标签(空格分隔): 协作框架
- 一:oozie example 运行任务调度案例
- 二:oozie 运行自定的mapreduce 的jar 包
- 三:oozie 调度shell 脚本
- 四:oozie 的coordinator 周期性调度当前任务
解压example 包
tar -zxvf oozie-examples.tar.gz
cd /home/hadoop/yangyang/oozie/examples/apps/map-reduce
job.properties --定义job相关的属性,比如目录路径、namenode节点等。
--定义workflow的位置
workflow.xml --定义工作流相关的配置(start --end --kill)(action)
--mapred.input.dir
--mapred.output.dir
lib --目录,存放job任务需要的资源(jar包)nameNode=hdfs://namenode01.hadoop.com:8020
jobTracker=namenode01.hadoop.com:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=${nameNode}/user/hadoop/${examplesRoot}/apps/map-reduce/workflow.xml
outputDir=map-reduce<workflow-app xmlns="uri:oozie:workflow:0.2" name="map-reduce-wf">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapred.mapper.class</name>
<value>org.apache.oozie.example.SampleMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.oozie.example.SampleReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/input-data/text</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
hdfs dfs -put example example

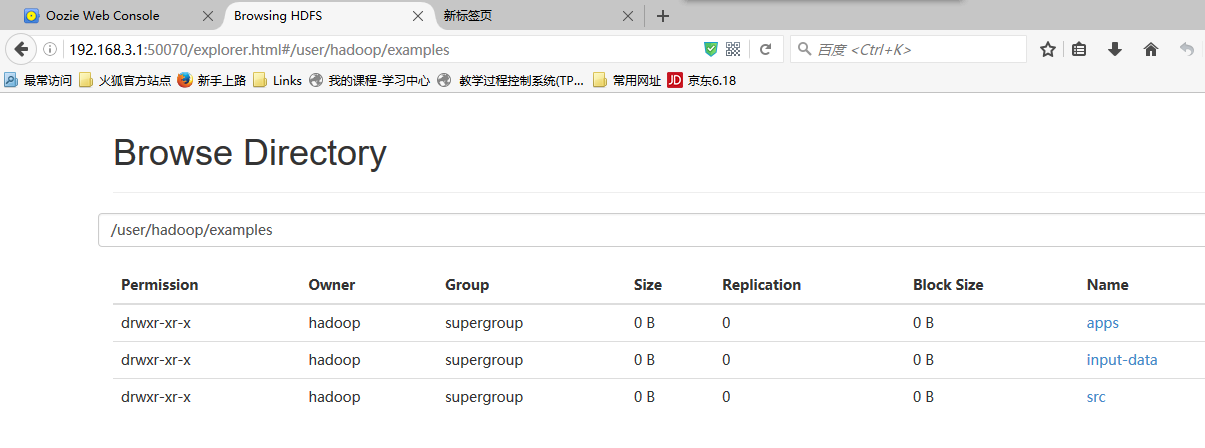
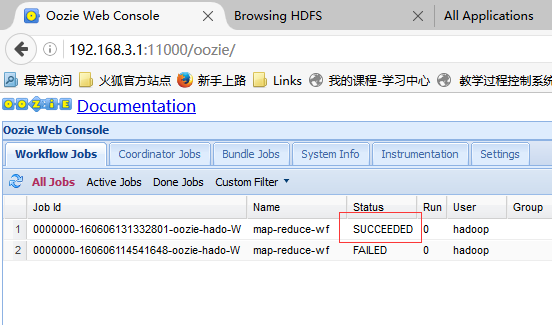
bin/oozie job -oozie http://namenode01.hadoop.com:11000/oozie -config examples/apps/map-reduce/job.properties -run
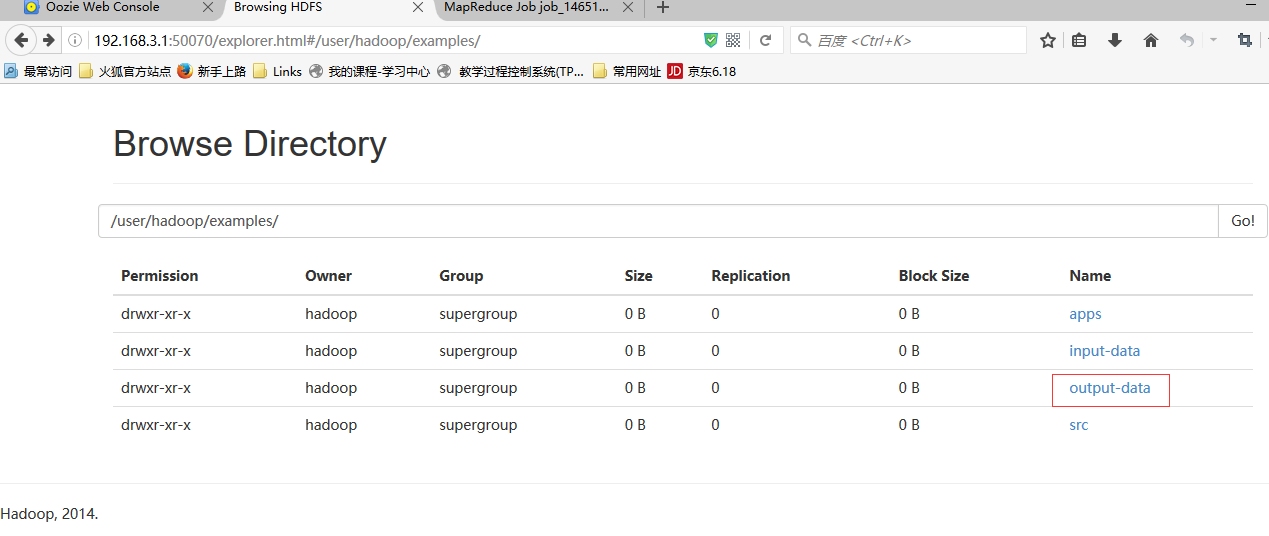
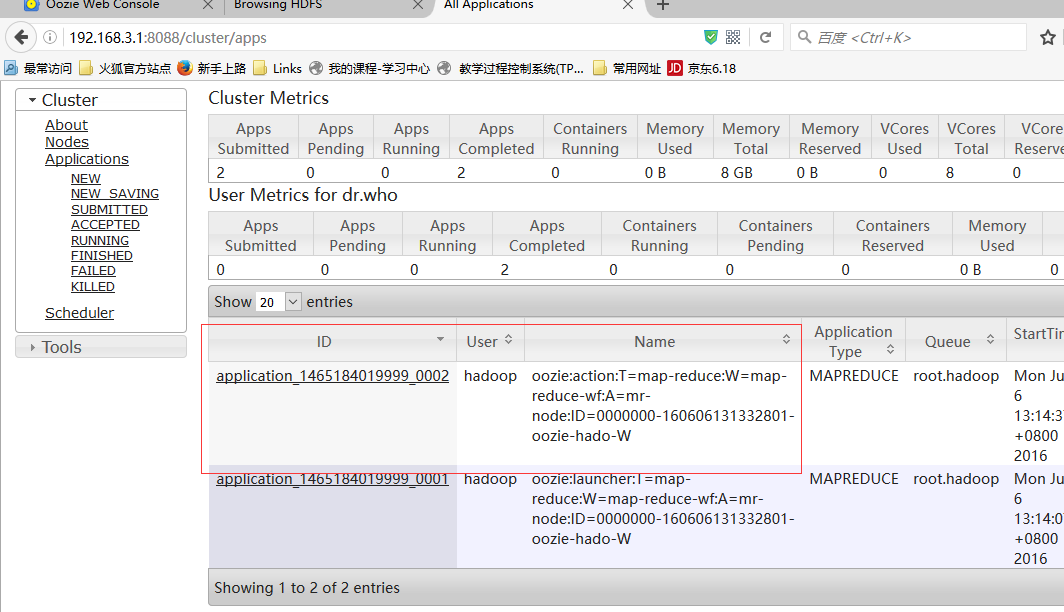
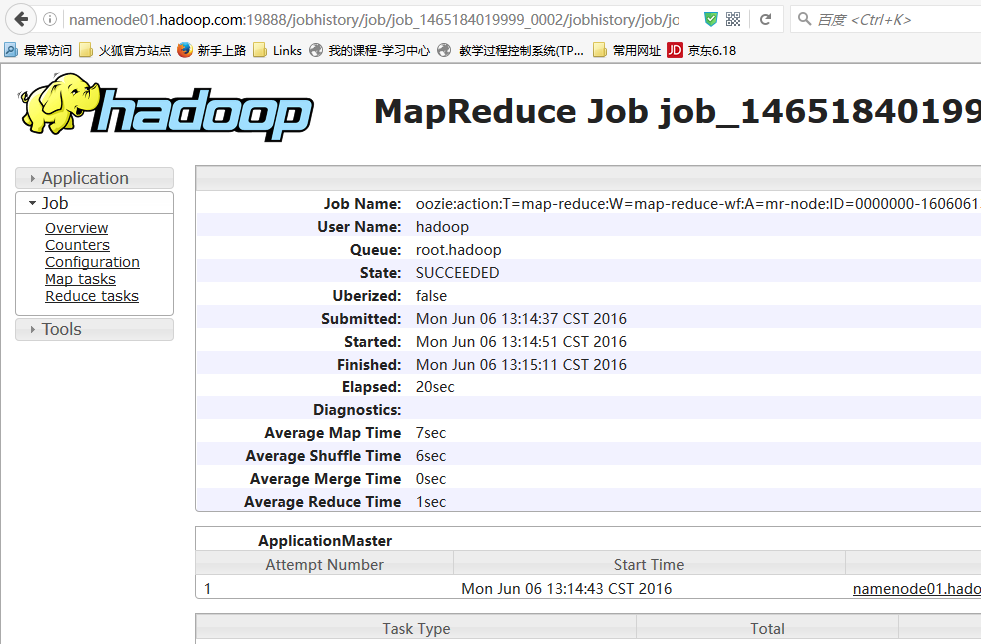
cd /home/hadoop/yangyang/oozie/
hdfs dfs -mkdir oozie-appsmkdir oozie-apps
cd /home/hadoop/yangyang/oozie/examples/apps
cp -ap map-reduce /home/hadoop/yangyang/oozie/oozie-apps/
cd /homme/hadoop/yangyang/oozie/oozie-appps/map-reduce
mkdir input-data
cp -p mr-wordcount.jar yangyang/oozie/oozie-apps/map-reduce/lib/
cp -p /home/hadoop/wc.input ./input-datanameNode=hdfs://namenode01.hadoop.com:8020
jobTracker=namenode01.hadoop.com:8032
queueName=default
examplesRoot=oozie-apps/map-reduce
