标签:int alt 模块 excel 表格 mys key com 文档
具体项目在githut里面:
应用jieba库分词
1)利用jieba分词来统计词频:
对应文本为我们队伍的介绍:jianjie.txt:
项目名称:碎片
项目描述:制作一个网站,拾起日常碎片,记录生活点滴!
项目成员:孔潭活、何德新、吴淑瑶、苏咏梅
成员风采:
孔潭活:2015034643032
何德新:
学号:2015034643017
风格:咸鱼王
擅长技术:设计
编程兴趣:机器学习、人工智能。希望的软工角色:项目经理。
一句话宣言:持而盈之,不如其已。揣而锐之,不可常保。道可道非常道;名可名非常名
吴淑谣:
学号:2015034643018
风格:细水长流
擅长技术:无,对C++比较熟悉
编程兴趣:对数据进行处理和分析
希望的软工角色:代码能力比较薄弱,希望负责技术含量不是很高的模块
一句话宣言:推陈出新,永无止境。
苏咏梅:
学号:2015034643025
风格:越挫越勇
擅长技术:没有比较擅长的,对MySQL与Java感兴趣
希望的软工角色:需求分析员
一句话宣言:要成功,先发疯,头脑简单向前冲
课程目标
一个小而美记录生活碎片的网站
代码:
import jieba
import jieba.analyse
import xlwt #写入Excel表的库
if name == "main":
wbk = xlwt.Workbook(encoding=‘ascii‘)
sheet = wbk.add_sheet("wordCount") # Excel单元格名字
word_lst = []
key_list = []
for line in open(‘jianjie.txt‘): # jianjie.txt是需要分词统计的文档
item = line.strip(‘\n\r‘).split(‘\t‘) # 制表格切分
# print item
tags = jieba.analyse.extract_tags(item[0]) # jieba分词
for t in tags:
word_lst.append(t)
word_dict = {}
with open("wordCount.txt", ‘w‘) as wf2: # 打开文件
for item in word_lst:
if item not in word_dict: # 统计数量
word_dict[item] = 1
else:
word_dict[item] += 1
for item in word_lst:
if word_dict[item]==1:
del word_dict[item]
orderList = list(word_dict.values())
orderList.sort(reverse=True)
# print orderList
for i in range(len(orderList)):
for key in word_dict:
if word_dict[key] == orderList[i]:
wf2.write(key + ‘ ‘ + str(word_dict[key]) + ‘\n‘) # 写入txt文档
key_list.append(key)
word_dict[key] = 0
for i in range(len(key_list)):
sheet.write(i, 1, label=orderList[i])
sheet.write(i, 0, label=key_list[i])
wbk.save(‘wordCount.xls‘) # 保存为 wordCount.xls文件
?
2)统计的词频会输出两个文件一个是txt文件另外一个是xls文件名字都是wordCount
我们利用excel来绘图
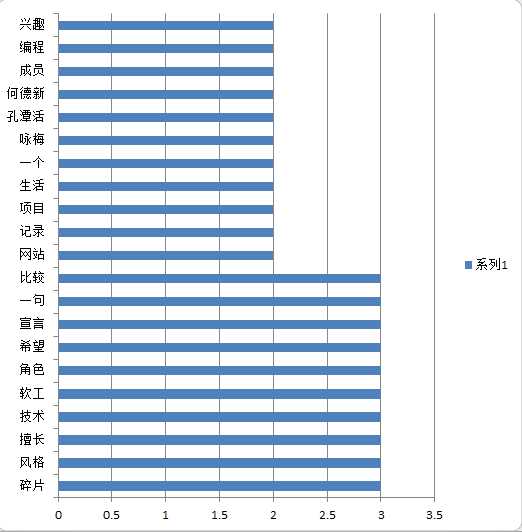
标签:int alt 模块 excel 表格 mys key com 文档
原文地址:https://www.cnblogs.com/milo-dd/p/8799143.html