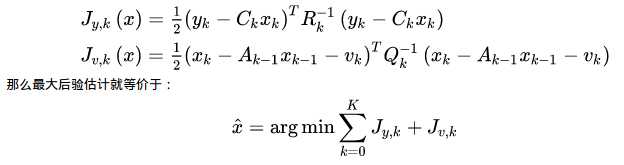标签:根据 targe image 分解 就会 旋转 lock 方式 没有
最一般的状态估计问题,我们会根据系统是否线性,把它们分为线性/非线性系统。同时,对于噪声,根据它们是否为高斯分布,分为高斯/非高斯噪声系统。现实中最常见的,也是最困难的问题,是非线性-非高斯(NLNG, Nonlinear-Non Gaussian)的状态估计。下面先说最简单的情况:线性高斯系统。
线性高斯系统在线性高斯系统中,运动方程、观测方程是线性的,且两个噪声项服从零均值的高斯分布。这是最简单的情况。简单在哪里呢?主要是因为高斯分布经过线性变换之后仍为高斯分布。而对于一个高斯分布,只要计算出它的一阶和二阶矩,就可以描述它(高斯分布只有两个参数 (其中过程可以参考贝叶斯法则-最大似然估计) 现在的问题是如何求解这个最大化问题。对于高斯分布,最大化问题可以变成最小化它的负对数。当我对一个高斯分布取负对数时,它的指数项变成了一个二次项,而前面的因子则变为一个无关的常数项,可以略掉(这部分我不敲了,有疑问的同学可以问)。于是,定义以下形式的最小化函数:
写成矩阵的形式,类似最小二乘的问题: 另一方面,能否直接求解(*)式,得到 |
滤波器自己的局限性:
那么,怎么克服以上的缺点呢?途径很多,主要看我们想不想维持EKF的假设。如果我们比较乖,希望维持高斯分布假设,可以这样子改:
如果不那么乖,可以说:我们不要高斯分布假设,凭什么要用高斯去近似一个长得根本不高斯的分布呢?于是问题变为,丢掉高斯假设后,怎么描述输出函数的分布就成了一个问题。一种比较暴力的方式是:用足够多的采样点,来表达输出的分布。这种蒙特卡洛的方式,也就是粒子滤波(PF)的思路。 |
| 非线性优化,计算的也是最大后验概率估计(MAP),但它的处理方式与滤波器不同。对于上面写的状态估计问题,可以简单地构造误差项: 非线性优化方法现在已经成为视觉SLAM里的主流,尤其是在它的稀疏性质被人发现且利用起来之后。它与滤波器最大不同点在于, 一次可以考虑整条轨迹中的约束。它的线性化,即雅可比矩阵的计算,也是相对于整条轨迹的。相比之下,滤波器还是停留在马尔可夫的假设之下,只用上一次估计的状态计算当前的状态。可以用一个图来表达它们之间的关系: |
标签:根据 targe image 分解 就会 旋转 lock 方式 没有
原文地址:https://www.cnblogs.com/Jessica-jie/p/8846772.html