oozie.wf.application.path=${nameNode}/user/hadoop/${examplesRoot}/workflow.xml
outputDir=oozie-reduce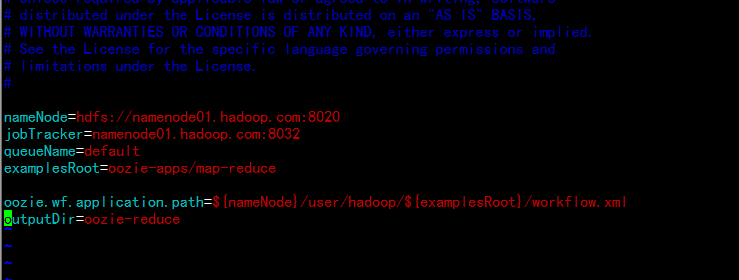
<workflow-app xmlns="uri:oozie:workflow:0.2" name="wc-map-reduce">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/hadoop/${examplesRoot}/output-data/${outputDir}"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<!--0 new API-->
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<!--1 input-->
<property>
<name>mapred.input.dir</name>
<value>/user/hadoop/${examplesRoot}/input-data</value>
</property>
<!--2 mapper class -->
<property>
<name>mapreduce.job.map.class</name>
<value>org.apache.hadoop.wordcount.WordCountMapReduce$WordCountMapper</value>
</property>
<property>
<name>mapreduce.map.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<property>
<name>mapreduce.map.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<!--3 reduer class -->
<property>
<name>mapreduce.job.reduce.class</name>
