标签:不同 mis ilo imp 特定 form res 支持 tran
对于缺失值的处理上,主要配合使用sklearn.preprocessing中的Imputer类、Pandas和Numpy。其中由于Pandas对于数据探索、分析和探查的支持较为良好,因此围绕Pandas的缺失值处理较为常用。
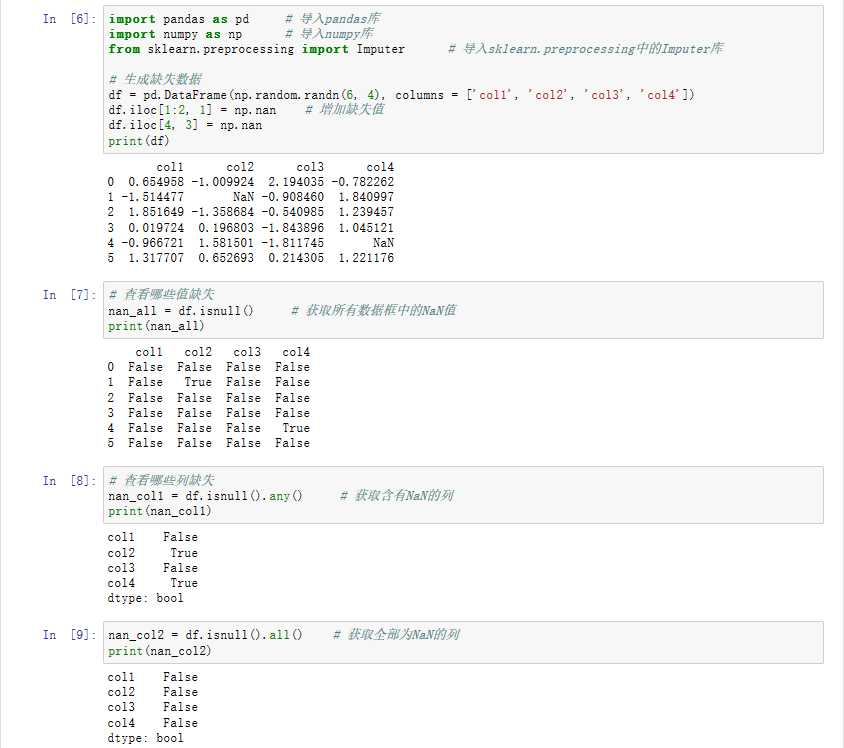
import pandas as pd # 导入pandas库
import numpy as np # 导入numpy库
from sklearn.preprocessing import Imputer # 导入sklearn.preprocessing中的Imputer库
# 生成缺失数据
df = pd.DataFrame(np.random.randn(6, 4), columns=[‘col1‘, ‘col2‘,‘col3‘, ‘col4‘]) # 生成一份数据
df.iloc[1:2, 1] = np.nan # 增加缺失值
df.iloc[4, 3] = np.nan # 增加缺失值
print (df)
# 查看哪些值缺失
nan_all = df.isnull() # 获得所有数据框中的N值
print (nan_all) # 打印输出
# 查看哪些列缺失
nan_col1 = df.isnull().any() # 获得含有NA的列
nan_col2 = df.isnull().all() # 获得全部为NA的列
print (nan_col1) # 打印输出
print (nan_col2) # 打印输出
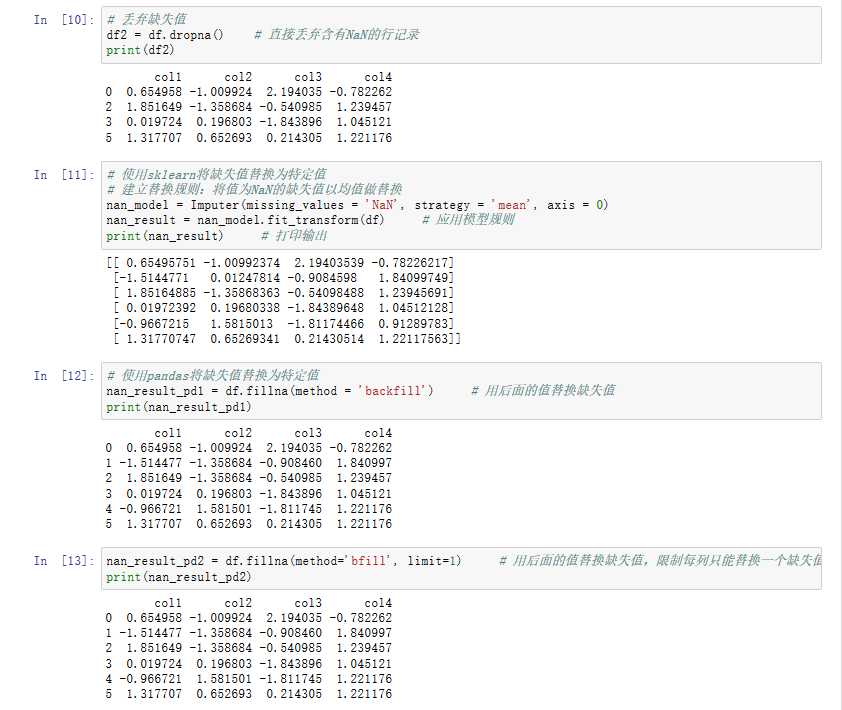
# 丢弃缺失值
df2 = df.dropna() # 直接丢弃含有NA的行记录
print (df2)
