标签:部分 优先级 示例 控制器 注册 构建 生命周期 自定义 之间
云原生(Cloud Native)的高阶实践是分布式服务化架构。一个良好的服务化架构,需要良好的服务发现、服务治理、服务编排等核心能力。本文为读者解析网易云的服务治理策略及其典型实践。
在优化了版本控制策略,研发并集成了自动化构建和发布工具,实现“项目工程化”之后,网易云开始了分布式服务化架构的探索,希望解决支撑海量用户及产品高速迭代需求下的软件研发成本高、测试部署维护代价大、扩展性差等问题。
业务模块的独立,自然而然形成了基于 Docker 容器的微服务架构。网易云简化的微服务架构如图 1 所示,包括服务注册与发现、分布式配置管理、负载均衡、服务网关、断路器等模块。
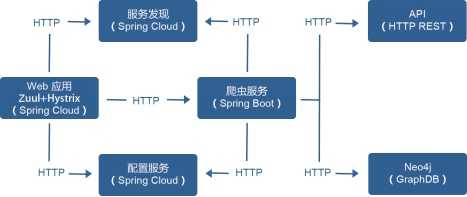
图 1 微服务架构
一个产品通常由多个应用组成,容器只是提供一个应用服务的能力,需要把多个应用组合编排起来才能提供服务。在服务编排上,网易云选择开源的 Kubernetes 。Kubernetes 是自动化编排容器应用的开源平台,这些操作不仅包括部署、调度和节点集群间扩展,还包括服务发现和配置服务等架构支持的基础能力。Kubernetes 对应用层面的关注、对微服务、云原生的支持及其生态,正是网易云所需要的。
在微服务架构下,随着业务逐渐复杂,服务数量越来越多,引入的问题也越来越复杂。如何在业务发展的同时保障服务的 SLA 和最大化利用机器资源,是摆在网易云面前一个很大的挑战。我们需要一个统一的服务治理机制对所有服务进行统一管控,保障服务正常运行。
服务治理范围覆盖了服务的整个生命周期,从服务建模开始,到开发、测试、审批、发布、运行时管理,以及最后的下线。我们通常说的服务治理主要是指服务运行时的治理,一个好的服务治理框架要遵循“在线治理,实时生效”原则,只有这样才能真正保障服务整体质量。下面介绍服务治理策略在服务运行时的应用。
基于负载均衡的应用弹性伸缩方案,只要将应用系统设计成无状态,在需要伸缩的时候修改负载均衡代理配置,就可以方便地水平扩容应用系统,提高系统承载能力。
在云原生应用架构里,我们其实有更多的选择。对于无状态服务,配合云平台提供的 AutoScaling 能力,能够快速弹性扩容,实施 DevOps。在这里,弹性扩缩容是一种重要的服务治理手段。网易云选择基于 Kubernetes 的 AutoScaling 机制实现弹性伸缩。
网易云采用 Kubernetes 实现应用管理,而 Kubernetes 的 Horizontal Pod Autoscaler (HPA)组件专门设计用于应用弹性扩容的控制器,它通过定期轮询 Pod 的状态(CPU、内存、磁盘、网络,或者自定义的应用指标),当 Pod 的状态连续达到提前设置的阈值时,就会触发副本控制器,修改其应用副本数量,使得 Pod 的负载重新回归到正常范围之内。如图 2 所示。
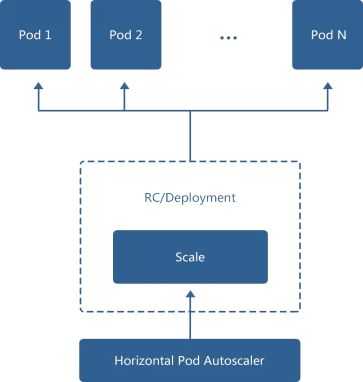
图 2 基于 Kubernetes 的弹性扩缩容
例如促销活动服务的应用层是一个无状态应用,当前有两个副本,我们把弹性扩容的 CPU 使用率阈值设置为 50%。但是促销当天涌入的流量远远超过预期,使得两个副本的 CPU 使用率分别达到了 80%以上,HPA 控制器监控到这种变化,于是通知副本控制器将促销活动服务的副本数量升到 4 个。当流量峰值过后,4 个副本的 CPU 使用率慢慢降到 10% 以下,HPA 控制器计算得出两个副本即可满足负载要求,于是通知副本控制器将应用副本数量变为 2。
HPA控制器的副本伸缩算法可以参考Kubernetes文档。
微服务架构中,各服务通过服务发现的方式互相依赖,虽然从单个服务看来能获得非常好的隔离性,不会因为某个进程或者服务宕掉对其他服务造成直接影响,但是从业务角度来看,单个服务实例故障还是可能造成业务访问出现问题,轻则影响服务调用方出现延迟和负载上升,重则造成业务整体异常。
