标签:通过 相加 替换 inf inxi 覆盖 git src 深浅copy
上周内容回顾
解释型:
当程序运行的时候,逐行解释,逐行执行。
c
编译型:
一次性全部把所有的代码编译成二进制。
变量:a=‘alex‘
常量:一直不变的量,全部大写,放在py文件的最上面。
注释:#
‘‘‘ ‘‘‘ """ """
基础数据类型:
int 数字运算
str 字符串,少量的数据存储
+ 拼接;str * int
python凡是用引号引起来的就是字符串
bool:True False
input 用户交互,他出来的全部是字符串类型
格式化输出 % d s f
运算符:
+ - * / %
逻辑运算符:
() > not > and > or
同一优先级,从左至右依次计算
x or y if x True,return x
if:
if:
pass
if 条件:
pass
else:
pass
if 条件:
pass
elif 条件:
pass
elif 条件:
pass
else:
pass
if 条件:
if 条件:
pass
if...
while True:
pass
跳出循环:
1、改变条件;
2、break。
continue:跳出本次循环,继续下次循环。
while 条件:
pass
else:
pass
当while被打断走else
for 变量 in 可迭代对象:
pass
for 变量 in 可迭代对象:
pass
else:
pass
编码:
ascii:字母、数字、特殊字符。
万国码:unicode:
A:两个字节16位 0000 0010 0000 0010
中:两个字节
万国码升级:
A:四个字节16位 0000 0010 0000 0010 0000 0010 0000 0010
中:四个字节
占空间,浪费资源。
utf-8:最少用一个字节,表示一个字符
A:0000 0010 一个字节
欧洲:000 0010 0000 0010 两个字节
中文:000 0010 0000 0010 000 0010 三个字节
gbk国标:
A:0000 0010 一个字节
中:0000 0010 0000 0010 两个字节
作业讲解
01 int
1,2,3... 用户计算,运算
i = 3
print(i.bit_length())
转化二进制最小位数
02 str
‘老男孩‘,‘alex‘ ... 少量的数据存储
int ---> str str(int)
str ---> str int(str) str必须为数字
int ---> bool 0 False 非零 True
bool ---> int int(True) 1 int(False) 0
str ---> bool ‘‘ 空字符串 false 非空字符串 True
#字符串是有索引的
s[起始索引:结束索引+1:步长]
s = ‘python自动化运维21期‘
s1=s[0]
print (s1)
p
s3 = s[-1]
print (s3)
期
#切片 顾头不顾腚
s1 = s[0:6] #如果前面是0,0可以不写 s1 = s[:6]
print(s1)
python
s2 = s[6:9]
print(s2)
自动化
#跳切 步长
s3 = s[:5:2]
print(s3)
pto
#取全部
s4 = s[:]
print(s4)
#倒取 必须加反向步长
s5 = s[-1:-5:-1]
print(s5)
s = ‘oldBoy‘
#1 * capitalize() 首字母大写
s1 = s.
