标签:app src text 技术分享 opened lambda enc inf ==
我在下载的udacity中教程时,字幕和视频是分离的,对于英文还无法完全听懂的我来说,字幕还是比较重要.不想看解释的可直接跳到最后复制代码运行即可.
查看了vtt和srt的区别,使用记事本打开vtt和srt,发现主要有两个
流程图:
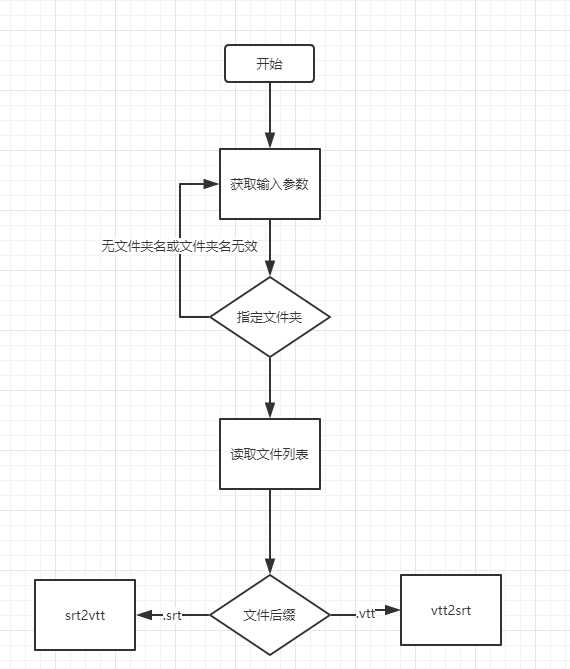
基于python写了一个简单的脚本对其进行批量修改
import os import sys import re
if __name__ == ‘__main__‘: args = sys.argv print(args) if os.path.isdir(args[1]): file_list = get_file_name(args[1], ".vtt") for file in file_list: vtt2srt(file) elif os.path.isfile(args[1]): vtt2srt(args[1]) else: print("arg[0] should be file name or dir")
def get_file_name(dir, file_extension): f_list = os.listdir(dir) result_list = [] for file_name in f_list: if os.path.splitext(file_name)[1] == file_extension: result_list.append(os.path.join(dir, file_name)) return result_list
def vtt2srt(file_name): content = open(file_name, "r", encoding="utf-8").read() # 删除WEBVTT行 content = re.sub("WEBVTT\n\n",‘‘,content) # 替换“.”为“,” content = re.sub("(\d{2}:\d{2}:\d{2}).(\d{3})", lambda m: m.group(1) + ‘,‘ + m.group(2), content) output_file = os.path.splitext(file_name)[0] + ‘.srt‘ open(output_file, "w", encoding="utf-8").write(content) def srt2vtt(file_name): content = open(file_name, "r", encoding="utf-8").read() # 添加WEBVTT行 content = "WEBVTT\n\n" + content # 替换“,”为“.” content = re.sub("(\d{2}:\d{2}:\d{2}),(\d{3})", lambda m: m.group(1) + ‘.‘ + m.group(2), content) output_file = os.path.splitext(file_name)[0] + ‘.vtt‘ open(output_file, "w", encoding="utf-8").write(content)

import os import sys import re def get_file_name(dir, file_extension): f_list = os.listdir(dir) result_list = [] for file_name in f_list: if os.path.splitext(file_name)[1] == file_extension: result_list.append(os.path.join(dir, file_name)) return result_list def vtt2srt(file_name): content = open(file_name, "r", encoding="utf-8").read() # 删除WEBVTT行 content = re.sub("WEBVTT\n\n",‘‘,content) # 替换“.”为“,” content = re.sub("(\d{2}:\d{2}:\d{2}).(\d{3})", lambda m: m.group(1) + ‘,‘ + m.group(2), content) output_file = os.path.splitext(file_name)[0] + ‘.srt‘ open(output_file, "w", encoding="utf-8").write(content) def srt2vtt(file_name): content = open(file_name, "r", encoding="utf-8").read() # 添加WEBVTT行 content = "WEBVTT\n\n" + content # 替换“,”为“.” content = re.sub("(\d{2}:\d{2}:\d{2}),(\d{3})", lambda m: m.group(1) + ‘.‘ + m.group(2), content) output_file = os.path.splitext(file_name)[0] + ‘.vtt‘ open(output_file, "w", encoding="utf-8").write(content) if __name__ == ‘__main__‘: args = sys.argv if os.path.isdir(args[1]): file_list = get_file_name(args[1], ".vtt") for file in file_list: vtt2srt(file) elif os.path.isfile(args[1]): vtt2srt(args[1]) print(‘done‘) else: print("arg[0] should be file name or dir")
注意:
1 为避免路径错误,请使用文件夹的绝对路径
标签:app src text 技术分享 opened lambda enc inf ==
原文地址:https://www.cnblogs.com/BigJ/p/vtt_srt.html
