标签:deb tor rom pre down ext show response should
最近想吃烤肉,所以想看看深圳哪里的烤肉比较好吃,于是自己就开始爬虫咯。这是个静态网页,有反爬机制,我在setting和middlewares设置了反爬措施
Setting
# -*- coding: utf-8 -*- # Scrapy settings for dazhong project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = ‘dazhong‘ SPIDER_MODULES = [‘dazhong.spiders‘] NEWSPIDER_MODULE = ‘dazhong.spiders‘ # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.3964.2 Safari/537.36‘ # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 10 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, # ‘Accept-Language‘: ‘en‘, #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # ‘dazhong.middlewares.DazhongSpiderMiddleware‘: 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { ‘scrapy.downloadermiddleware.useragent.UserAgentMiddleware‘: None, ‘dazhong.middlewares.MyUserAgentMiddleware‘: 400, } # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # ‘scrapy.extensions.telnet.TelnetConsole‘: None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { ‘dazhong.pipelines.DazhongPipeline‘: 200, } # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = ‘httpcache‘ #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage‘ MY_USER_AGENT = [‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.3964.2 Safari/537.36‘]
ITEM
import scrapy class DazhongItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() name = scrapy.Field() location = scrapy.Field() people = scrapy.Field() money = scrapy.Field() taste = scrapy.Field() envir = scrapy.Field() taste_score = scrapy.Field() service = scrapy.Field()
Spider:
# -*- coding: utf-8 -*- import scrapy import re from bs4 import BeautifulSoup from scrapy.http import Request from dazhong.items import DazhongItem class DzSpider(scrapy.Spider): name = ‘dz‘ allowed_domains = [‘www.dianping.com‘] #headers = {‘USER-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.3964.2 Safari/537.36‘} #custom_settings = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.3964.2 Safari/537.36‘} first_url = ‘http://www.dianping.com/shenzhen/ch10/g114‘ last_url = ‘p‘ def start_requests(self): for i in range(1,45): url = self.first_url + self.last_url + str(i) yield Request(url,self.parse) def