标签:tps UNC family 垃圾邮件 功能 .net 匹配 邮件 csdn
知道BloomFilter是因为RocksDB数据库中用到了这个技术,用于判断1个数据是否存在于1个SST文件中。
BloomFilter可能存在误判,就是判断数据是存在集合中,而实际上可能不存在,概率是很低的。但是判断不存在,则一定就是不存在集合中的。
资料查阅后,BloomFilter还可以用于网络爬虫,用于URL去重。垃圾邮件,关键字检查,es的percolator也可以完成关键字匹配和预警。
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。
对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。
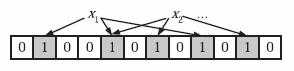
在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。
下图中y1就不是集合中的元素。y2可能属于这个集合,或者刚好是一个误判。
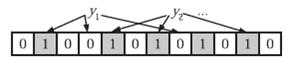
这个还是比较好理解的,某hash函数后的结果为0,表示使用该hash函数时。目标数据的hash结果,和集合中所有数据的hash结果都不同。
数据加入了就被不能删除了,因为删除会影响到其他数据,不知道是否其他数据也映射到了该位置,即BloomFilter不支持删除。
实在需要删除字符串的可以使用Counting bloomfilter(CBF),这是一种基本BloomFilter的变体,CBF将基本BloomFilter每一个Bit改为一个计数器,这样就可以实现删除字符串的功能了。
数组的长度和hash函数的个数该怎样取值,才能满足误判率的要求,是要研究数学公式的,就不深究了。可以参见下面的链接
https://blog.csdn.net/jiaomeng/article/details/1495500
标签:tps UNC family 垃圾邮件 功能 .net 匹配 邮件 csdn
原文地址:https://www.cnblogs.com/lnlvinso/p/8849737.html