标签:blog http 使用 ar strong 数据 sp 2014 问题
真实的训练数据总是存在各种各样的问题:
1、 比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余。
2、 拿到一个数学系的本科生期末考试成绩单,里面有三列,一列是对数学的兴趣程度,一列是复习时间,还有一列是考试成绩。我们知道要学好数学,需要有浓厚的兴趣,所以第二项与第一项强相关,第三项和第二项也是强相关。那是不是可以合并第一项和第二项呢?
3、 拿到一个样本,特征非常多,而样例特别少,这样用回归去直接拟合非常困难,容易过度拟合。比如北京的房价:假设房子的特征是(大小、位置、朝向、是否学区房、建造年代、是否二手、层数、所在层数),搞了这么多特征,结果只有不到十个房子的样例。要拟合房子特征->房价的这么多特征,就会造成过度拟合。
4、 这个与第二个有点类似,假设在IR中我们建立的文档-词项矩阵中,有两个词项为“learn”和“study”,在传统的向量空间模型中,认为两者独立。然而从语义的角度来讲,两者是相似的,而且两者出现频率也类似,是不是可以合成为一个特征呢?
5、 在信号传输过程中,由于信道不是理想的,信道另一端收到的信号会有噪音扰动,那么怎么滤去这些噪音呢?
对于这些特征存在噪声和冗余的问题,通常使用主成份分析(PCA)来解决。通过主成份分析,能够将原有的n个相关变量通过线性变换,转换为较少的k个主成份的方法。这些主成份包含原始变量的绝大部分信息,通常表示为原始变量的线性组合。
PCA是通过一种统计方法,对多变量表示数据点集合寻找尽可能少的正交矢量表征数据信息特征。将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法。
PCA的目的:1.对变量的降维;2.主成份的解释
PCA的思想是将n维特征映射到k维上(k),这k维是全新的正交特征。这k维特征称为主元,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征。
对于二维数据:
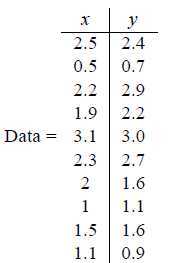
1 减均值:
对其进行求均值,并且所有的数据减去相应均值:

2 归一化:
求标准差,并且所有数据除以相应标准差:

3 求特征协方差矩阵
C = [ cov(x,x) cov(x,y)
cov(y,x) cov(y,y) ];
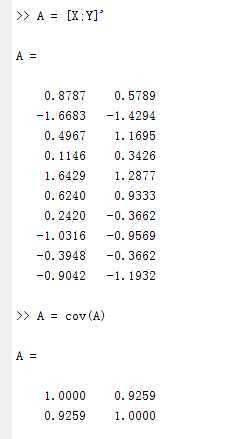
4 求协方差矩阵特征值和特征向量

得到两个特征向量:[-0.7071;0.7071]对应特征值0.0741
[0.7071;0.7071]对应特征值1.9259
5 将特征值从大到小排序,选择其中最大的k个,将对应的k个特征向量分别做列向量,得到特征向量矩阵
6 计算结果
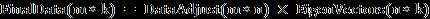
其中DataAdjust是归一化后的矩阵,EigenVectors是特征向量矩阵
PCA的主要目的就是减少变量个数,选择方差较大的主成份来分析,忽略一些方差较小的(认为是噪声)的成分,有效避免噪声和冗余。主成份不会对总的方差带来很大的影响。通过PCA对数据进行降维处理,可以有效压缩数据。
PCA的优点:无任何参数设置,在PCA计算过程中不需要人为的加入参数,不需要一些经验数据;
PCA的缺点:如果用户有一些先验经验,也同样无法通过设定参数来对结果进行干预。
1 http://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html
2 http://www.cnblogs.com/jerrylead/archive/2011/04/18/2020216.html
3 http://blog.sina.com.cn/s/blog_670445240101lgsa.html
http://blog.sina.com.cn/s/blog_66035a700100hupi.html
标签:blog http 使用 ar strong 数据 sp 2014 问题
原文地址:http://www.cnblogs.com/lyon2014/p/3991040.html