- 一:storm 简介
- 二:storm 的原理与架构
- 三:storm 的 安装配置
- 四:storm 的启动脚本
1. Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop。随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等,大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流。
2. 按照storm作者的说法,Storm对于实时计算的意义类似于Hadoop对于批处理的意义。Hadoop提供了map、reduce原语,使我们的批处理程序变得简单和高效。同样,Storm也为实时计算提供了一些简单高效的原语,而且Storm的Trident是基于Storm原语更高级的抽象框架,类似于基于Hadoop的Pig框架,让开发更加便利和高效。本课程会深入、全面的讲解Storm,并穿插企业场景实战讲述Storm的运用。数据源务必实时,所以采用Message Queue作为数据源,消息处理Comsumer实时从MQ获取数据进行处理,返回结果到Web或写DB。
这种方式有以下几个缺陷:
1、单机模式,能处理的数据量有限
2、不健壮,服务器挂掉即结束。而Storm集群节点挂掉后,任务会重新分配给其他节点,作业不受影响。
3、失败重试、事务等,你需要在代码上进行控制,过多精力放在业务开发之外。
4、伸缩性差: 当一个消息处理者的消息量达到阀值,你需要对这些数据进行分流, 你需要配置这些新的处理者以让他们处理分流的消息。1. 适用场景广泛: storm可以实时处理消息和更新DB,对一个数据量进行持续的查询并返回客户端(持续计算),对一个耗资源的查询作实时并行化的处理(分布式方法调用,即DRPC),storm的这些基础API可以满足大量的场景。
2. 可伸缩性高: Storm的可伸缩性可以让storm每秒可以处理的消息量达到很高。扩展一个实时计算任务,你所需要做的就是加机器并且提高这个计算任务的并行度 。Storm使用ZooKeeper来协调集群内的各种配置使得Storm的集群可以很容易的扩展。
3. 保证无数据丢失: 实时系统必须保证所有的数据被成功的处理。 那些会丢失数据的系统的适用场景非常窄, 而storm保证每一条消息都会被处理, 这一点和S4相比有巨大的反差。
4. 异常健壮: storm集群非常容易管理,轮流重启节点不影响应用。
5. 容错性好:在消息处理过程中出现异常, storm会进行重试
6. 语言无关性: Storm的topology和消息处理组件(Bolt)可以用任何语言来定义, 这一点使得任何人都可以使用storm.