#2 *** upper() 全部大写 lower() 全部小写
code = ‘QeAr‘.upper()
your_code = input(‘请输入验证码:‘).upper()
if your_code == code:
print(‘验证成功‘)
#3 * s.swapcase() 大小写反转
s = ‘oldBoy‘
s4 = s.swapcase()
print(s4)
#4 * s.title() 非字母隔开的每个单词首字母大写
s = ‘alex wusir*old‘
#5 s.center 居中,长度自己设定,默认填充物是None
s6 =s.center(30,"*")
print(s6)
#6 *** s.startswith() 以xxx为开头 s.endswith()
s = ‘oldBoy‘
s7 = s.startswith(‘o‘)
print(s7)
True
s = ‘oldBoy‘
s7 = s.startswith(‘ol‘)
print(s7)
True
s = ‘oldBoy‘
s7 = s.startswith(‘B‘,3,5)
print(s7)
True
#7 *** s.strip() 去除收尾空格,制表符\t,换行符,但不仅仅
s = ‘ oldBoy ‘
s8 = s.strip()
print(s8)
oldBoy
s = ‘\toldBoy\n‘
s8 = s.strip()
print(s8)
oldBoy
name = input(‘>>>‘).strip()
if name == ‘oldboy‘:
print(‘验证成功‘)
s = ‘tyoldBoyrte‘
s81 = s.strip(‘t‘)
print(s81)
s81 = s.strip(‘tey‘)
print(81)
oldBoyr
s.sltrip s.srtrip
#8 **** split() (str ---> list) 默认用空格隔开
s = ‘oldboy wusir alex‘
l = s.split()
print(l)
[‘oldboy‘,‘wusir‘,‘alex‘]
s = ‘oldboy,wusir,alex‘
l = s.split(‘,‘)
print(l)
[‘oldboy‘,‘wusir‘,‘alex‘]
s = ‘oldboywusiroalex‘
l = s.split(‘o‘)
print(l)
[‘‘,‘ldb‘,‘ywusir‘,‘alex‘]
#可设置切割次数
s = ‘oldboywusiroalex‘
l = s.split(‘o‘,1)
print(l)
[‘‘,‘ldboywusiroalex‘]
#9 join()
s = ‘oldBoy‘
s9 = ‘+‘.join(s)
print(s9)
o+l+d+B+o+y
将list转换为str,但非字符串元素不可用
l1 = [‘oldboy‘,‘wusir,‘alex‘‘]
s91 = ‘_‘.join(l1)
print(91)
oldboy_wusir_alex
#10 replace()替换
s = ‘大铁锤fdsalj铁锤妹妹范德萨‘
s10 = s.replace(‘铁锤‘,‘钢蛋‘)
print(s10)
大钢蛋fdsalj钢蛋妹妹范德萨
#11 find() 通过元素找索引,找不到返回-1 index() 找不到会报错
s = ‘oldBoy‘
ind = s.find(‘d‘)
print(ind)
2
s = ‘oldBoy‘
ind = s.find(‘o‘)
print(ind)
0
s = ‘oldBoy‘
ind = s.find(‘A‘)
print(ind)
-1
#12 公共方法 len() count()
s = ‘asdaksjdkajskdajlk‘
print(len(s))
18
s = ‘fdsadd‘
print(s.count(‘d‘))
3
#13 格式化输出format
res = ‘我叫{}今年{},爱好{}‘.format(‘agon‘,‘18‘,‘male‘)
print(res)
res = ‘我叫{0}今年{1},爱好{2},我依然叫{0}‘.format(‘agon‘,‘18‘,‘male‘)
print(res)
res = ‘{}‘
#14 is系列
name=‘jinxin123‘print(name.isalnum()) #字符串由字母或数字组成
print(name.isalpha()) #字符串只由字母组成
print(name.isdigit()) #字符串只由数字组成
i = ‘123a‘
if i.isdigit():
i = int(i)
else:
print("输入有误。。。")
03 bool
True/False 条件:for while if
04 list 列表 可以放各种类型 大量数据 32位上亿个数据
[True,1,‘alex‘,{‘name‘:‘oldboy‘},[1,2,3],(2,3,4),{‘wusir‘}]
li = [111,‘alex‘,222,‘wusir‘]
print(li[1]) #alex
print(li[-1] #wusir
print(li[:2]) #[111,‘alex‘]
print(li[:3:2])
#增 删 改 查
l = [‘老男孩‘,‘alex‘,‘wusir‘,‘taibai‘,‘ritian‘]
#1、增
# append 在最后追加
l.append(‘葫芦‘)
l.append([1,2,3])
print(l)
[‘老男孩‘, ‘alex‘, ‘wusir‘, ‘taibai‘, ‘ritian‘, [111, 222]]
#insert 插入
l.insert(1,‘景nvshen‘)
print(l)
[‘老男孩‘, ‘景nvshen‘, ‘alex‘, ‘wusir‘, ‘taibai‘, ‘ritian‘]
#extend 迭代添加
l.extend(‘alex‘)
print(l)
[‘老男孩‘, ‘alex‘, ‘wusir‘, ‘taibai‘, ‘ritian‘, ‘a‘, ‘l‘, ‘e‘, ‘x‘]
l.extend([‘111‘,222,333])
print(l)
[‘老男孩‘, ‘alex‘, ‘wusir‘, ‘taibai‘, ‘ritian‘, ‘111‘, 222, 333]
#2、删
#pop 有返回值,按照索引删除
print(l.pop(0))
print(l)
[‘alex‘, ‘wusir‘, ‘taibai‘, ‘ritian‘]
#remove 按照元素删除
l.remove(‘alex‘)
print(l)
[‘老男孩‘, ‘wusir‘, ‘taibai‘, ‘ritian‘]
#clear 清空列表
l.clear()
print(l)
[]
#del 内存级别删除列表
del l
print(l) #报错,l在内存里不存在
#del 按索引删除
del l[1]
print(l)
[‘老男孩‘, ‘wusir‘, ‘taibai‘, ‘ritian‘]
#del 切片删除
del l[:3]
print(l)
[‘taibai‘, ‘ritian‘]
#3、改
#按照索引改
l[2] = ‘武藤兰‘
print(l)
[‘老男孩‘, ‘alex‘, ‘武藤兰‘, ‘taibai‘, ‘ritian‘]
#按照切片改
l[1:3] = [111,222,333,444]
print(l)
[‘老男孩‘, 111, 222, 333, 444, ‘taibai‘, ‘ritian‘]
#4、查
#按索引去查,按照切片去查询
for i in l:
print(i)
#其它方法:
l1 = [1,2,1,2,1,1,3,4]
#count 计数
print(l1.count(1))
#len
print(len(l1))
#通过元素找索引
print(l1.index(2))
#sort 列表排序
l2 = [3,2,4,6,9,8,7,1]
l2.sort() #从小到大
print(l2)
l2.sort(reverse=True) #从大到小
print(l2)
#reverse
l2.reverse()
print(l2)
#列表的嵌套
l1 = [1,2,‘alex‘,‘wusir‘,[‘oldboy‘,‘ritian‘,10],‘taibai‘]
#1,将‘alex‘全部变成大写,放回原处
l1[2] = ‘ALEX‘
l1[2] = l1[2].upper()
#2,给[‘oldboy‘,‘ritian‘,10]追加一个元素‘女神‘。一个方法
l1[-2].append(‘女神‘)
print(l1)
#3,将‘ritian‘首字母大写,放回原处
l1[-2][1] = ‘Ritian‘
l1[-2][1] = l1[-2][1].capitalize()
#4,将99通过数字相加,或者字符串相加或者等等,变成‘100’
l1[-2][-1] = str(l1[-2][-1] + 90)
l1[-2][-1] = str(l1[-2][-1]) + ‘0‘
print(l1)
05 tuple 元组:只读列表 不可增删改,
(True,1,‘alex‘,{‘name‘:‘oldboy‘},[1,2,3],(2,3,4),{‘wusir‘})
tu = (11,2,True,[2,3,4],‘alex‘)