<value>org.apache.hadoop.wordcount.WordCountMapReduce$WordCountReducer</value>
</property>
<property>
<name>mapreduce.job.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<property>
<name>mapreduce.job.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<!--4 output -->
<property>
<name>mapred.output.dir</name>
<value>/user/hadoop/${examplesRoot}/output-data/${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
hdfs dfs -put map-reduce oozie-appsbin/oozie job -oozie http://namenode01.hadoop.com:11000/oozie -config oozie-apps/map-reduce/job.properties -run
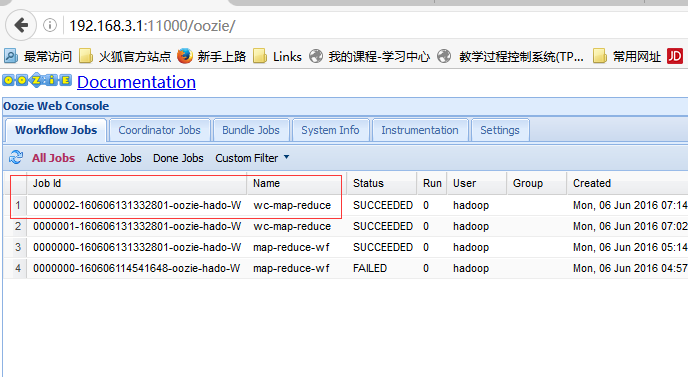
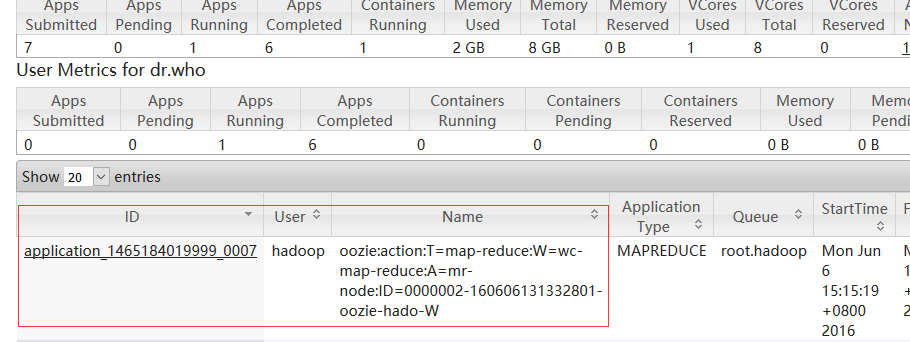
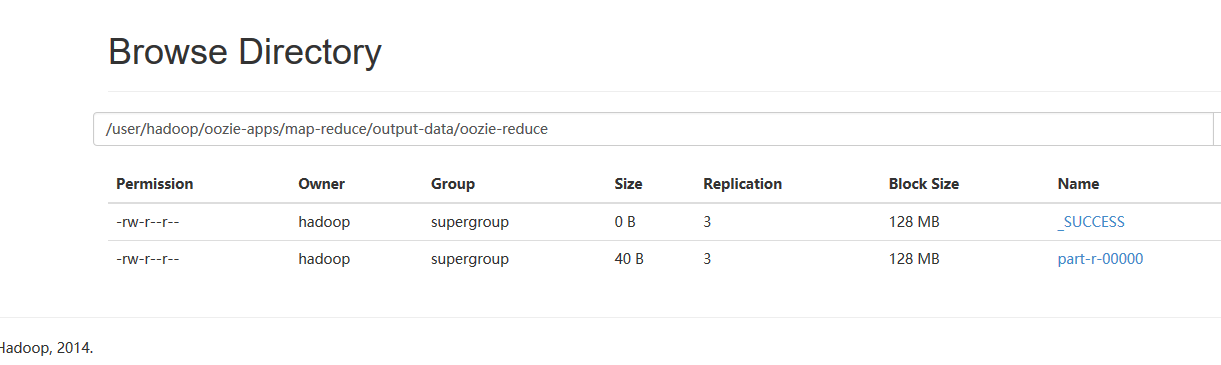
cd /home/hadoop/yangyang/oozie/examples/apps
cp -ap shell/ ../../oozie-apps/
mv shell mem-shellcd /home/hadoop/yangyang/oozie/oozie-apps/mem-shell#!/bin/bash
/usr/bin/free -m >> /tmp/meminfonameNode=hdfs://namenode01.hadoop.com:8020
jobTracker=namenode01.hadoop.com:8032
queueName=default