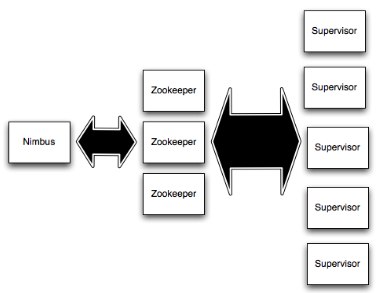
1. Nimbus 和Supervisors 之间所有的协调工作是通过 一个Zookeeper 集群。
2. Nimbus进程和 Supervisors 进程是无法直接连接和无状态的; 所有的状态维持在Zookeeper中或保存在本地磁盘上。
3. 这意味着你可以 kill -9 Nimbus 或Supervisors 进程,而不需要做备份。
这种设计导致storm集群具有令人难以置信的稳定性,即无耦合。1. Nimbus 负责在集群分发的代码,topo只能在nimbus机器上提交,将任务分配给其他机器,和故障监测。
2. Supervisor,监听分配给它的节点,根据Nimbus 的委派在必要时启动和关闭工作进程。 每个工作进程执行topology 的一个子集。一个运行中的topology 由很多运行在很多机器上的工作进程组成。
3. 在Storm中有对于流stream的抽象,流是一个不间断的无界的连续tuple,注意Storm在建模事件流时,把流中的事件抽象为tuple即元组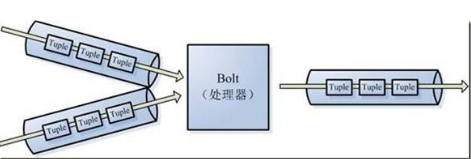
4. Storm认为每个stream都有一个源,也就是原始元组的源头,叫做Spout(管口)
5.处理stream内的tuple,抽象为Bolt,bolt可以消费任意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的spout再将spout中流出的tuple导向特定的bolt,又bolt对导入的流做处理后再导向其他bolt或者目的地。
可以认为spout就是水龙头,并且每个水龙头里流出的水是不同的,我们想拿到哪种水就拧开哪个水龙头,然后使用管道将水龙头的水导向到一个水处理器(bolt),水处理器处理后再使用管道导向另一个处理器或者存入容器中。
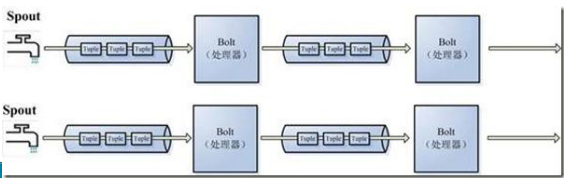
为了增大水处理效率,我们很自然就想到在同个水源处接上多个水龙头并使用多个水处理器,这样就可以提高效率。
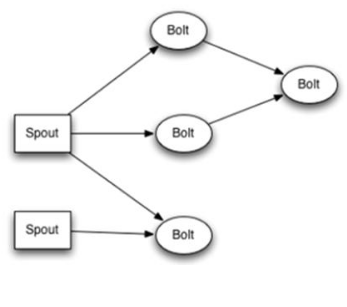
这是一张有向无环图,Storm将这个图抽象为Topology(拓扑),Topo就是storm的Job抽象概念,一个拓扑就是一个流转换图
图中每个节点是一个spout或者bolt,每个spout或者bolt发送元组到下一级组件,广播方式。
而Spout到单个Bolt有6种grouping方式
Storm将流中元素抽象为tuple,一个tuple就是一个值列表value list,list中的每个value都有一个name,并且该value可以是任意可序列化的类型。拓扑的每个节点都要说明它所发射出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