for i in tu:
print(i)
print(tu[1])
print(tu[:3:2])
print(tu.index(True))
print(tu.count(2))
print(tu.index(True))
tu[-2].append(666)
print(tu)
06 dict 字典 可储存大量数据,关系型数据。查询速度非常快,符合二分查找(字典的键key是唯一的,key必须是不可变的数据类型(可哈希):str,bool,tuple,数字;value:任意数据类型)
引伸:
数据类型分类:
不可变的数据类型(可哈希):str,bool,tuple,int
可变的数据类型:dict,list,set
容器类数据类型:list,tuple,dict,set
#3.6版本之前无序的,3.6版本之后是有序的
{‘name‘:‘oldboy‘,‘age‘:45,‘name_list‘:[‘张三‘,‘李四‘,‘...‘]}
dic = {‘name‘:‘taibai‘,‘age‘:21,‘hobby‘:‘girl‘}
#增
dic[‘high‘] 有则覆盖,无则添加
dic[‘high‘] = 180
print(dic)
{‘name‘: ‘taibai‘, ‘age‘: 21, ‘hobby‘: ‘girl‘, ‘high‘: 180}
dic[‘name‘] = ‘ritian‘
print(dic)
{‘name‘: ‘ritian‘, ‘age‘: 21, ‘hobby‘: ‘girl‘}
dic.setdefault(‘high‘,180)
print(dic)
{‘name‘: ‘taibai‘, ‘age‘: 21, ‘hobby‘: ‘girl‘, ‘high‘: 180}
#删
pop #有返回值 是对应的值
dic.pop(‘name‘)
print(dic)
{‘age‘:21,‘hobby‘:‘girl‘}
小功能:如果删除的没有的情况不报错
dic.pop(‘name1‘,None) #返回值None自定义
print(dic)
clear #清空
dic.clear()
print(dic)
{}
del
del dic
print(dict) #报错
del dic[‘name‘]
print(dict)
{‘age‘: 21, ‘hobby‘: ‘girl‘}
dic.popitem() #随机删除,有返回值 3.6版本之后删除最后一个
print(dict)
{‘name‘: ‘taibai‘, ‘age‘: 21}
#改
#直接覆盖
dic[‘name‘] = ‘老男孩‘
#dic2.update(dic) 更新
dic = {"name":"jin","age":18,"sex":"male"}
dic2 = {"name":"alex","weight":75}
dic2.update(dic) # 将dic所有的键值对覆盖添加(相同的覆盖,没有的添加)到dic2中
print(dic)
{‘name‘: ‘jin‘, ‘age‘: 18, ‘sex‘: ‘male‘}
print(dic2)
{‘name‘: ‘jin‘, ‘weight‘: 75, ‘age‘: 18, ‘sex‘: ‘male‘}
#查
#键值查
print(dic[‘name‘])
#dic.get()
print(dic.get(‘name1‘,‘没有此key‘))
#循环查
keys() values() items()
print(list(dic.keys()))
for i in dic.key():
print(i)
print(list(dic.values()))
for i in dic.values ():
print(i)
print(list(dic.items()))
for i in dic.items ():
print(i)
#分别赋值
a,b =1,2
a,b,c = [‘alex‘,‘wusir‘,‘ritian‘]
a = 1
b = 5
ab值互换
a,b = b,a
for k,v in dic.items():
print(k,v)
#len
print(len(dic))
#fromkeys 创建字典
dic1 = dict.fromkeys(‘abc‘,‘张三‘)
print(dic1)
{‘a‘: ‘张三‘, ‘b‘: ‘张三‘, ‘c‘: ‘张三‘}
dic2 = dict.fromkeys([1,2,3],‘李四‘)
print(dic2)
{1: ‘李四‘, 2: ‘李四‘, 3: ‘李四‘}
dic3 = dict.fromkeys(‘abc‘,[]) 指向相同地址,修改一个列表
