标签:store 优化 ras err .com bitmap 一般来说 core tin
最近研究OpenGL ES相关和 GPU 相关 发现这篇文章很具有参考的入门价值.
首先要从Runloop开始说,iOS 的MainRunloop 是一个60fps 的回调,也就是说16.7ms(毫秒)会绘制一次屏幕,这个时间段内要完成:
view的缓冲区创建view内容的绘制(如果重写了 drawRect) 这些 CPU的工作.
然后将这个缓冲区交给GPU渲染, 这个过程又包含:
view的拼接(compositing)最终现实在屏幕上.因此,如果在16.7ms 内完不成这些操作, eg: CPU做了太多的工作, 或者view层次过于多,图片过于大,导致GPU压力太大,就会导致”卡”的现象,也就是 丢帧,掉帧.
苹果官方给出的最佳帧率是:60fps(60Hz),也就是一帧不丢, 当然这是理想中的绝佳体验.
60fps该怎么理解呢?一般来说如果帧率达到 25+fps(fps >= 25帧以上,不是25加别看错),人眼就基本感觉不到卡顿了,因此,如果你能让你的 iOS 程序稳定保持在30fps已经很不错了, 注释,是”稳定”在30fps,而不是, 10fps,40fps,20fps这样的跳动,如果帧频不稳就会有卡的感觉,60fps真的很难达到, 尤其是在 iPhone 4/4s等 32bit 位机上,不过现在苹果已经全面放弃32位,支持最低64位会好很多.
总的来说, UIView从绘制到Render的过程有如下几步:
UIView都有一个layerlayer都有个content,这个content指向的是一块缓存,叫做backing store. UIView的绘制和渲染是两个过程:
UIView被绘制时,CPU执行drawRect,通过context将数据写入backing storebacking store写完后,通过render server交给GPU去渲染,将backing store中的bitmap数据显示在屏幕上.上面提到的从CPU到GPU的过程可用下图表示:

下面具体来讨论下这个过程
假设我们创建一个 UILabel
|
UILabel* label = [[UILabel alloc]initWithFrame:CGRectMake(10, 50, 300, 14)];
label.backgroundColor = [UIColor whiteColor];
label.font = [UIFont systemFontOfSize:14.0f];
label.text = @"test";
[self.view addSubview:label];
|
这个时候不会发生任何操作, 由于 UILabel 重写了drawRect方法,因此,这个 View会被 marked as "dirty":
类似这个样子:
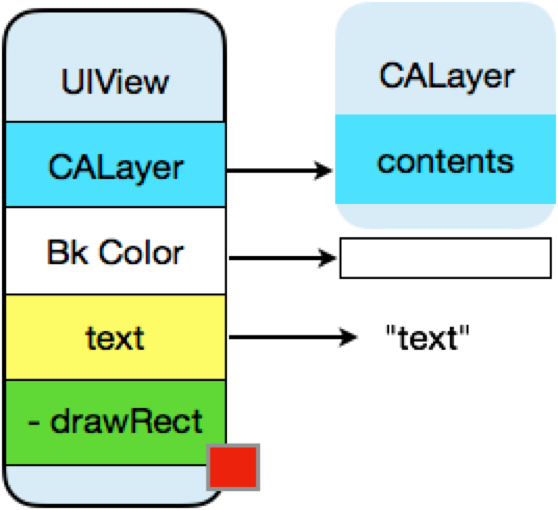
然后一个新的Runloop到来,上面说道在这个Runloop中需要将界面渲染上去,对于UIKit的渲染,Apple用的是它的Core Animation。
做法是在Runloop开始的时候调用:
|
[CATransaction begin]
|
在Runloop结束的时候调用
|
[CATransaction commit]
|
在begin和commit之间做的事情是将view增加到view hierarchy中,这个时候也不会发生任何绘制的操作。
当[CATransaction commit]执行完后,CPU开始绘制这个view:

首先CPU会为layer分配一块内存用来绘制bitmap,叫做backing store
创建指向这块bitmap缓冲区的指针,叫做CGContextRef
通过Core Graphic的api,也叫Quartz2D,绘制bitmap
将layer的content指向生成的bitmap
清空dirty flag标记
这样CPU的绘制基本上就完成了.
通过time profiler可以完整的看到个过程:
|
Running Time Self Symbol Name
2.0ms 1.2% 0.0 +[CATransaction flush]
2.0ms 1.2% 0.0 CA::Transaction::commit()
2.0ms 1.2% 0.0 CA::Context::commit_transaction(CA::Transaction*)
1.0ms 0.6% 0.0 CA::Layer::layout_and_display_if_needed(CA::Transaction*)
1.0ms 0.6% 0.0 CA::Layer::display_if_needed(CA::Transaction*)
1.0ms 0.6% 0.0 -[CALayer display]
1.0ms 0.6% 0.0 CA::Layer::display()
1.0ms 0.6% 0.0 -[CALayer _display]
1.0ms 0.6% 0.0 CA::Layer::display_()
1.0ms 0.6% 0.0 CABackingStoreUpdate_
1.0ms 0.6% 0.0 backing_callback(CGContext*, void*)
1.0ms 0.6% 0.0 -[CALayer drawInContext:]
1.0ms 0.6% 0.0 -[UIView(CALayerDelegate) drawLayer:inContext:]
1.0ms 0.6% 0.0 -[UILabel drawRect:]
1.0ms 0.6% 0.0 -[UILabel drawTextInRect:]
|
假如某个时刻修改了label的text:
|
label.text = @"hello world";
|
由于内容变了,layer的content的bitmap的尺寸也要变化,因此这个时候当新的Runloop到来时,CPU要为layer重新创建一个backing store,重新绘制bitmap.CPU这一块最耗时的地方往往在Core Graphic的绘制上,关于Core Graphic的性能优化是另一个话题了,又会牵扯到很多东西,就不在这里讨论了.
GPU bound:
CPU完成了它的任务:将view变成了bitmap,然后就是GPU的工作了,GPU处理的单位是Texture.
基本上我们控制GPU都是通过OpenGL来完成的,但是从bitmap到Texture之间需要一座桥梁,Core Animation正好充当了这个角色:Core Animation对OpenGL的api有一层封装,当我们要渲染的layer已经有了bitmap content的时候,这个content一般来说是一个CGImageRef,CoreAnimation会创建一个OpenGL的Texture并将CGImageRef(bitmap)和这个Texture绑定,通过TextureID来标识。
这个对应关系建立起来之后,剩下的任务就是GPU如何将Texture渲染到屏幕上了。GPU大致的工作模式如下:
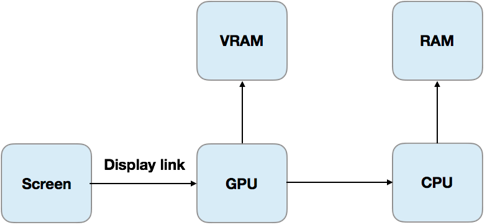
整个过程也就是一件事:
CPU将准备好的bitmap放到RAM里,GPU去搬这快内存到VRAM中处理。
而这个过程GPU所能承受的极限大概在16.7ms完成一帧的处理,所以最开始提到的60fps其实就是GPU能处理的最高频率.
因此,GPU的挑战有两个:
RAM搬到VRAM中Texture渲染到屏幕上 这两个中瓶颈基本在第二点上。渲染Texture基本要处理这么几个问题:
Compositing是指将多个纹理拼到一起的过程,对应UIKit,是指处理多个view合到一起的情况,如:
|
[self.view addsubview : subview]。
|
如果view之间没有叠加,那么GPU只需要做普通渲染即可.
如果多个view之间有叠加部分,GPU需要做blending.
加入两个view大小相同,一个叠加在另一个上面,那么计算公式如下:
R = S+D*(1-Sa)
R: 为最终的像素值S: 代表 上面的Texture(Top Texture)D: 代表下面的Texture(lower Texture)
其中S,D都已经pre-multiplied各自的alpha值。Sa代表Texture的alpha值。
假如Top Texture(上层view)的alpha值为1,即不透明。那么它会遮住下层的Texture.
即,R = S。是合理的。
假如Top Texture(上层view)的alpha值为0.5,S为(1,0,0),乘以alpha后为(0.5,0,0)。D为(0,0,1)。
得到的R为(0.5,0,0.5)。
基本上每个像素点都需要这么计算一次。
因此,view的层级很复杂,或者view都是半透明的(alpha值不为1)都会带来GPU额外的计算工作。
这个问题,主要是处理image带来的,假如内存里有一张400x400的图片,要放到100x100的imageview里,如果不做任何处理,直接丢进去,问题就大了,这意味着,GPU需要对大图进行缩放到小的区域显示,需要做像素点的sampling,这种smapling的代价很高,又需要兼顾pixel alignment。 计算量会飙升。
如果我们对layer做这样的操作:
|
label.layer.cornerRadius = 5.0f;
label.layer.masksToBounds = YES;
|
会产生offscreen rendering,它带来的最大的问题是,当渲染这样的layer的时候,需要额外开辟内存,绘制好radius,mask,然后再将绘制好的bitmap重新赋值给layer。
因此继续性能的考虑,Quartz提供了优化的api:
|
label.layer.cornerRadius = 5.0f;
label.layer.masksToBounds = YES;
label.layer.shouldRasterize = YES;
label.layer.rasterizationScale = label.layer.contentsScale;
|
简单的说,这是一种cache机制。
同样GPU的性能也可以通过instrument去衡量:

红色代表GPU需要做额外的工作来渲染View,绿色代表GPU无需做额外的工作来处理bitmap。
全文完
https://www.sunyazhou.com/2017/10/16/20171016UIView-Rendering/
标签:store 优化 ras err .com bitmap 一般来说 core tin
原文地址:https://www.cnblogs.com/feng9exe/p/8848684.html