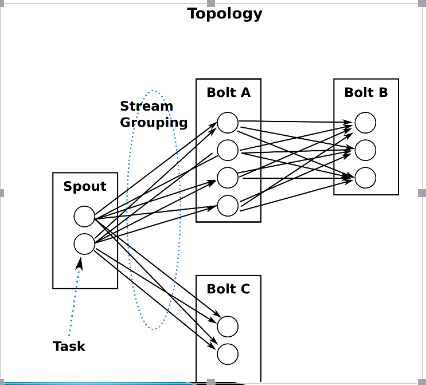
Streams:消息流
消息流是一个没有边界的tuple序列,而这些tuples会被以一种分布式的方式并行创建和处理。 每个tuple可以包含多列,字段类型可以是: integer, long, short, byte, string, double, float, boolean和byte array。 你还可以自定义类型 — 只要你实现对应的序列化器。
Spouts:消息源
Spouts是topology消息生产者。Spout从一个外部源(消息队列)读取数据向topology发出tuple。 消息源Spouts可以是可靠的也可以是不可靠的。一个可靠的消息源可以重新发射一个处理失败的tuple, 一个不可靠的消息源Spouts不会。
Spout类的方法nextTuple不断发射tuple到topology,storm在检测到一个tuple被整个topology成功处理的时候调用ack, 否则调用fail。
storm只对可靠的spout调用ack和fail。

Bolts:消息处理者
消息处理逻辑被封装在bolts里面,Bolts可以做很多事情: 过滤, 聚合, 查询数据库等。
Bolts可以简单的做消息流的传递。复杂的消息流处理往往需要很多步骤, 从而也就需要经过很多Bolts。第一级Bolt的输出可以作为下一级Bolt的输入。而Spout不能有一级。
Bolts的主要方法是execute(死循环)连续处理传入的tuple,成功处理完每一个tuple调用OutputCollector的ack方法,以通知storm这个tuple被处理完成了。当处理失败时,可以调fail方法通知Spout端可以重新发送该tuple。
流程是: Bolts处理一个输入tuple, 然后调用ack通知storm自己已经处理过这个tuple了。storm提供了一个IBasicBolt会自动调用ack。
Bolts使用OutputCollector来发射tuple到下一级Blot。
tar -zxvf zookeeper-3.4.5.tar.gz
mv zookeeper-3.4.5 /usr/local/zookeeper
---
cd /usr/local/zookeeper
mkdir data
cd data
echo "1" > myid
--
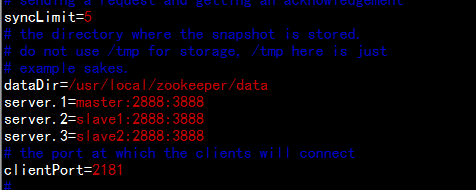
cd /usr/local/zookeeper/conf
cp -p zoo_sample.cfg zoo.cfg
