标签:区域 参考 针对 输出 计划 求和 学习方法 back 做了
题目连接:http://codecraft.devcloud.huaweicloud.com/home/detail
比赛历程:找了室友和一个电院的朋友组队,一共差不多一个月的时间,平时一般白天做自己的事,晚上花一两个小时写写改改,期间每一个星期找一天晚上一起讨论一下 下周的工作计划。
由于本次比赛主要是机器学习类别,最开始决定用python的时候还挺虚的,毕竟从来没用过,然后花了大概一个早上的时间【绝对没有吹**,没看第三方包,反正比赛也不让用,有面向对象基础学python真的很快】把基本语法都熟悉一遍后就根本停不下来!!这货比java好用到哪里去了!!推荐一本快速入门的书籍《笨方法学Python》,嗯。。很笨很快。。
题目思路:首先要分析题目的背景,是华为的云服务器的一个使用预测问题,再看看期望输出又涉及到如何能让物理服务器使用率最大,也就是放置问题。
所以此题算法的主要区域可大致分为:预测+放置
额外,我们还得考虑其他一些步骤,由于读文件官方已经帮我们做了,我们只需要填写处理方法,所以综合如下:
各数据获取 + 统计 + 去噪 + 预测 + 放置 + 获取结果集
最终成绩:240.5分 52名 ps:西北赛区的64名分数比其他区36名分数还高我也是醉,高考大省既视感。。。
练习赛中我们写了各种模型,一直成绩都还不错(前20左右),到正式比赛前一天还美滋滋的以为咱们至少36名保底进复赛,结果。。。嗯,可能过拟合了。。。
各模块思路以及注意事项:
由于成绩并不理想也就不贴代码了,在此给出各模块思路以及注意事项,以后要是有时间再考虑把代码弄GitHub上去。
数据获取:
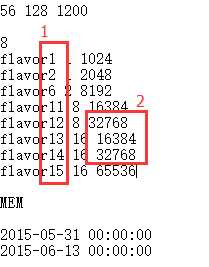
思路——主要是根据规格文件获取历史记录中每一天的每类flavor用量,在此推荐使用嵌套list。使用字典也行,但是由于python中的字典和java的map类似不会主动排序,所以一般是乱序的,而后续操作经常需要随机访问数据,所以不建议使用。
注意事项——1、规格文件中flavor并不一定是连续的,2虽然CPU的数量是按照flavor规格顺序来的,但是MEM数量却不一定,所以,我们应该在统计的时候将此flavor_list进行相关排序,以此方便后续的放置操作。3、规格文件中物理服务器MEM的单位是Gb,而flavor的规格中mem的却是Mb,所以在统计flavor规格的时候建议除以1024.
统计:
思路——有很多种方法,最简单地就是根据规格文件的最后两行获得的预测时间段,按每一段对之前每一天的数据进行求和,以此得到每一段的数据。
我们还用了一种就是交叉重叠取段,同样是取预测时间段为段,但是下一段与这一段的关系却不是相邻,而是交叉重叠,这样就能很好的解决使用机器学习算法但是练习数据却不够多的情况。
注意事项——这里主要就是要细心,注意边界问题,和注意语法
去噪:
去噪分两步:获取噪声和去除噪声,我们写了以下几种方法:
获取:【一刀切】——每一段数据超过某个阈值,就算噪声点
【一挑多】——每一段中,如果有某个数据的值比其他所有的点加起来还要大,就算噪声点;
【四分位数】——将所有数据取峰值与最低值,四分段,…………网上很多,不赘述
【高斯】——实现效果太差
【n阶指数平滑】——实现效果太差
去噪:直接丢、取此段平均、取此段除它以外的平均。
最后效果貌似【一挑多】+ 取此段除它以外的平均 效果比较好
预测:
我们一共写了以下一些模型:
【线性加权】、【bp神经网络】、【线性回归】、【RNN】、【多项式回归】、【三阶指数平滑】
其中bp、线性回归在练习赛中表现就不佳,就抛弃了。然后在初赛的第一天。。。。除了最简单的线性加权和三阶质数平滑,其他模型全部分数低,我估计是过拟合了。。。然而又只有第二天的5次提交机会,不敢冒险,最后选取三阶指数平滑利用几次机会调整了下参数,最后取了最高的。
放置:
写了两个,一开始写了个简单的【首次适应】(先放大的,再放小的),后来大家有时间又写了个【多背包】(还有很多方法都行,但是就此比赛而言,效果是差不多的,所以就只用了这两个),讲道理来说多背包应该比首次适应更优秀,但是最后分数一样?于是在一次讨论中,发现了神奇的地方:————判分公式
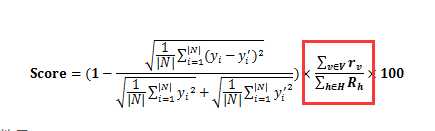
总的占用除以总的请求的物理服务器空间??,意思就是不管我每个物理服务器是否放满,只要两个方法最后申请的服务器数量是一样的,那么这两个方法的分数就是一样的!
于是我们想到一个方法能让红色框的比率为100%————【少扔多补法】当申请数大于1时,如果用多背包放置完毕后最后一个背包的剩余空间大于一半,就把背包内的虚拟机都扔了,否则就补上,这样一来分数就又上去了,又回到了榜上前20。之前看着判分公式很复杂就没管,所以做比赛还是得仔细看看判分规则。
注意事项:放置的时候除了目标优化的,还要注意另外一个属性是否还能放。例如:放128的CPU,但是MEM却已经超分。
获取结果集
略。
最终成绩选取方案:交叉统计 + 一挑多取噪 + 取其他平均去噪 + 三阶指数平滑 + 多背包放置 + 少扔多补调整
语法注意事项:
可能存在的加分点:
赛后才想起来:练习赛中给我们的数据都是2015年的,而华为云在2011才开始投入使用,所以在2015年使用增长率和其他年份肯定不一样,我们模型中对应的参数也就不一样,很可能最后比赛用的就是上年2017的数据,所以后来听别人说在预测上直接每个虚拟机加几个能涨分。。。。。所以根据数据的年份设置初始权重和变化率可能分数能再高点。当然这也只是我的猜测,赛后才想到,无从验证。
对华为软赛建议:
正式比赛中华为只给出了5次提交的机会,应该是希望我们的模型应用范围广就是不要出现过拟合现象。减少提交次数是一种不错的方法,但是对于这个问题我有一个可能不成熟的建议就是对于机器学习类别的比赛应该采用A/B榜进行排名【可参考阿里天池大数据竞赛】采用随机分割或者时序分割的方式在同一数据中心分割出两份用例,第一份用于比赛各队伍进行调试排名也就是A榜,第二份在比赛截至后生成最终排名也就是B榜,比赛过程中,各队看不见B榜数据,所以针对A榜进行调参是没意义的。
总结:
还记得上一次参加类似比赛那是在本科了,重温这种感觉还是不错的,虽然最后结果并不理想,但是期间的与队友们协同讨论解决问题的过程和在期间短时间内对学习能力的锻炼对于每个人都是十分宝贵的财富,对于新知识的学习方法和对问题思考的角度深度都得到不错的锻炼。
感谢队友们这一路的相互帮助、理解,感谢华为公司提供此次学习与交流的机会。
标签:区域 参考 针对 输出 计划 求和 学习方法 back 做了
原文地址:https://www.cnblogs.com/Xieyang-blog/p/8870881.html