parse(self, response): soup = BeautifulSoup(response.body.decode(‘UTF-8‘),‘lxml‘) for site in soup.find_all(‘div‘,class_=‘txt‘): item = DazhongItem() try: item[‘name‘] = site.find(‘div‘,class_=‘tit‘).find({‘h4‘}).get_text() item[‘location‘] = site.find(‘div‘,class_=‘tag-addr‘).find(‘span‘,class_=‘addr‘).get_text() item[‘people‘] = site.find(‘div‘,class_=‘comment‘).find(‘a‘).find(‘b‘).get_text() item[‘money‘] = site.find(‘div‘,class_=‘comment‘).find_all(‘a‘)[1].find(‘b‘).get_text() item[‘taste‘] = site.find(‘div‘,class_= ‘tag-addr‘).find(‘a‘).find(‘span‘).get_text() item[‘envir‘] = site.find(‘span‘,class_= ‘comment-list‘).find_all(‘span‘)[1].find(‘b‘).get_text() item[‘taste_score‘] = site.find(‘span‘,class_= ‘comment-list‘).find_all(‘span‘)[0].find(‘b‘).get_text() item[‘service‘] = site.find(‘span‘,class_= ‘comment-list‘).find_all(‘span‘)[2].find(‘b‘).get_text() yield item except: pass
PIPELINE:
from openpyxl import Workbook class DazhongPipeline(object): # 设置工序一 def __init__(self): self.wb = Workbook() self.ws = self.wb.active self.ws.append([‘店铺名称‘,‘地点‘,‘评论人数‘,‘平均消费‘,‘口味‘,‘环境评分‘,‘口味评分‘,‘服务评分‘,]) # 设置表头 def process_item(self, item, spider): # 工序具体内容 line = [item[‘name‘],item[‘location‘],item[‘people‘],item[‘money‘],item[‘taste‘],item[‘envir‘],item[‘taste_score‘],item[‘service‘]] # 把数据中每一项整理出来 self.ws.append(line) # 将数据以行的形式添加到xlsx中 self.wb.save(‘dazhong.xlsx‘) # 保存xlsx文件 return item def spider_closed(self, spider): self.file.close()
middlewares:
import scrapy from scrapy import signals from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware import random class MyUserAgentMiddleware(UserAgentMiddleware): def __init__(self, user_agent): self.user_agent = user_agent @classmethod def from_crawler(cls,crawler): return cls( user_agent = crawler.settings.get(‘MY_USER_AGENT‘) ) def process_request(self, request, spider): agent = random.choice(self.user_agent) request.headers[‘User-Agent‘] = agent
那些没有环境评分、服务评分数据的也就跳过了,爬来没意义
结果如下:
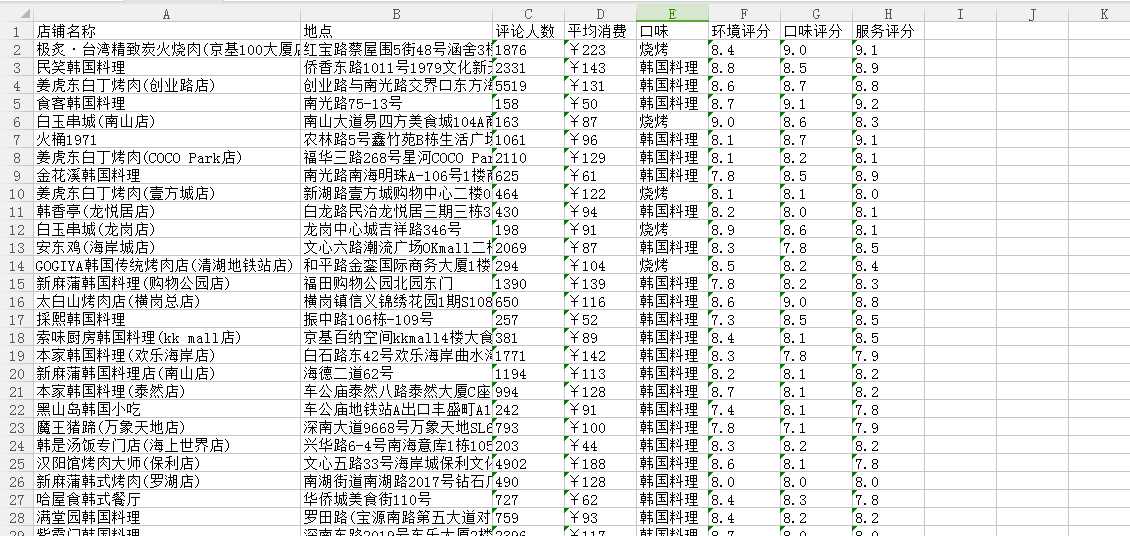
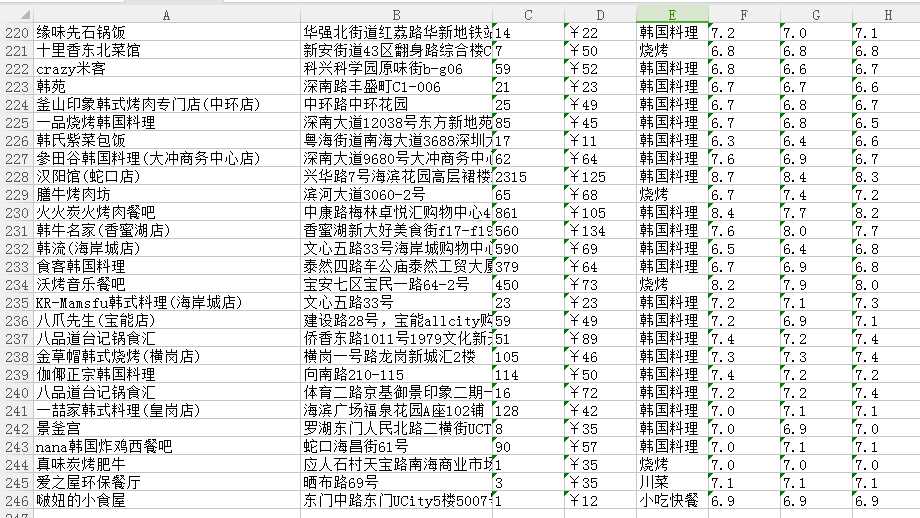
决定去吃姜虎东
标签:deb tor rom pre down ext show response should
原文地址:https://www.cnblogs.com/annebang/p/8870793.html