vim zoo.cfg
dataDir=/usr/local/zookeeper/data
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
---
cd /usr/local/
tar -zcvf zookeeper.tar.gz zookeeper
--- 同步到slave1 与slave2 节点----
scp zookeeper.tar.gz root@slave1:/usr/local/
scp zookeeper.tar.gz root@slave2:/usr/local/
------------------slave1 节点---------------------
cd /usr/local/
tar -zxvf zookeeepr.tar.gz
cd zookeeper/data
echo ‘2‘ > myid
------------------slave2 节点--------------------
cd /usr/local/
tar -zxvf zookeeepr.tar.gz
cd zookeeper/data
echo ‘3‘ > myid
#!/bin/bash
if [ $# -ne 1 ]; then
echo "Usage: sh start_zookeeper.sh [start|status|stop]"
exit 2
fi
for node in master slave1 slave2 # ---这个地方有多少个主机就加多少
do
echo "$1 in $node"
ssh $node "source /etc/profile && /opt/modules/zookeeper-3.4.5/bin/zkServer.sh $1"
done1. CentOS6.4 安装相关编译工具包
yum install -y gcc gcc++* gcc-c++ uuid-devel libuuid-devel libtool git
2. 安装 ZeroMQ
wget http://download.zeromq.org/zeromq-2.1.7.tar.gz
tar -xzvf zeromq-2.1.7.tar.gz
cd zeromq-2.1.7
./configure
make
make install
3. JZMQ安装
git clone https://github.com/nathanmarz/jzmq.git
cd jzmq
./autogen.sh
./configure
make
make install
上传文件apache-storm-0.9.0.6.tar.gz 到/home/hadoop下面
cd /usr/local/storm
