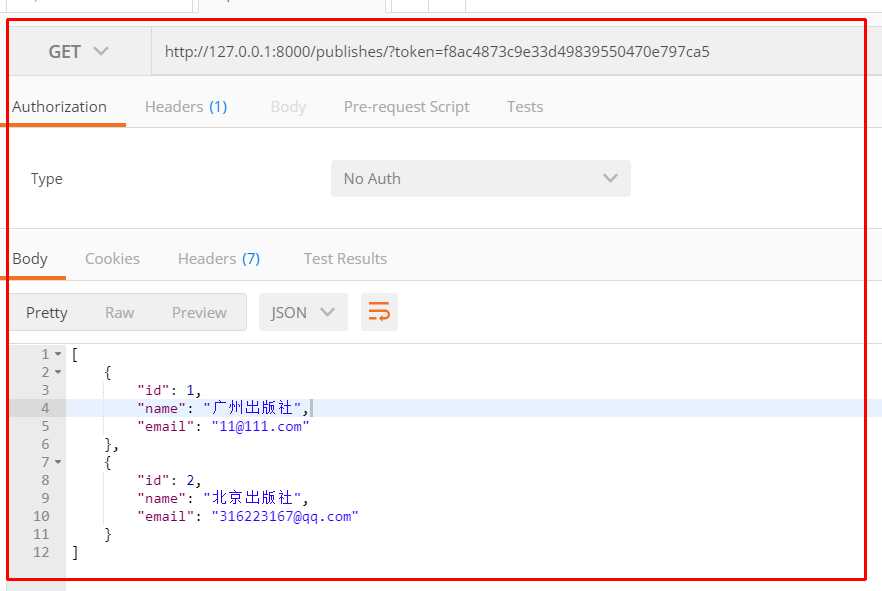
# 自定义局部分页 class MyPageNumberPagination(PageNumberPagination): page_size = 2 # 每页显示2条数据 page_query_param = "page_num" # http://127.0.0.1:8000/publishes/?page_num=2 size = 3 # 从参数控制每页显示几条数据 max_page_size = 5 # 最多显示5条数据 class PublishView(generics.ListCreateAPIView): # parser_classes = [FormParser] # 自定义用哪些解析器来解析数据 queryset = Publish.objects.all() serializer_class = PublishSerializers # 序列化 def get(self,request,*args,**kwargs): publish_list = Publish.objects.all() # 构建分页器对象 pnp = PageNumberPagination() # 分完页的数据 pager_pulisher = pnp.paginate_queryset(queryset=publish_list,request=request,view=self) print(pager_pulisher) ps = PublishSerializers(pager_pulisher,many=True) return Response(ps.data)
标签:dia code object query dict explicit erro 代码 att
原文地址:https://www.cnblogs.com/jassin-du/p/8798543.html
