标签:source 消息 否则 客户 特定 分布式应用 这一 ibm 持久化存储
Zookeeper其实是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务。提供分布式锁服务这基本的服务(类似google chubby),同时也支持许多其他的服务,例如配置维护、命名管理、集群管理、组服务、分布式消息队列、分布式通知/协调。
ZooKeeper所提供的服务主要是通过:数据结构(Znode)+原语+watcher机制,三个部分来实现的。
使用ZooKeeper来进行分布式通知和协调能够大大降低系统之间的耦合(使用到了发布/订阅模式)。
数据模型
Zookeeper 会维护一个具有层次关系的数据结构,它非常类似于一个标准的文件系统
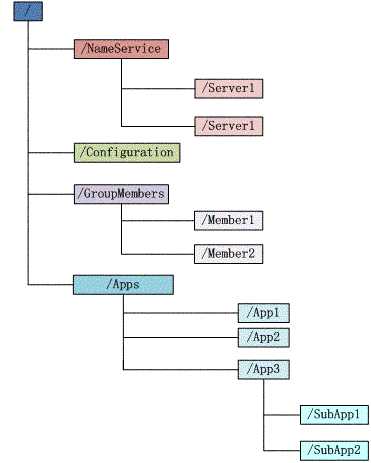
具有如下特点:
节点的类型:
ZooKeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
顺序节点
当创建Znode的时候,用户可以请求在ZooKeeper的路径结尾添加一个递增的计数。这个计数对于此节点的父节点来说是唯一的,它的格式为"%10d"(10位数字,没有数值的数位用0补充,例如"0000000001")。当计数值大于232-1时,计数器将溢出。
监控
客户端可以在节点上设置watch,我们称之为监视器。当节点状态发生改变时(Znode的增、删、改)将会触发watch所对应的操作。当watch被触发时,ZooKeeper将会向客户端发送且仅发送一条通知,因为watch只能被触发一次,这样可以减少网络流量。
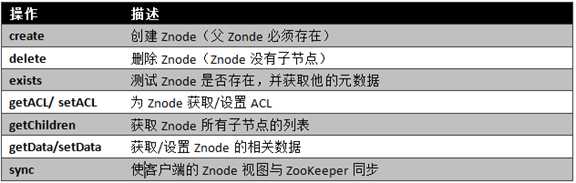
基本操作与实例
在ZooKeeper中有9个基本操作,如下图所示:
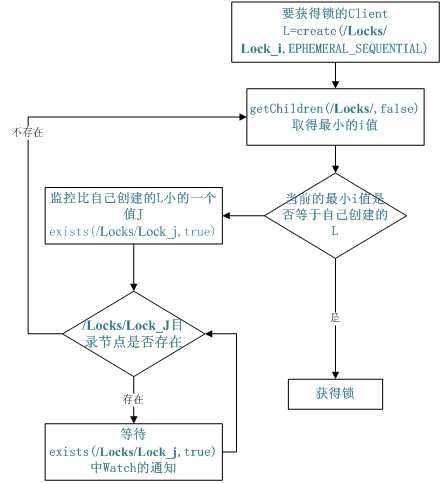
共享锁:
需要获得锁的 Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了。
void getLock() throws KeeperException, InterruptedException{
List<String> list = zk.getChildren(root, false);
String[] nodes = list.toArray(new String[list.size()]);
Arrays.sort(nodes);
if(myZnode.equals(root+"/"+nodes[0])){
doAction();
}
else{
waitForLock(nodes[0]);
}
}
void waitForLock(String lower) throws InterruptedException, KeeperException {
Stat stat = zk.exists(root + "/" + lower,true);
if(stat != null){
mutex.wait();
}
else{
getLock();
}
}
队列管理
Zookeeper 可以处理两种类型的队列:
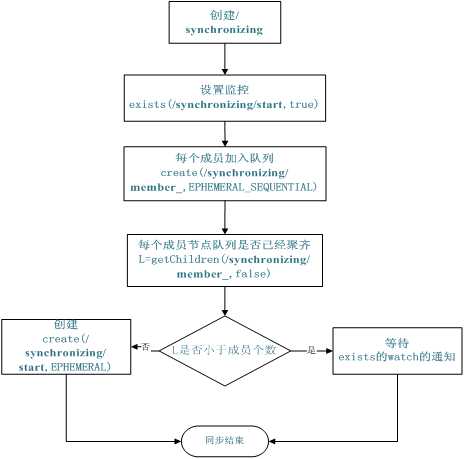
同步队列用 Zookeeper 实现的实现思路如下:
创建一个父目录 /synchronizing,每个成员都监控标志(Set Watch)位目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /synchronizing/member_i 的临时目录节点,然后每个成员获取 / synchronizing 目录的所有目录节点,也就是 member_i。判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start。
void addQueue() throws KeeperException, InterruptedException{
zk.exists(root + "/start",true);
zk.create(root + "/" + name, new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
synchronized (mutex) {
List<String> list = zk.getChildren(root, false);
if (list.size() < size) {