mkdir data
cd conf
---
vim storm.yaml
########### These MUST be filled in for a storm configuration
storm.zookeeper.servers:
- "master"
- "slave1"
- "slave2"
#
nimbus.host: "master"
#
---
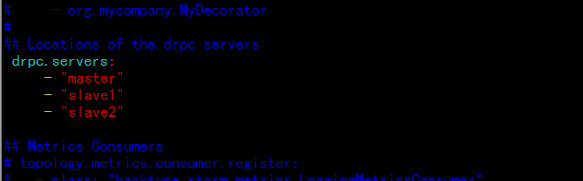
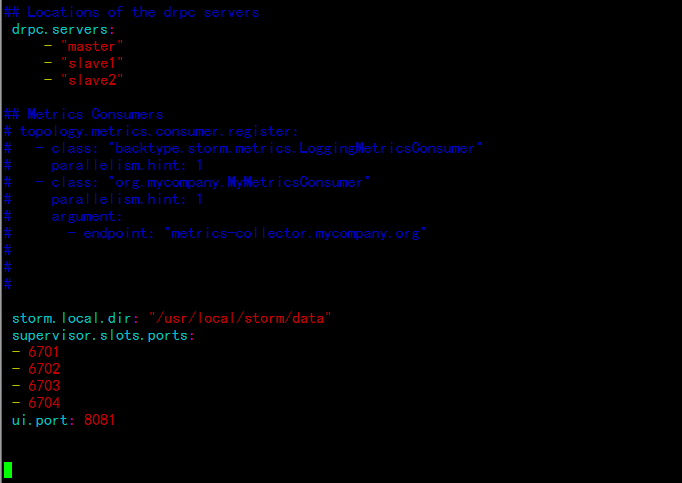
## Locations of the drpc servers
drpc.servers:
- "master"
- "slave1"
- "slave2"
---
增加storm 任务的目录与端口:
---
storm.local.dir: "/usr/local/storm/data"
supervisor.slots.ports:
- 6701
- 6702
- 6703
- 6704
ui.port: 8081
------同步所有节点----------
cd /usr/local/
tar -zcvf storm.tar.gz storm
scp storm.tar.gz root@slave1:/usr/local/
scp storm.tar.gz root@slave2:/usr/local/
---------------slave1节点----------
tar -zxvf storm.tar.gz
---------------slave2节点----------
tar -zxvf storm.tar.gz
1. 启动zookeeper 服务
master:
cd /usr/local/zookeeper/
bin/zkServer.sh start
--------------------------------------
slave1:
cd /usr/local/zookeeper/
bin/zkServer.sh start
--------------------------------------
slave2:
cd /usr/local/zookeeper/
bin/zkServer.sh start
--------------------------------------
2. 启动storm的相关服务
master:
cd /usr/local/storm/
bin/storm nimbus &
bin/storm ui &
------------------------------
slave1
cd /usr/local/storm/