print(dic3)
{‘a‘: [], ‘b‘: [], ‘c‘: []}
课堂练习
dic = {
‘name_list‘:[‘b哥‘, ‘张帝‘, ‘人帅‘, ‘kitty‘],
‘老男孩‘:{
‘name‘:‘老男孩‘,
‘age‘: 46,
‘sex‘: ‘ladyboy‘,
},
}
#1,[‘b哥‘, ‘张帝‘, ‘人帅‘, ‘kitty‘]追加一个元素,‘骑兵‘
dic[‘name_list‘].append(‘骑兵‘)
print(dic)
#2,将kitty全部变成大写。
dic[‘name_list‘][-1] = dic[‘name_list‘][-1].upper()
print(dic)
#3,将老男孩 改成oldboy。
dic[‘老男孩‘][‘name‘] = ‘oldboy‘
print(dic)
#4,将ladyboy首字母大写。
dic[‘老男孩‘][‘sex‘] = dic[‘老男孩‘][‘sex‘].capitalize()
print(dic)
07 set 关系型数据的交集、并集、差集、子集... ... 而且可列表去重
集合:
无序,不重复的数据类型。他里面的元素必须是可哈希的。但是集合本身是可变的(不可哈希的)
存在的意义:
1)关系测试。交集并集,子集,差集
2)去重(列表的去重)
set1 = {1,‘alex‘,False,(1,2,3)}
l1 = [1,1,2,2,3,3,4,5,6,6]
set2 = list(set(l1))
print(set2)
[1, 2, 3, 4, 5, 6]
#增
set1 = {‘alex‘,‘wusir‘,‘ritian‘,‘egon‘,‘barry‘}
set1.add(‘景女神‘)
print(set1)
#update:迭代着增加
set1.update(‘A‘)
print(set1)
set1.update(‘老师‘)
print(set1)
set1.update([1,2,3])
print(set1)
#删
set1 = {‘alex‘,‘wusir‘,‘ritian‘,‘egon‘,‘barry‘}
set1.remove(‘alex‘) # 删除一个元素print(set1)
set1.pop() # 随机删除一个元素print(set1)
set1.clear() # 清空集合print(set1)
del set1 # 删除集合print(set1)
#交集
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2) # {4, 5}
#并集
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7, 8}
#差集
print(set1 - set2) # {1, 2, 3}
#反交集
print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
#子集与超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
#frozenset 冻集合,不可变集合
s = frozenset(‘barry‘)
print(s,type(s)) # frozenset({‘a‘, ‘y‘, ‘b‘, ‘r‘}) <class ‘frozenset‘>
08 bytes类型
#对于英文
s = ‘laonanhai‘
print(s,type(s))
s1 = b‘laonanhai‘
print(s1,type(s1))
09 编码
ascii:字母、数字、特殊字符。
万国码:unicode:
A:两个字节16位 0000 0010 0000 0010
中:两个字节
万国码升级:
A:四个字节16位 0000 0010 0000 0010 0000 0010 0000 0010
中:四个字节
占空间,浪费资源。
utf-8:最少用一个字节,表示一个字符
A:0000 0010 一个字节
欧洲:000 0010 0000 0010 两个字节
中文:000 0010 0000 0010 000 0010 三个字节
gbk国标:
A:0000 0010 一个字节
中:0000 0010 0000 0010 两个字节
python3x:
1)不同编码质检的二进制是不能互相识别的。
2)python3x str内部编码方式(内存)为unicode
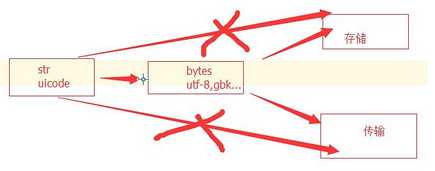
但是,对于文件的存储和传输不能用unicode(占位多,流量大)
bytes类型:内部编码方式(内存)为非unicode