examplesRoot=oozie-apps/mem-shell
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/workflow.xml
EXEC=meminfo.sh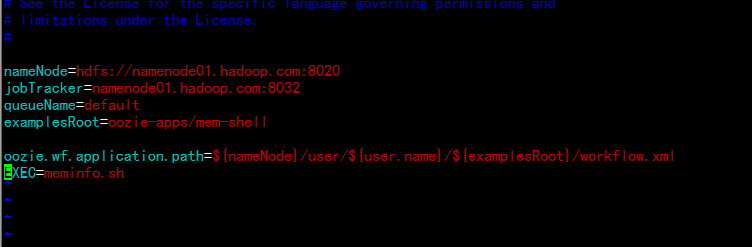
<workflow-app xmlns="uri:oozie:workflow:0.4" name="mem-shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC}</exec>
<file>/user/hadoop/oozie-apps/mem-shell/${EXEC}#${EXEC}</file>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
cd /home/hadoop/yangyang/oozie/oozie-apps
hdfs dfs -put mem-shell oozie-apps
bin/oozie job -oozie http://namenode01.hadoop.com:11000/oozie -config oozie-apps/mem-shell/job.properties -run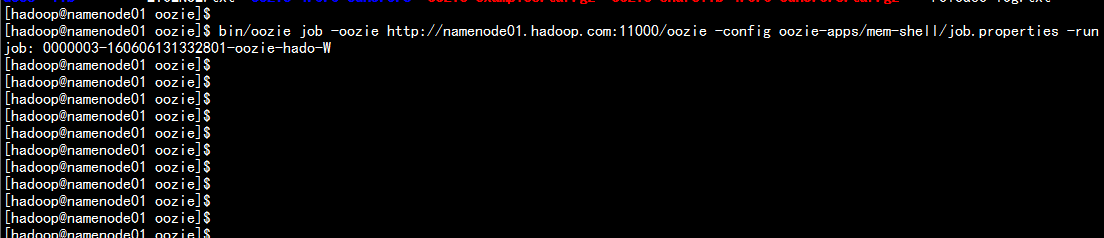
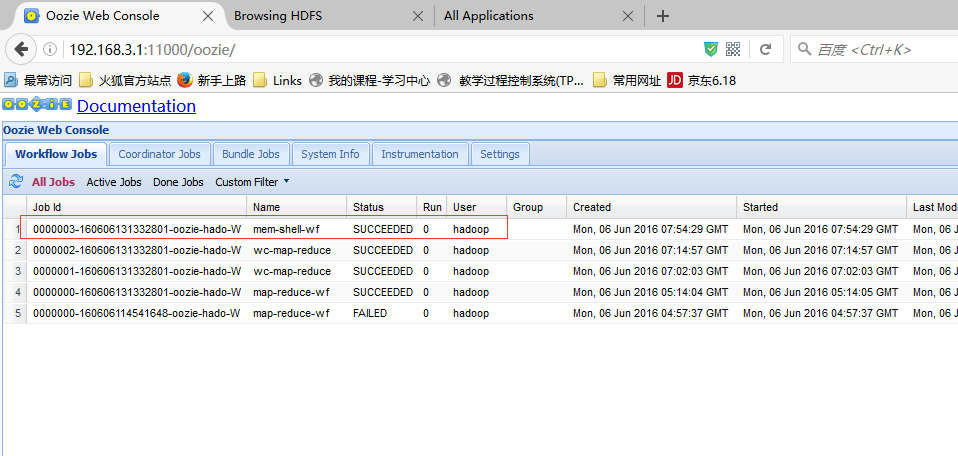
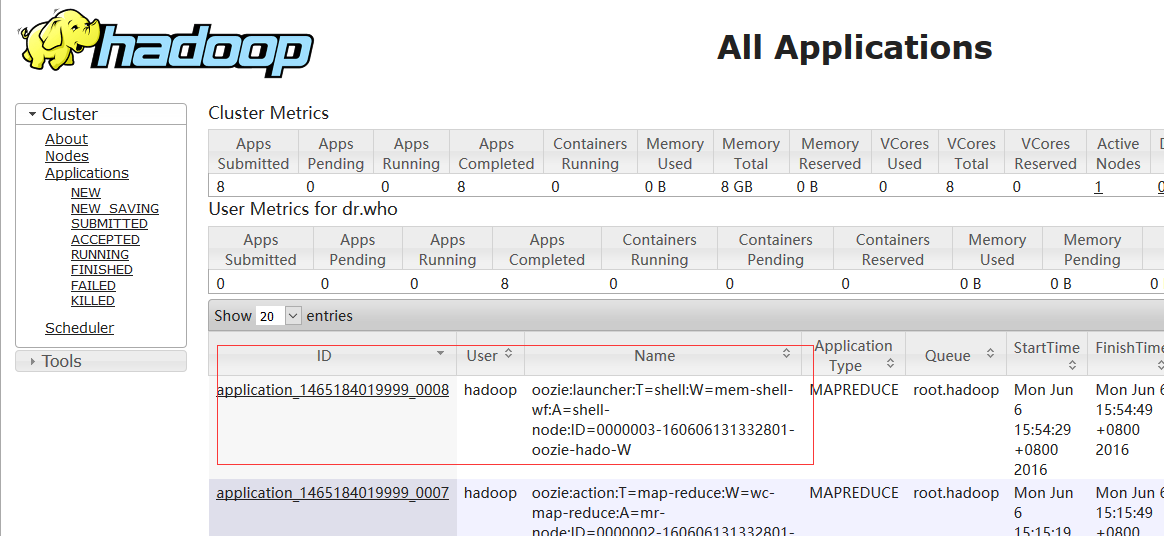
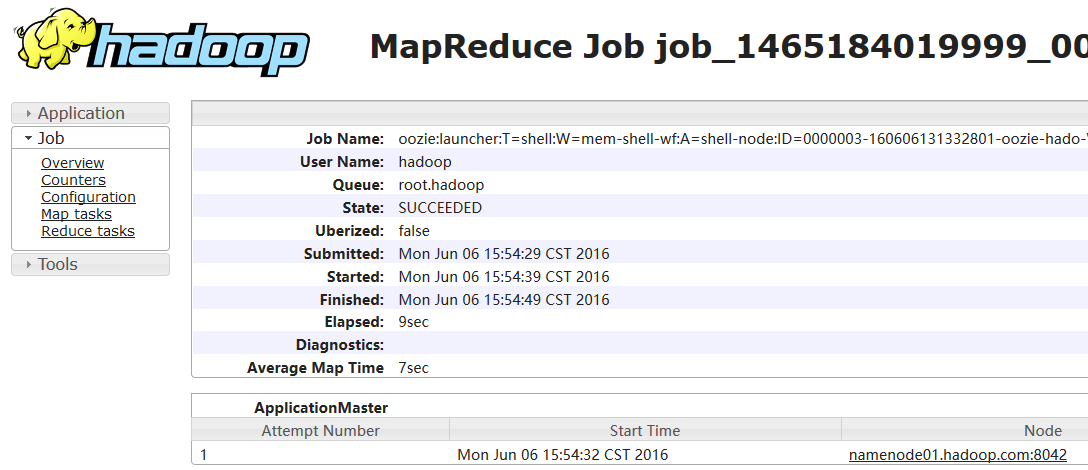
cd /home/hadoop/yangyang/oozie/conf
vim oozie-site.xml 增加:
<property>
<name>oozie.processing.timezone</name>
<value>GMT+0800</value>
</property>
<property>
<name>oozie.service.coord.check.maximum.frequency</name>