bin/storm supervisor &
------------------------------
slave2
cd /usr/local/storm/
bin/storm supervisor &
-------------------------------
打开浏览器访问:
http://192.168.3.1:8081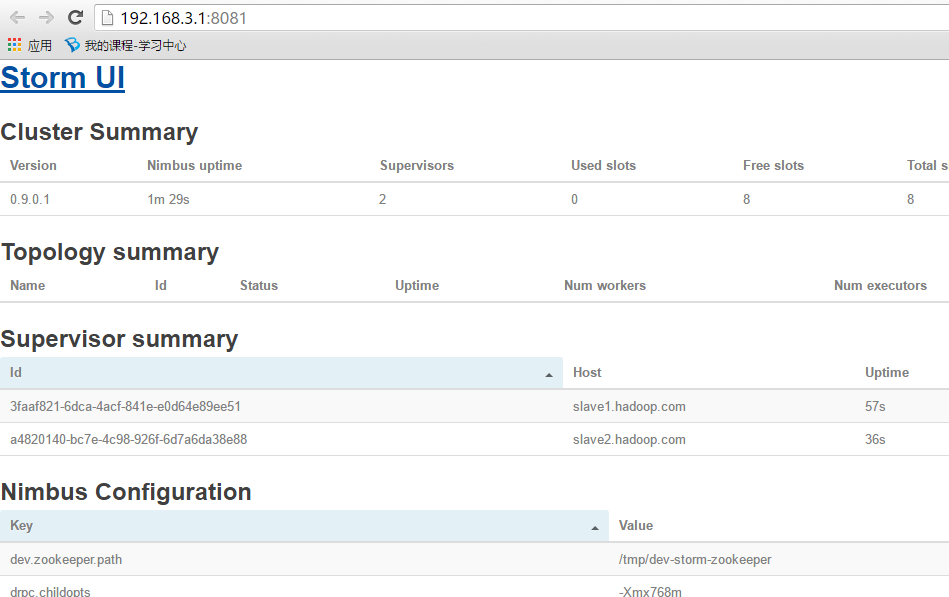
bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount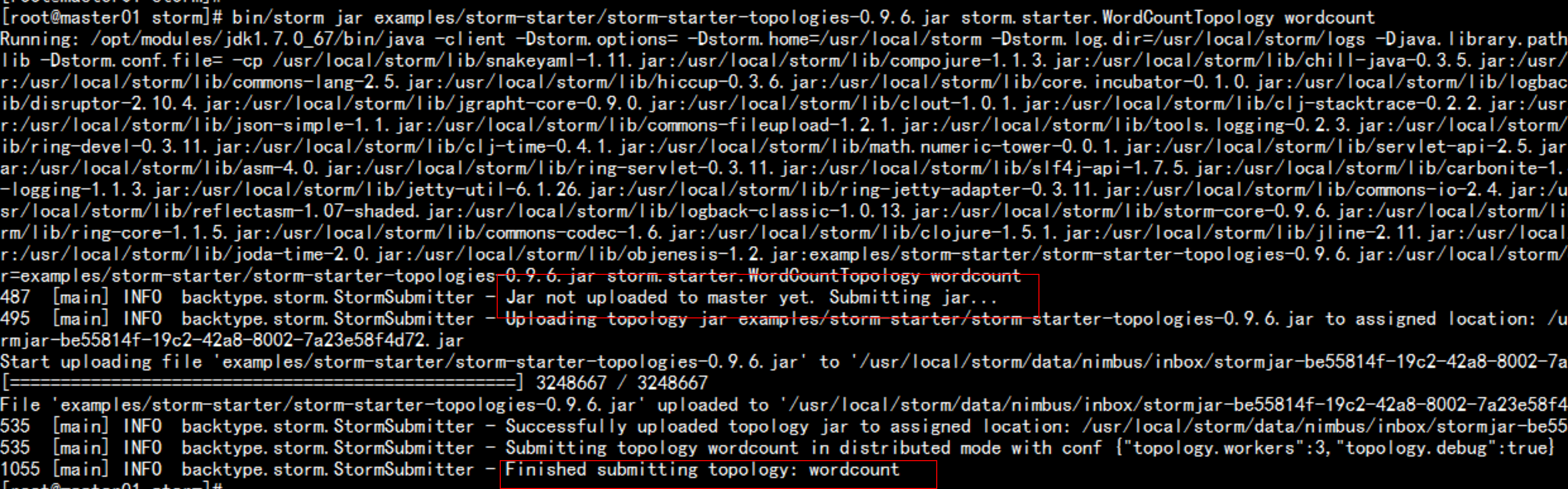
1. storm.zookeeper.servers:这是一个为Storm集群配置的Zookeeper集群的主机列表
2. storm.local.dir:Nimbus和Supervisor守护程序需要一个本地磁盘目录存储小量状态(像jars,confs,其它),每台机器都创建这些目录,赋可写权限
3. java.library.path:这是Storm使用的本地库(ZeroMQ和JZMQ)载入路径。大多数安装,默认路径"/usr/local/lib:/opt/local/lib:/usr/lib"就行,所以你可能不需要配置它。
4. supervisor.slots.ports:?每一台worker机器,你用这个配置来指定多少workers运行在那台机。每个worker使用单一端口接收消息,并且这个设置定义哪个端口是打开的且可以使用。如果你定义5个端口,那么Storm将在这台机分配5个worker运行。
------------------------------------
Storm是一个快速失败(fail-fast)的系统,这意味着这些进程随时都可能因发生错误而停止。由于Storm的设计,所以它随时停止都是安全的,当进程重新启动时正确的恢复。这是为什么Storm保持进程无状态的原因--?如果Nimbus或supervisors重新启动,正在运行的topologies是不受影响的。
Nohup挂到后台执行
1)Nimbus
在master机器的supervision下运行命令”bin/storm nimbus”
2)Supervisor
在每个worker机器的supervision下运行命令”bin/storm supervisor”。Supervisor守护程序负责starting 和 stopping 那台机上的worker进程
3)UI
运行supervision下的命令”bin/storm ui”来运行Storm UI(你能从浏览器访问一个站点,它提供集群和topologies的诊断信息)。在你的浏览器中输入”?http://{nimbus host}:8081”访问UI。nimbus topology任务提交后,程序是运行在supervisor节点上