# 使用sklearn将缺失值替换为特定值
nan_model = Imputer(missing_values=‘NaN‘, strategy=‘mean‘,axis=0) # 建立替换规则:将值为Nan的缺失值以均值做替换
nan_result = nan_model.fit_transform(df) # 应用模型规则
print (nan_result)
# 使用pandas将缺失值替换为特定值
nan_result_pd1 = df.fillna(method=‘backfill‘) # 用后面的值替换缺失值
nan_result_pd2 = df.fillna(method=‘bfill‘, limit=1) # 用后面的值替代缺失值,限制每列只能替代一个缺失值
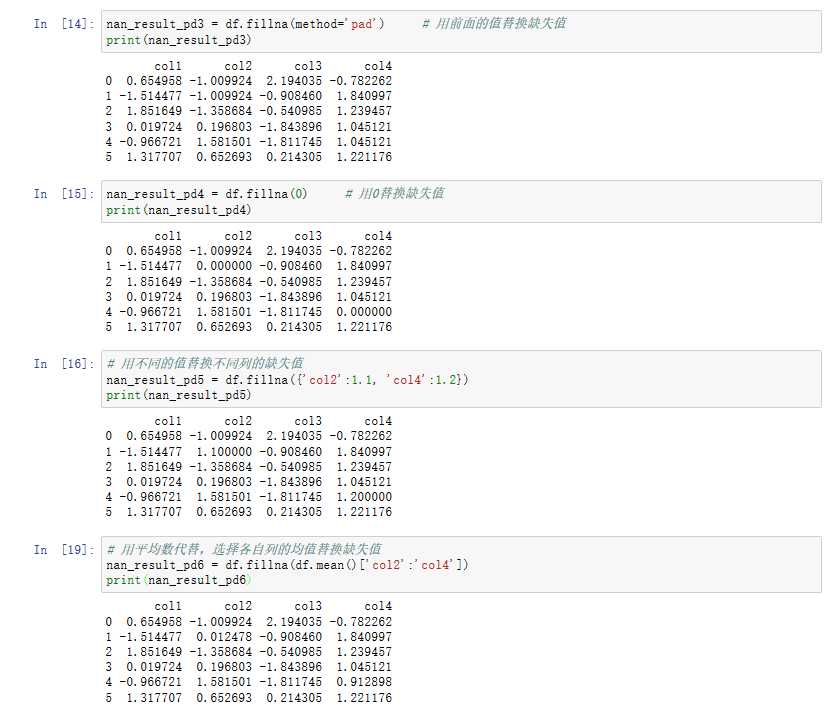
nan_result_pd3 = df.fillna(method=‘pad‘) # 用前面的值替换缺失值
nan_result_pd4 = df.fillna(0) # 用0替换缺失值
nan_result_pd5 = df.fillna({‘col2‘: 1.1, ‘col4‘: 1.2}) # 用不同值替换不同列的缺失值
nan_result_pd6 = df.fillna(df.mean()[‘col2‘:‘col4‘]) # 用平均数代替,选择各自列的均值替换缺失值
# 打印输出
print (nan_result_pd1) # 打印输出
print (nan_result_pd2) # 打印输出
print (nan_result_pd3) # 打印输出
print (nan_result_pd4) # 打印输出
print (nan_result_pd5) # 打印输出
print (nan_result_pd6) # 打印输出
标签:不同 mis ilo imp 特定 form res 支持 tran
原文地址:https://www.cnblogs.com/keye/p/8875941.html