比如,一个简单的电商场景,用户通过网站下单购买一件商品,首先将调用订单服务生成一个订单,调用支付网关完成支付,最后调用库存服务将库存量减去。在这一系列服务调用过程中,任何一个子服务因为网络故障或者服务本身异常等情况出现,都会导致用户购物车服务线程阻塞,不仅影响到用户这次购物行为失败,如果此时有大量用户同时访问,还会造成后续请求的失败。这是微服务调用中很容易出现的级联失败。针对这个问题,网易云引入了服务治理中的熔断机制,或者叫断路器模式,断路器在系统架构中的应用如图2所示。
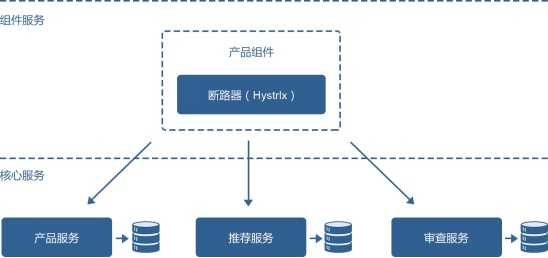
图3 断路器在系统架构中的应用
断路器是一个开关,本意是指电路系统上的一种保护线路电流过载的一种装置,当线路中电流太大或者发生短路时,断路器开关打开,电路切断,防止引起更加严重的后果。引申到微服务治理策略中,断路器的作用就是避免故障或者异常在微服务调用链中蔓延。它的工作机制如图4 所示。
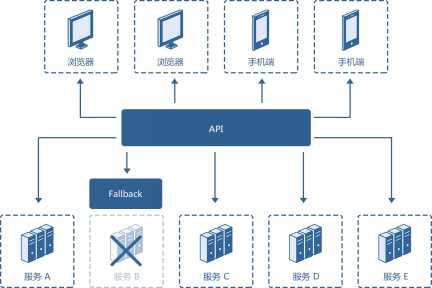
图4 服务治理中的熔断机制
服务调用方在尝试调用远端服务时,同时提供一个 fallback 方法,就是当远端服务出现故障时,调用 fallback 方法,快速返回结果,避免级联效应,使故障隔离。同时,断路器应该需要提供一个阈值开关,当远端服务的调用连续失败次数超过某个阈值时,服务调用方直接调用 fallback 方法,不再请求远端服务。等远端服务恢复后,再恢复正常调用流程。
在一些场景下,网易云借助 Netflix OSS 的 Hystrix 实现断路器。Hystrix 是 Netflix 开源的库,主要提供分布式服务间交互的延时容忍与容错机制,隔离了服务间的访问入口,防止整个链路上某服务调用不通导致系统雪崩,提供 fallback(降级)机制以便增强系统弹性。另外,还提供了服务治理与监控功能。
Hystrix 主要提供以下几个功能。
代码示例如下。
@Component
public class ShoppingService {
@HystrixCommand(fallbackMethod = "payFail")
public Object pay(Map parameters) {
//远程调用支付服务
return;
}
public Object payFail(Map parameters) {
//支付失败,订单状态改为未支付
return;
}
}
购物服务调用 ShoppingService 的 pay()方法实现支付,支付成功则订单状态置为待发货,若支付过程中支付网关服务出现异常,导致 pay()方法调用失败,ShoppingService 的断路器会调用 payFail()方法实现失败处理,将订单状态改为未支付状态,后续用户可以通过界面选择订单继续支付。如果支付网关服务较长时间无法恢复,当 pay()连续失败次数超过阈值,熔断机制开启,断路器打开,每次对 ShoppingService 的 pay()方法的调用退化为对payFail()方法的调用,直至支付网关服务恢复正常。熔断机制在服务治理中的作用主要体现在对故障的隔离上,避免调用出现链式雪崩。
服务降级也是服务治理策略中重要的一环。当业务出现流量峰值,或者系统中某个组成部分出现故障,保证系统整体功能仍然可用,我们可能需要停掉一些不太重要的周边系统,从而保证核心服务的 SLA。比如电商系统在进行大促时,往往会弃车保帅,优先选择停止“猜你喜欢”、“评论”等不那么重要的系统,保障购物车、支付系统可用。在微服务架构里,每个服务无论是服务提供方还是服务调用方,都应该围绕 SLA 制定不同的降级策略。按降级粒度粗细我们可以制定接口降级、功能降级、服务降级。
其中,功能降级和服务降级可以通过熔断机制和断路器实现。

本文节选自网易云基础服务架构团队所著《云原生应用架构实践》,有改动。
标签:部分 优先级 示例 控制器 注册 构建 生命周期 自定义 之间
原文地址:https://www.cnblogs.com/163yun/p/8868432.html