Nimbus不参与程序的运行
Nimbus出现故障,不能提交Topology,已经提交了的Topology还是
正常运行在集群上
已经运行在集群上Topology,如果这时候某些task出现异常
则无法重现分配节点
-----------------------------------------------------------------
查看Topology运行日志:
需要启动一个进程 logviewer
需要在每个supervisor节点上启动,不用在nimbus节点上启动
bin/storm logviewer > ./logs/logviewer.out 2>&1 &
nimbus supervisor ui logviewer
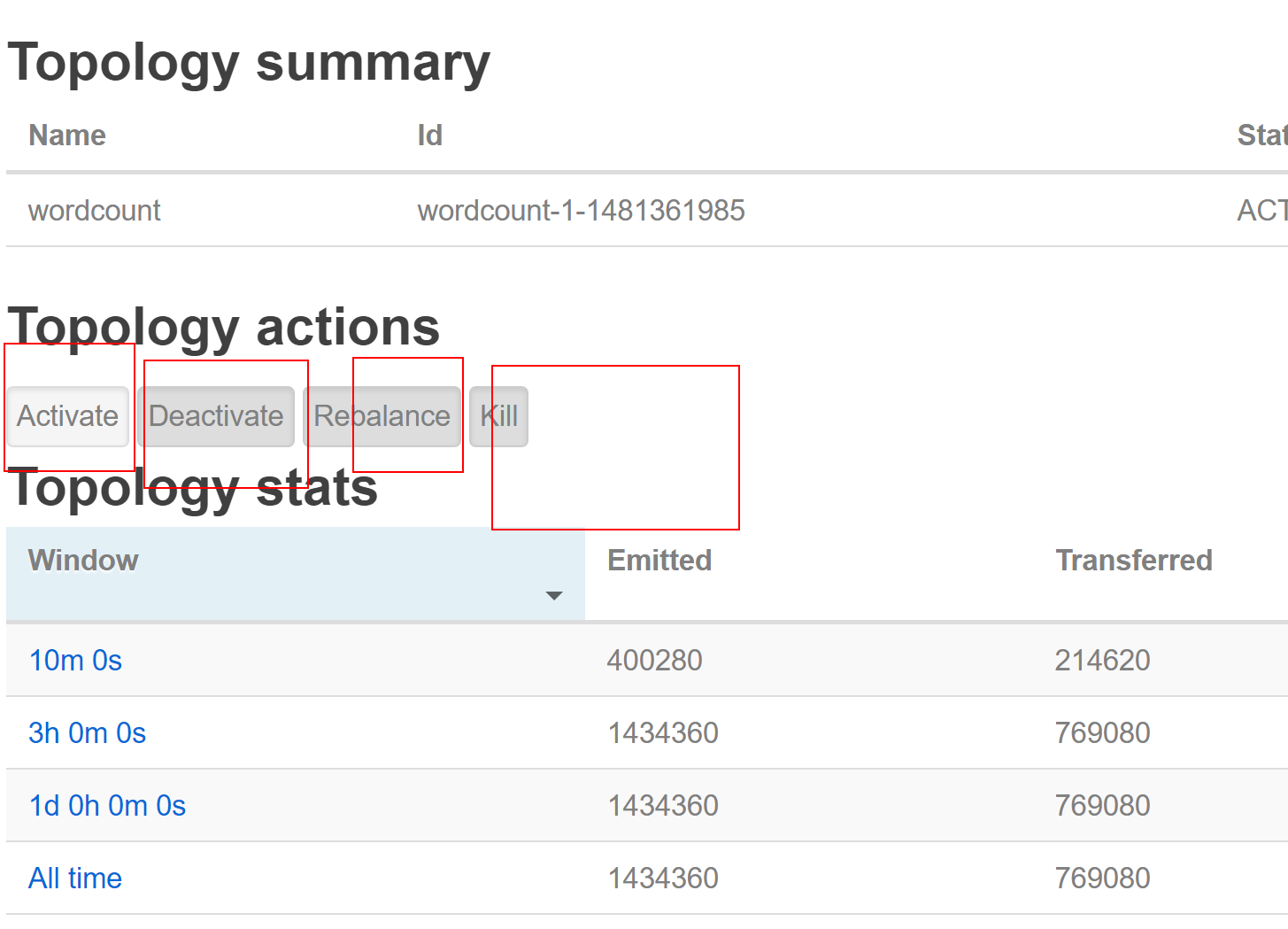
activate 激活
deactivate 暂停
Repalance 从新分配
kill 杀掉这个 toplogy
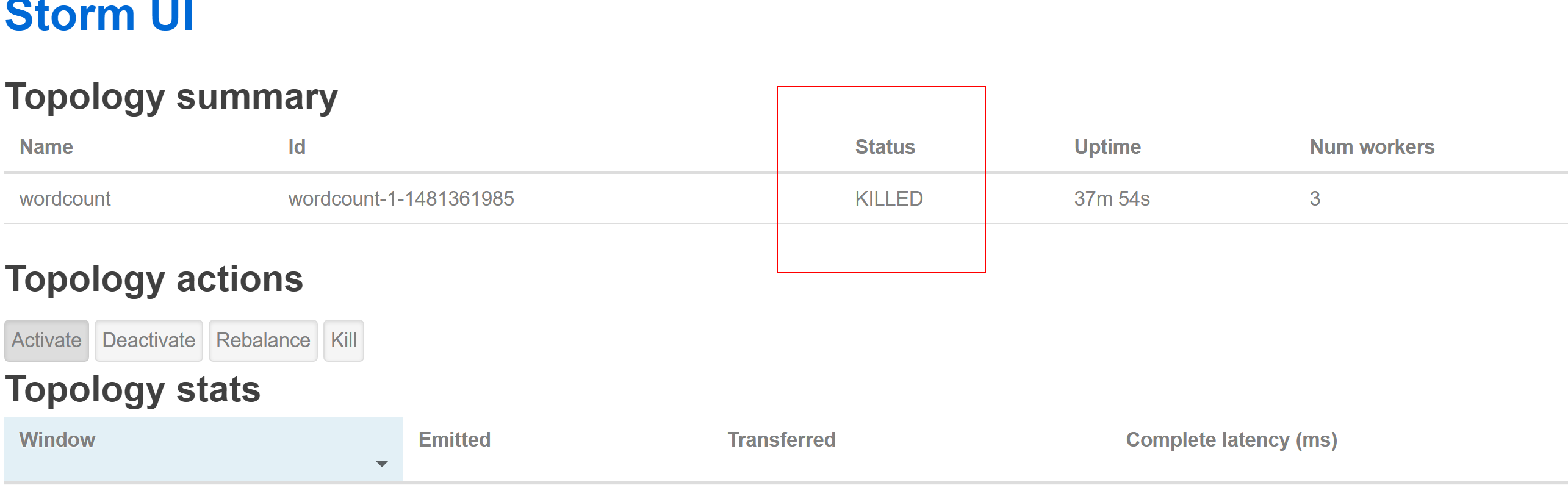
直接通过命令行执行:# bin/storm kill wordcount(提交的时候
指定的Topology名称)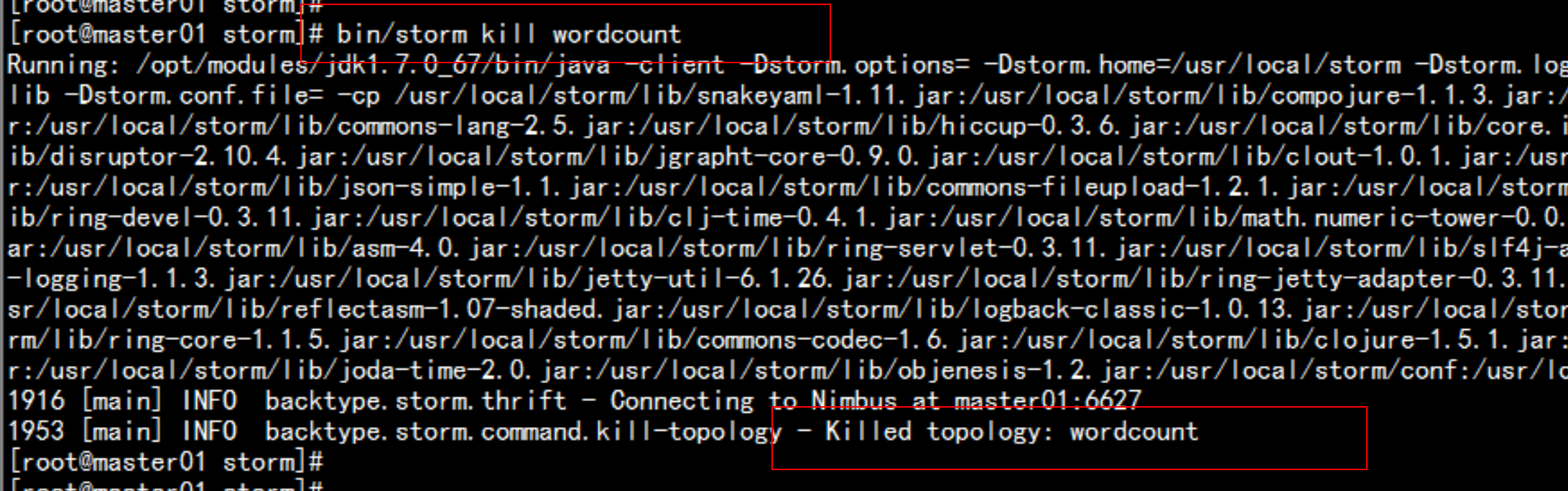
登录到zookeeper 的里面去
cd /usr/local/zookeeper/bin
./zkCli.sh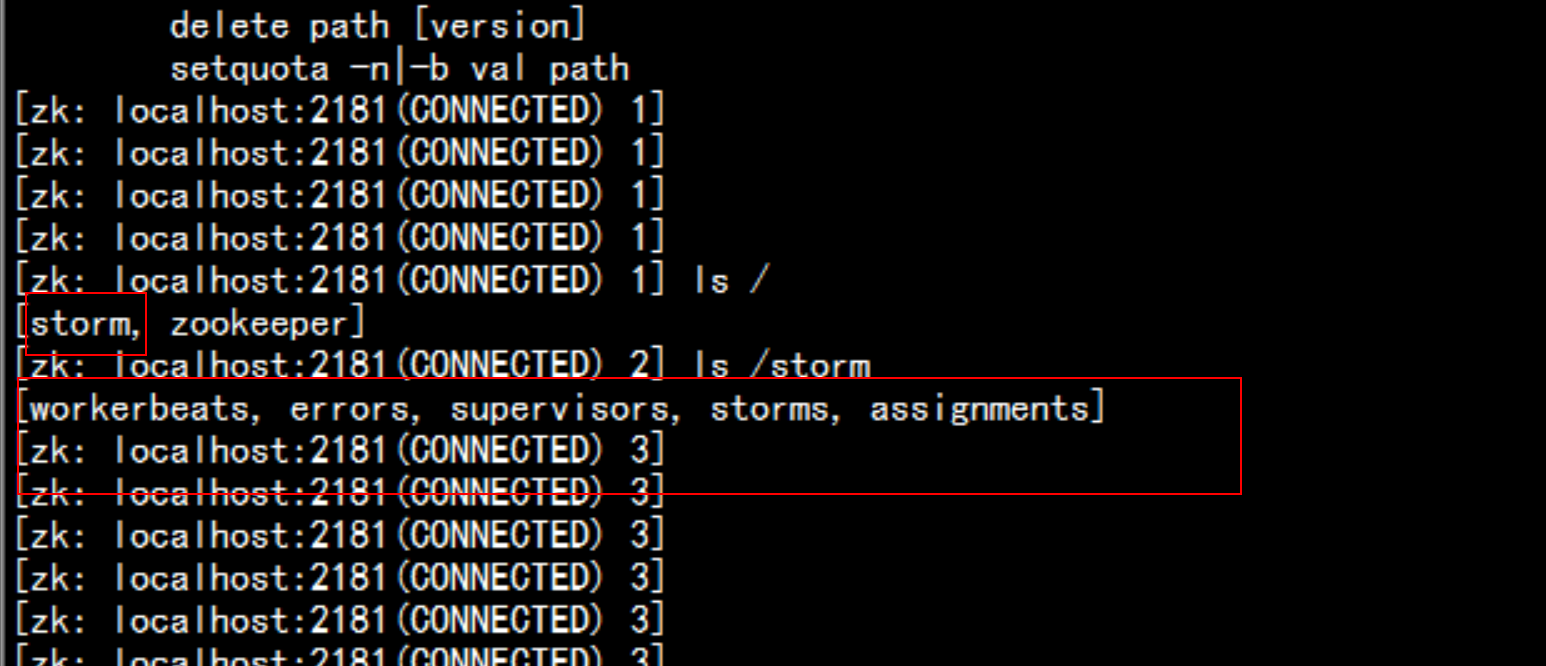
znode:
/storm
/workerbeats worker心跳信息
/errors topology运行过程中Task运行异常信息
/supervisors 记录supervisor状态心跳信息
/storms 记录的是topology任务信息
/assignments 记录的是Topology任务的分配信息 kill -9 `ps -ef | grep daemon.nimbus | awk ‘{print $2}‘ | head -n 1`
kill -9 `ps -ef | grep ui.core | awk ‘{print $2}‘ | head -n 1`
kill -9 `ps -ef | grep daemon.supervisor | awk ‘{print $2}‘ | head -n 1`
kill -9 `ps -ef | grep daemon.logviewer | awk ‘{print $2}‘ | head -n 1`#!/bin/bash