#对于英文
str
s = ‘laonanhai‘表现形式
内部编码方式 unicode
bytes:
s1 = b‘laonanhai‘ bytes 表现形式
内部编码方式 非unicode
#对于中文:
str
s = ‘中国‘
print(s,type(s)
十六进制
#转化
s = ‘laonanhai‘
s2 = s.encode(‘utf-8‘) #str --> bytes encode 编码
s3 = s.encode(‘gbk‘)
print(s2,s3)
s = ‘中国‘
s2 = s.encode(‘utf-8‘) #str --> bytes encode 编码
s3 = s.encode(‘gbk‘)
print(s2) #utf-8 三个字节
print(s3) #两个字节
s = ‘中国‘
s2 = s.encode(‘utf-8‘) #str --> bytes encode 编码
ss = s2.decode(‘utf-8‘) #bytes --> str decode 解码
print(ss)
10 数据类型的补充
l1 = [‘alex‘,‘wusir‘,‘taibai‘,‘barry‘,‘老男孩‘]
#删除奇数位
1)方法一 切片删除
del l1[1::2]
print(l1)
[‘alex‘, ‘taibai‘, ‘老男孩‘]
2)方法二 生成l2
for i in range(len(11)):
if i % 2 ==1:
3)方法三 反向删
for i in range(len(l1)-1,-1,-1):
if i % 2 ==1:
del l1[i]
print(l1)
在循环一个列表时,不要对列表进行删除的动作(改变列表元素的个数)
引伸:range 可定制的数字列表,与for循环配合使用
for i in range(10)
print(i)
for i in range(1,10)
for i in range(1,10,2)
for i in range(10,1,-1)
print(range(10)) 可迭代对象,数字列表
#字典相关 在循环字典时,不要改变字典的大小
dic = {‘k1‘:‘v1‘,‘k2‘:‘v2‘,‘k3‘:‘v3‘,‘r‘:666}
键值含有k的
l1 = {}
for i in dic:
l1.append(i)
for i in l1:
del dic[i]
print (dic)
#tu相关 如果元组里面只有一个元素并且没有逗号隔开,那么它的数据类型与该元素一致
tu1 = (1)
print(tu1,type(tu1))
tu2 = (‘alex‘)
print(tu2,type(tu2))
tu3 = ([‘alex‘,1,2])
print(tu3,type(tu3))
11 小数据池,copy
小数据池只涉及int和str
id == is
a = ‘alex‘
b = ‘alex‘
print(a == b) #数值
print(a is b) #内存地址
print(id(a))
python中有小数据池概念
int: -5~256的相同的数圈都指向一个内存地址
str: s = ‘a‘ * 20 以内都是同一个内存地址
只要字符串含有非字母元素,那就不是一个内存地址
#深浅copy
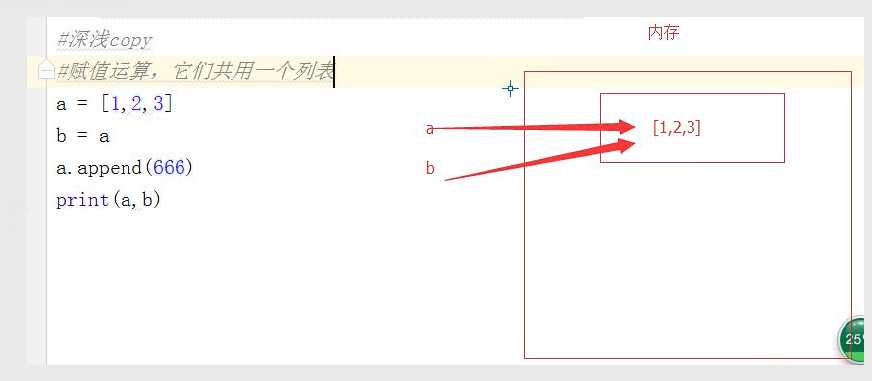
#赋值运算,它们共用一个列表
a = [1,2,3]
b = a
a.append(666)
print(a,b)
#浅copy
# 对于浅copy来说,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
l1 = [1,2,3]
l2 = l1.copy()
l1.append(666)
print(l1,l2)
print(id(l1),id(l2))
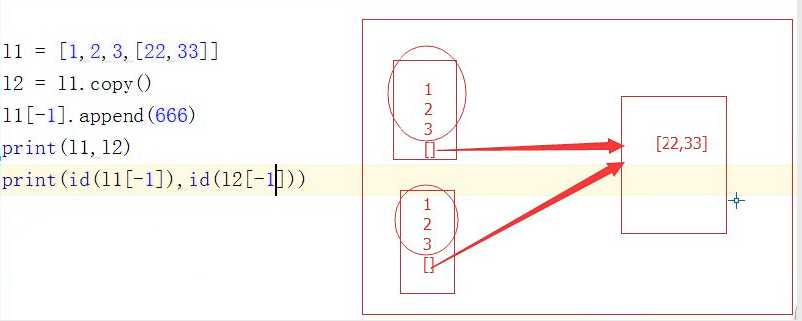
l1 = [1,2,3,[22,33]]
l2 = l1.copy()
l1.append(666)
print(l1,l2)
print(id(l1[-1]),id(l2[-1]))
#深copy
import copy
l1 = [1,2,3,[22,33]]
l2 = copy.deepcopy(l1)
l1.append(666)
print(l1,l2)
print(id(l1[-1]),id(l2[-1]))
Day02
标签:通过 相加 替换 inf inxi 覆盖 git src 深浅copy
原文地址:https://www.cnblogs.com/rainbow91/p/8825369.html