<value>false</value>
</property>
使用root 账户 配置
cp -p /etc/localtime /etc/localtime.bak
rm -rf /etc/localtime
cd /usr/share/zoneinfo/Asia/
cp -p Shanghai /etc/localtime
cd /home/hadoop/yangyang/oozie/oozie-server/webapps/oozie
vim oozie-console.js
function getTimeZone() {
Ext.state.Manager.setProvider(new Ext.state.CookieProvider());
return Ext.state.Manager.get("TimezoneId","GMT+0800");
}

bin/oozie-stop.sh
bin/oozie-start.sh 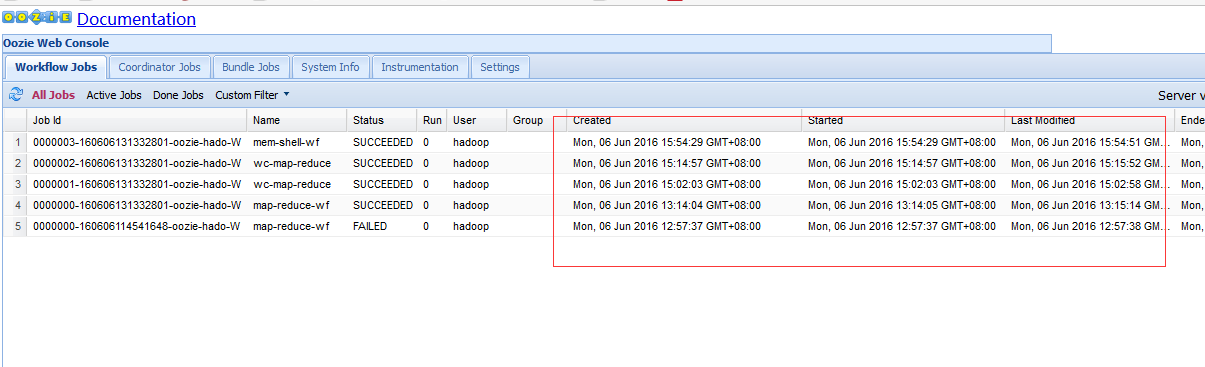
cd /home/hadoop/yangyang/oozie/examples/apps
cp -ap cron ../../oozie-apps/
cd cron
rm -rf job.properties workflow.xml
cd /home/hadoop/yangyang/oozie/oozie-apps/mem-shell
cp -p * ../cron
vim job.properties
---
nameNode=hdfs://namenode01.hadoop.com:8020
jobTracker=namenode01.hadoop.com:8032
queueName=default
examplesRoot=oozie-apps/cron
oozie.coord.application.path=${nameNode}/user/hadoop/${examplesRoot}/
start=2016-06-6T16:57+0800
end=2016-06-6T20:00+0800