source /etc/profile
STORM_HOME=/opt/modules/apache-storm-0.9.6
## 主节点 nimbus ui
${STORM_HOME}/bin/storm nimbus > /dev/null 2>&1 &
${STORM_HOME}/bin/storm ui > /dev/null 2>&1 &
## 从节点 supervisor logviewer
for supervisor in `cat ${STORM_HOME}/bin/stormSupervisorHosts`
do
echo "start supervisor and logviewer in $supervisor"
ssh $supervisor "source /etc/profile && ${STORM_HOME}/bin/storm supervisor > /dev/null 2>&1 &" &
ssh $supervisor "source /etc/profile && ${STORM_HOME}/bin/storm logviewer > /dev/null 2>&1 &" &
done
#!/bin/bash
source /etc/profile
STORM_HOME=/opt/modules/apache-storm-0.9.6
### 主节点 nimbus ui
kill -9 `ps -ef | grep daemon.nimbus | awk ‘{print $2}‘ | head -n 1`
kill -9 `ps -ef | grep ui.core | awk ‘{print $2}‘ | head -n 1`
### 从节点 supervisor logviewer
for supervisor in `cat ${STORM_HOME}/bin/stormSupervisorHosts`
do
echo "stop supervisor and logviewer in $supervisor"
ssh $supervisor kill -9 `ssh $supervisor "ps -ef| grep daemon.supervisor| awk ‘{print $2}‘ | head -n 1" ` > /dev/null 2>&1 &
ssh $supervisor kill -9 `ssh $supervisor "ps -ef| grep daemon.logviewer| awk ‘{print $2}‘ | head -n 1" ` >/dev/null 2>&1 &
done原文地址:http://blog.51cto.com/flyfish225/2097505