mutex.wait();
} else {
zk.create(root + "/start", new byte[0], Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
}
}
}
当队列没满是进入 wait(),然后会一直等待 Watch 的通知,Watch 的代码如下
public void process(WatchedEvent event) {
if(event.getPath().equals(root + "/start") &&
event.getType() == Event.EventType.NodeCreated){
System.out.println("得到通知");
super.process(event);
doAction();
}
}
参考:https://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/
---------------------------------------------------------------------------------------------------------------------
zab协议
最基本的一致性算法是Paxos,但是存在如下的一些问题:
所以采用zab协议(zookeeper atomic broadcast),ZAB在Paxos算法上做了重要改造,和Paxos有着明显的不同。
唯一id保证:
ZooKeeper事务id(zxid)来标记整体顺序,zxid由周期(epoch)和计数器(counter)组成,各为32位整数,因此zxid也可以记为一个整数对(epoch, count)。epoch的值代表leader的改变,leader对每个提案只是简单地递增zxid以得到一个唯一的zxid值。Leader激活算法会保证只有一个leader使用一个特定的epoch,因此这个简单的算法可以保证每个提案都有一个唯一的id。
法定人数设定:
“法定人数”代表一组服务器,必须满足任意两个法定人数对之间至少有一个共同的服务器。因此典型情况下,任意一个法定人数至少有(n/2+1)台服务器即可满足要求,这里n是ZooKeeper服务中的总服务器数。也有其它的构成法定人数的方法,例如PBFT中是2n/3+1,或者对每台服务器分配投票的权重,最后只需要加权的服务器投票数和超过1/2即可。
follower对于提案的认可:认可意味着服务器已将提案保存到持久化存储上,并且发送ACK。
Leader激活满足的条件:
当且仅当followers中的法定人数(leader也算)与该leader达成同步,即它们有相同的状态。这个状态包含leader认为所有已提交的提案,以及让followers跟随本leader的提案(NEW_LEADER提案)。具体使用什么leader选举算法不关心,只要保证如下两点:
Leader选举完成后一台服务器会被指定为leader并等待followers的连接,其他服务器尝试连接到leader。Leader将和followers同步,通过发送followers缺失的提案(DIFF),但如果followers缺失太多提案,将发送一个完整的快照(SNAP)。
新leader通过获知的最大zxid来确定新的zxid,如前最大zxid的epoch位是e,则leader使用(e+1, 0)作为新的zxid。在leader和follower同步后,leader会发出一个NEW_LEADER提案。一旦NEW_LEADER提案被提交,leader就算完全激活并开始收发其他提案。
具体的策略如下:
消息激活阶段(广播):十分类似于二阶段的提交过程
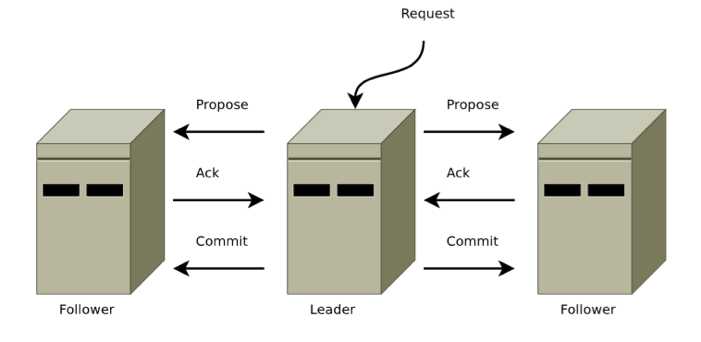
与Paxos的区别:主要在于需要保证所有的proposal的有序
zab与raft的相同点:
参考:https://blog.csdn.net/mayp1/article/details/51871761 https://www.jianshu.com/p/fb527a64deee
--------------------------------------------------------------------------------------
标签:source 消息 否则 客户 特定 分布式应用 这一 ibm 持久化存储
原文地址:https://www.cnblogs.com/zhang-qc/p/8877082.html