workflowAppUri=${nameNode}/user/hadoop/${examplesRoot}/
EXEC=meminfo.sh
vim workflow.xml
---
<workflow-app xmlns="uri:oozie:workflow:0.4" name="memcron-shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC}</exec>
<file>/user/hadoop/oozie-apps/cron/${EXEC}#${EXEC}</file>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>vim coordinator.xml
---
<coordinator-app name="cron-coord" frequency="${coord:minutes(2)}" start="${start}" end="${end}" timezone="GMT+0800"
xmlns="uri:oozie:coordinator:0.2">
<action>
<workflow>
<app-path>${workflowAppUri}</app-path>
<configuration>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
<property>
<name>EXEC</name>
<value>${EXEC}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>hdfs dfs -put cron oozie-appsbin/oozie job -oozie http://namenode01.hadoop.com:11000/oozie -config oozie-apps/cron/job.properties -run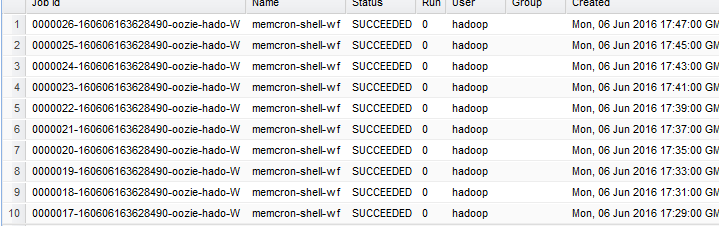
原文地址:http://blog.51cto.com/flyfish225/2097346