标签:col 版本 生态 system 应用 处理 子项目 执行 扩展性
什么是Hadoop?
hadoop是Apache 开源发布的分布式系统基础架构。它实现了分布式文件系统(hadoop Distributed File System,HDFS),分布式系统是运行在多个主机上的软件系统。HDFS有着高容错性的特点,能够保存多个副本,并可以将自动失败的任务重新分配。Hadoop可以部署在低廉通用的硬件平台上组成集群,提供热拔插的方式增加新的节点来向集群中扩展,将任务动态的分配到各节点中,并保证各节点的动态平衡,因此Hadoop具有低成本,高扩展性,高效性,高容错性的特点。
Hadoop的体系结构
hadoop的核心
HDFS和MapReduce是Hadoop的两大核心,Hadoop通过HDFS来实现对分布式存储的底层支持,达到高速并行读写与大容量的存储扩展,通过MapReduce来对分布式并行任务处理程序的支持,保证高速分析处理数据。HDFS又对MapReduce任务处理中提供了对文件操作和存储的支持。MapReduce在HDFS的基础上实现了任务的分发,跟踪,执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
Hadoop的子项目
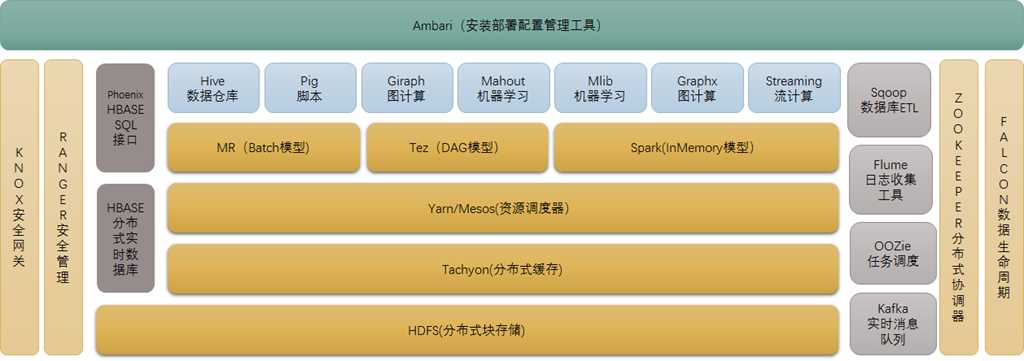
Hadoop组件远不止这些,经过这么多年发展,更多的项目加入Hadoop生态圈,HBase,HDFS,MapReduce为Hadoop的三个重要组件,先习得这三个在深入Hadoop,对于开发来说这三个也是最基本的模块。
Hadoop版本
| Hadoop | 大版本 | 说明 |
| 第二代Hadoop2.0 | 2.x.x | 下一代Hadoop由0.23.x演化而来 |
| 0.23.x | 下一代Hadoop | |
| 第一代Hadoop1.0 | 1.0.x | 稳定版,由0.20.x演化而来 |
| 0.22.x | 非稳定版本 | |
| 0.21.x | 非稳定版本 | |
| 0.20.x | 经典版本,最后演化为1.0.x |
卒
标签:col 版本 生态 system 应用 处理 子项目 执行 扩展性
原文地址:https://www.cnblogs.com/zzhblog/p/8819638.html